爬取佰腾网上的专利信息
声明:全过程没有任何违法操作
概要
目标:爬取佰腾网上的专利信息
目标网址:https://www.baiten.cn/
过程
首先我们打开佰腾网(推荐使用谷歌浏览器,别问我为什么),页面如下图所示
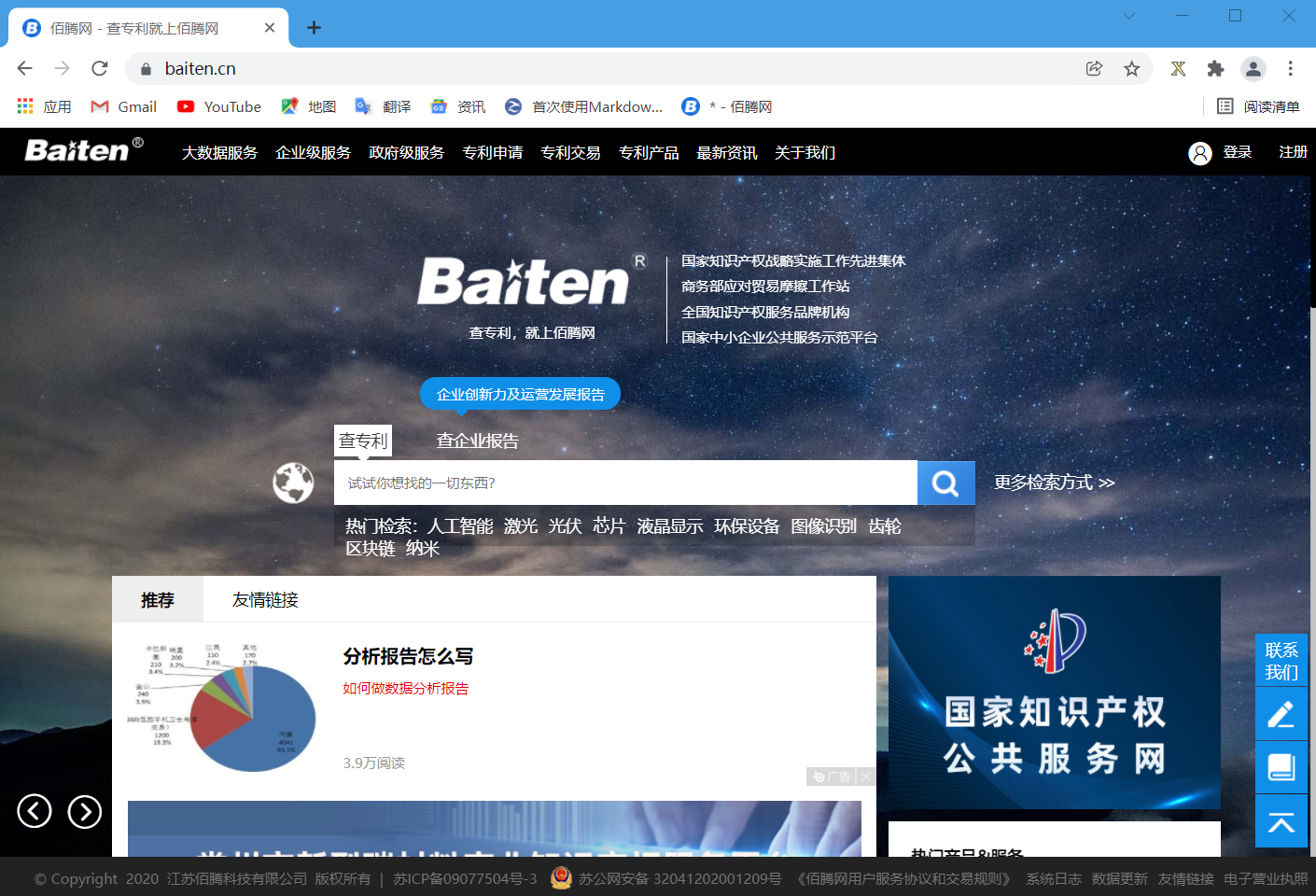
很明显这个网站需要登陆,但是观察这个网站页面,是没有专利展示的,所以我们可以先搜索一类,这里我用java示例。
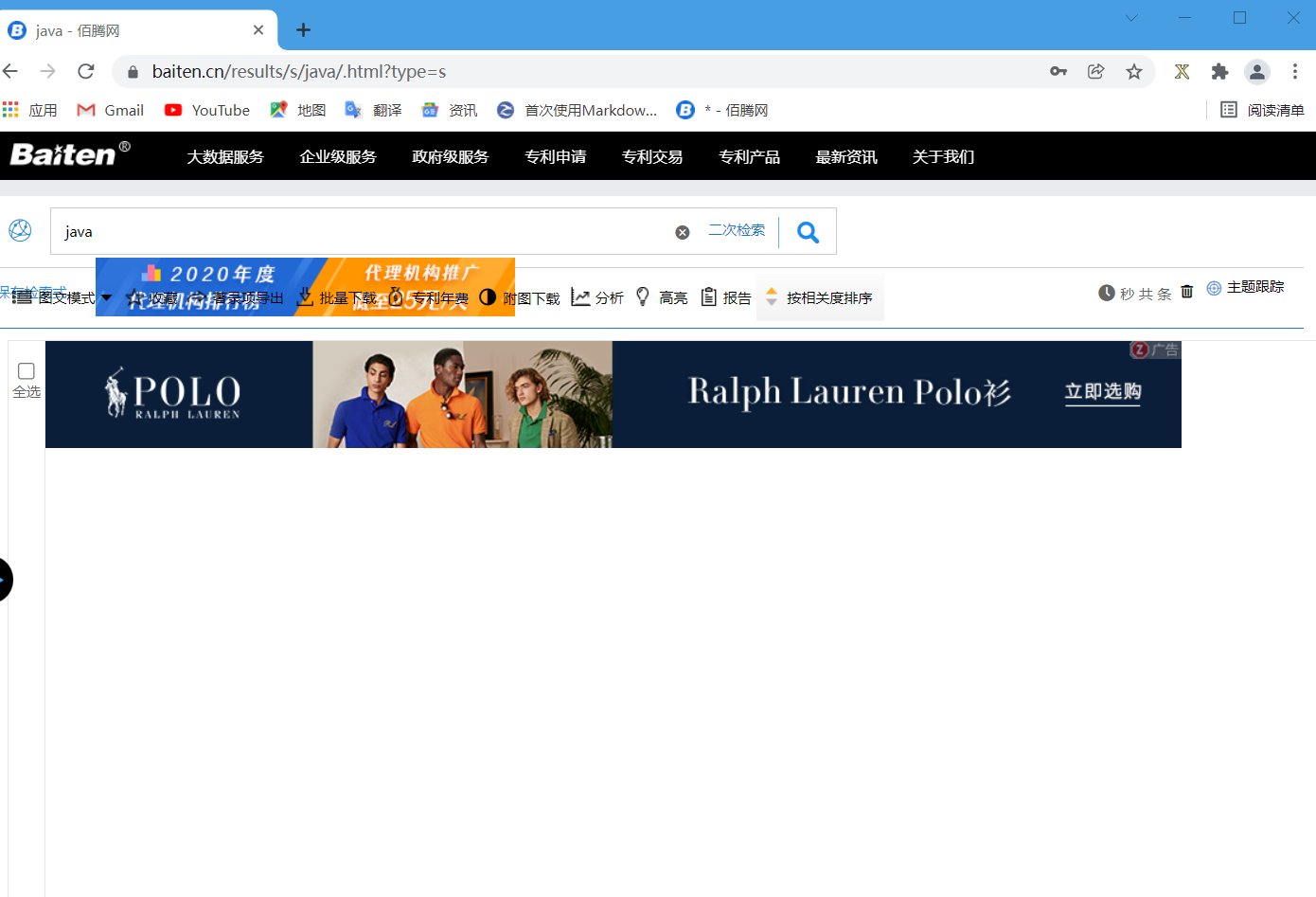
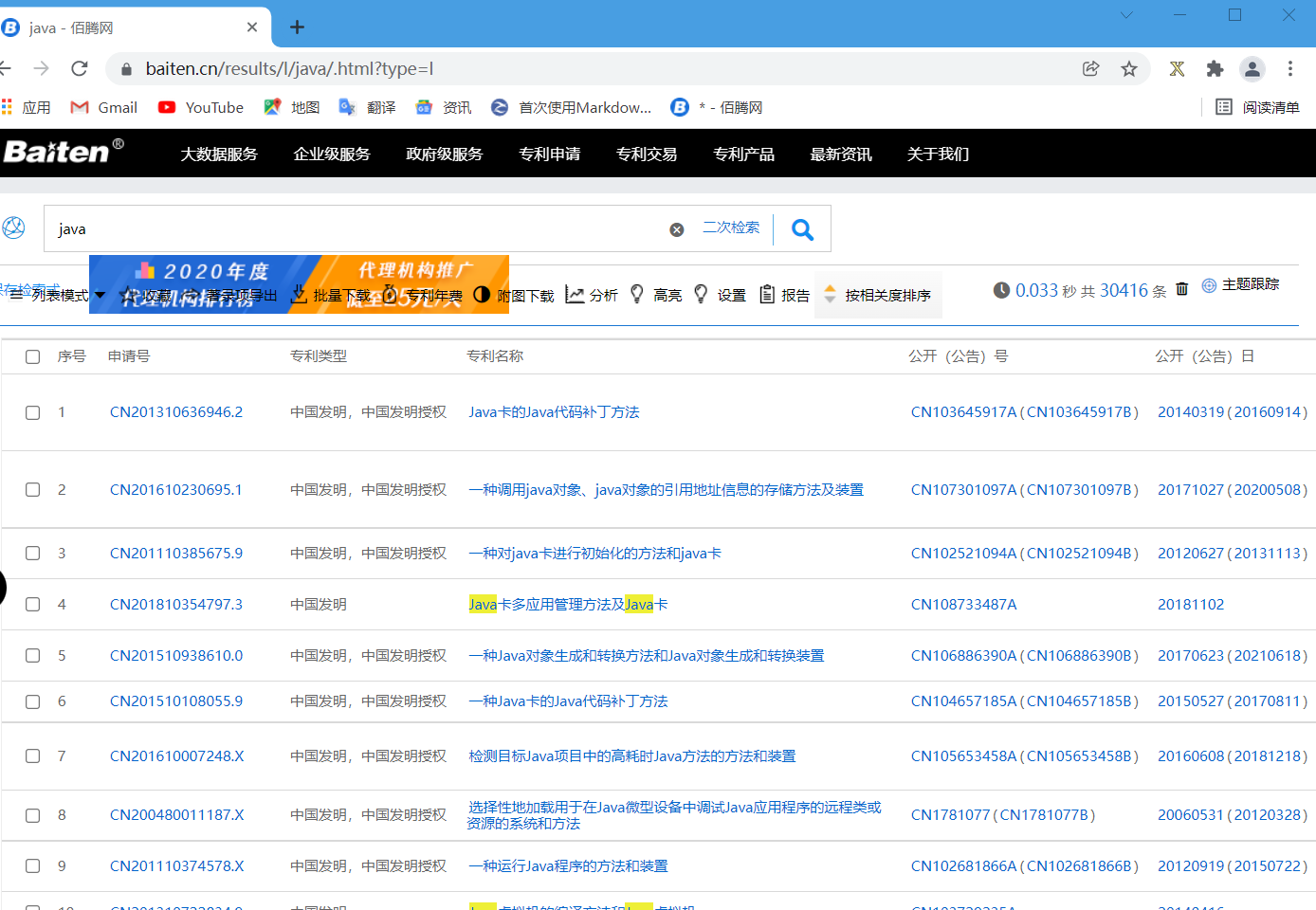
打开这个页面我们会发现依然没有专利展示出来(为了方便操作,我自己开了个账号登录网页),所以我们需要这个网页的Cookie,它能帮我们减少登录操作
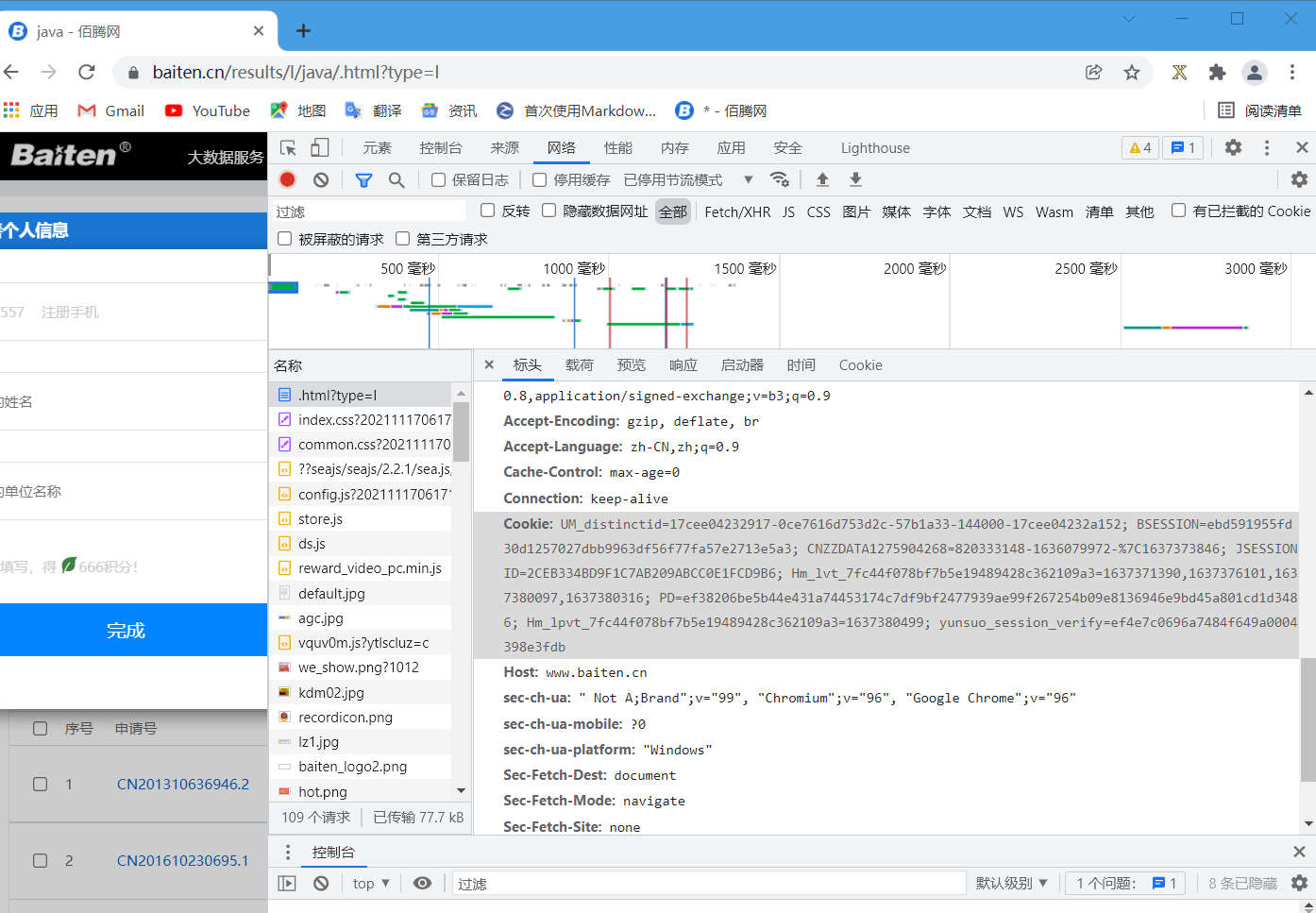
登录后,我们按下F12,找到这个网页请求表头的cookie(注意,这个cookie过一段时间后会改变,所以需要即拿即用)
然后我们创建一个示例1.py文件,用来获取这个网页的页面内容
# 示例1.py代码
import requests
url = 'https://www.baiten.cn/results/l/java/.html?type=l'
headers = {
'Content-Type':'application/x-www-form-urlencoded',
'charset':'UTF-8',
'Host':'www.baiten.cn',
'Referer':'https://www.baiten.cn/results/l/java/.html?type=l',
'Cookie':'UM_distinctid=17cee04232917-0ce7616d753d2c-57b1a33-144000-17cee04232a152; BSESSION=ebd591955fd30d1257027dbb9963df56f77fa57e2713e5a3; CNZZDATA1275904268=820333148-1636079972-|1637373846; JSESSIONID=2CEB334BD9F1C7AB209ABCC0E1FCD9B6; Hm_lvt_7fc44f078bf7b5e19489428c362109a3=1637371390,1637376101,1637380097,1637380316; PD=ef38206be5b44e431a74453174c7df9bf2477939ae99f267254b09e8136946e9bd45a801cd1d3486; Hm_lpvt_7fc44f078bf7b5e19489428c362109a3=1637380570; yunsuo_session_verify=58a343a92e57e07624bb552dd150650c',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36',
'X-Requested-With':'XMLHttpRequest'
}
response = requests.get(url=url, headers=headers).text
print(response)
通过运行代码我们获取到了这个网页的页面内容(如下)
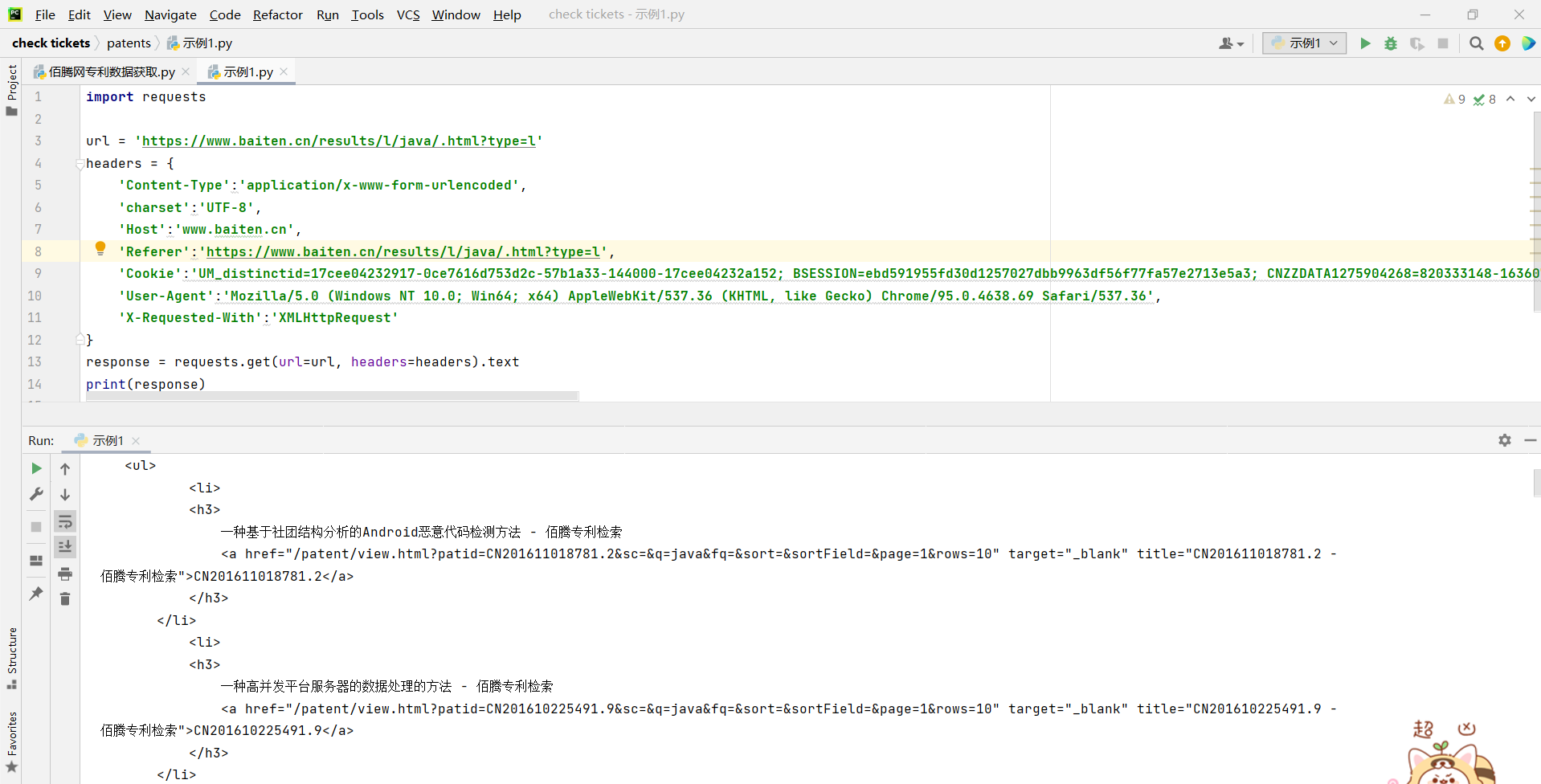
看着这个页面的内容是不是很复杂,所以我们下意识就想要找到表示更简洁的数据内容,这时我们需要了解json格式的文件
JSON(JavaScriptObjectNotation)是一种轻量级的数据交换格式。易于人阅读和编写。同时也易于机器解析和生成。它基于JavaScriptProgrammingLanguage,StandardECMA-2623rdEdition-December1999的一个子集。
如果说更深入的了解的话,json格式的内容相当于python中的一个字典类型,因此json格式的数据通常是多个键与键值绑定在一起的数据。例如:
jsondata = {'name' = 'xxx','age' = 'xxx','address' = 'xxx'}
其中{'name' = 'xxx','age' = 'xxx','address' = 'xxx'}就是json文件中的数据了
一般情况,我们需要在Fetch/XHR栏中找到相应的xhr类型的网址,因为这个网址中包含了这个页面中数据的内容(但注意,一些网站可能会将这些网址设置‘防爬’,比如我将要爬取数据的网站)
我们先点开Fetch/XHR栏,发现一串乱码的网址(如下,注意:经测试,这个乱码会变化)
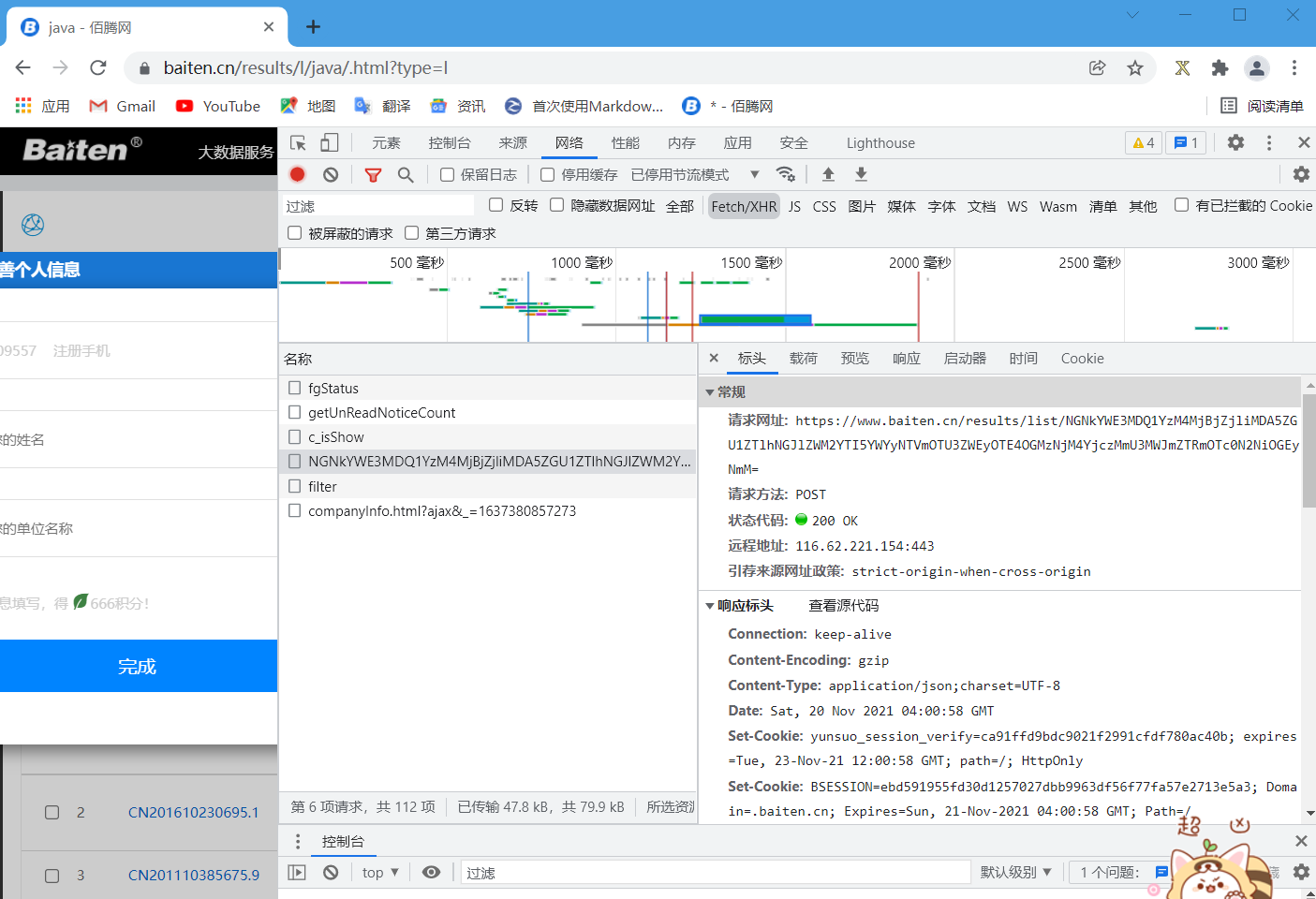
说不定这个网址里就有我们需要的数据,打开一看,页面内容显示405,并且提示我们这个网址不能用get方式申请。但是我们点开前面的载荷,会发现里面有表单数据,因此这网址里绝逼有我们需要的数据,只是我们需要用post方式申请。
因此,我们创建一个示例2.py文件,用于post申请(如下)
# 示例2.py文件代码(注意,代码中的data是该网址的表单数据,必须写完整)
import requests
url = 'https://www.baiten.cn/results/list/NGNkYWE3MDQ1YzM4MjBjZjliMDA5ZGU1ZTlhNGJlZWM2YTI5YWYyNTVmOTU3ZWEyOTE4OGMzNjM4YjczMmU3MWJmZTRmOTc0N2NiOGEyNmM='
data = {
'sc':'',
'q':'java',
'sort':'',
'sortField':'',
'fq':'',
'pageSize':20,
'pageIndex':1,
'type':'l',
'merge':'no-merge'
}
headers = {
'Content-Length':'79',
'Content-Type':'application/x-www-form-urlencoded',
'charset':'UTF-8',
'Host':'www.baiten.cn',
'Origin':'https://www.baiten.cn',
'Referer':'https://www.baiten.cn/results/l/java/.html?type=l',
'Cookie':'UM_distinctid=17cee04232917-0ce7616d753d2c-57b1a33-144000-17cee04232a152; BSESSION=ebd591955fd30d1257027dbb9963df56f77fa57e2713e5a3; CNZZDATA1275904268=820333148-1636079972-|1637373846; JSESSIONID=2CEB334BD9F1C7AB209ABCC0E1FCD9B6; Hm_lvt_7fc44f078bf7b5e19489428c362109a3=1637371390,1637376101,1637380097,1637380316; PD=ef38206be5b44e431a74453174c7df9bf2477939ae99f267254b09e8136946e9bd45a801cd1d3486; yunsuo_session_verify=58a343a92e57e07624bb552dd150650c; Hm_lpvt_7fc44f078bf7b5e19489428c362109a3=1637380857',
'sec-ch-ua-mobile':'?0',
'sec-ch-ua-platform':'Windows',
'Sec-Fetch-Dest':'empty',
'Sec-Fetch-Mode':'cors',
'Sec-Fetch-Site':'same-origin',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36',
'X-Requested-With':'XMLHttpRequest'
}
requests1 = requests.post(url, headers=headers, data=data).json()
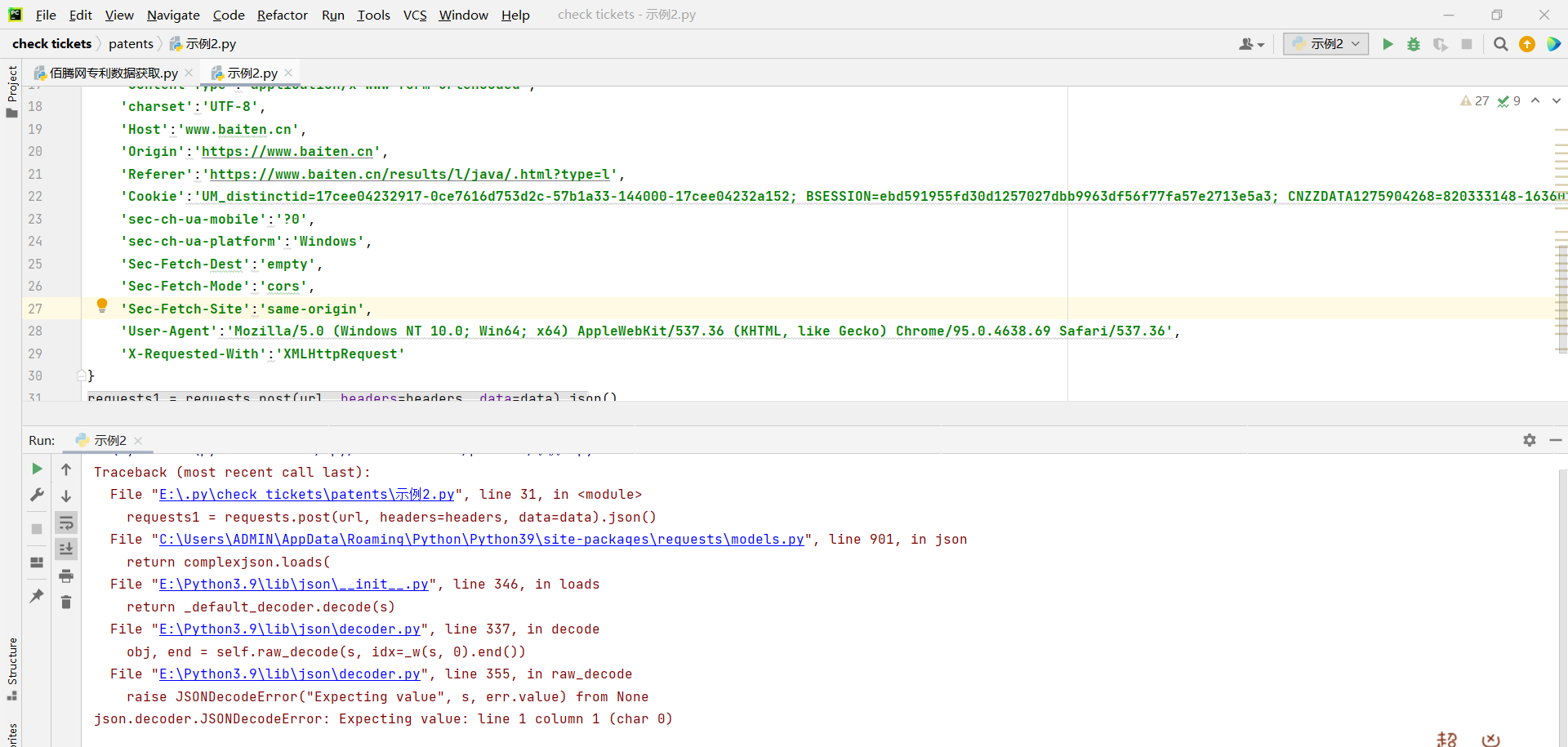
结果代码报错,说明这里返回的数据可能不是json数据,我们在将json()改为text来获取页面内容
得到了PT_Offline_Login的内容,说明我们使用的cookie可能过期了,我再次更换了新的cookie后,得到的结果是“非法操作”
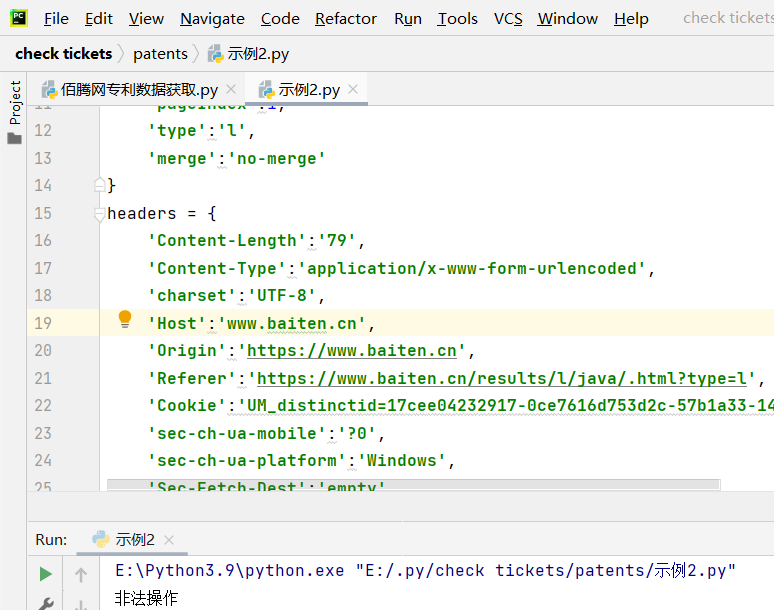
当我再一次刷新页面时,我发现这个申请头地址改变了,所以猫腻一定就在这个申请头后面的乱码上了。
果然,当我在这个网站上寻找相关的信息时,我找到一个网址,里面正好有与非法操作相关的内容
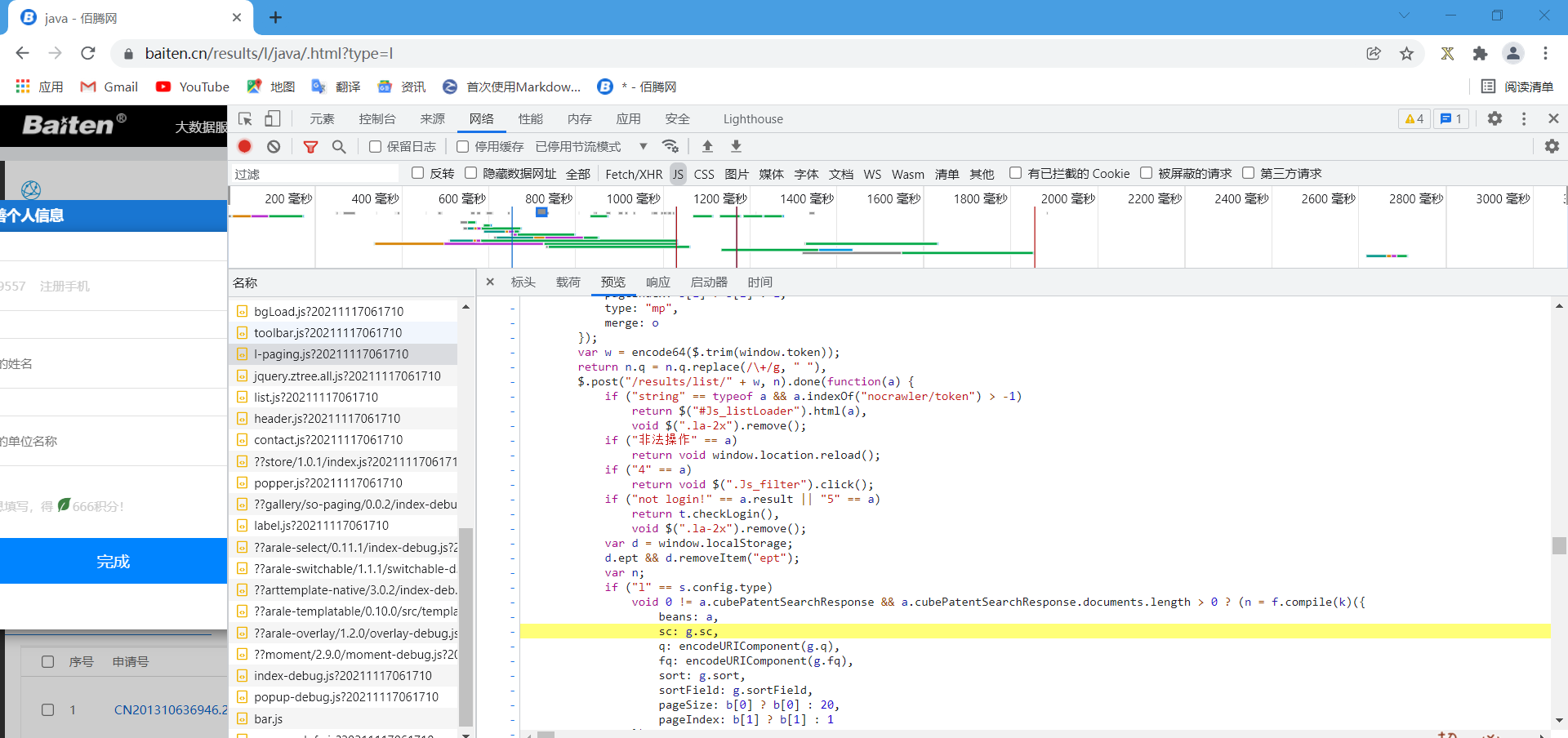
观察这一段代码,发现应该是网站使用了encode64函数加密了window.token变量,说不定这个变量加密的结果就是那一串乱码,所以我们还需要找到加密方法encode64,果然,我在另一个网站中找到了加密方法
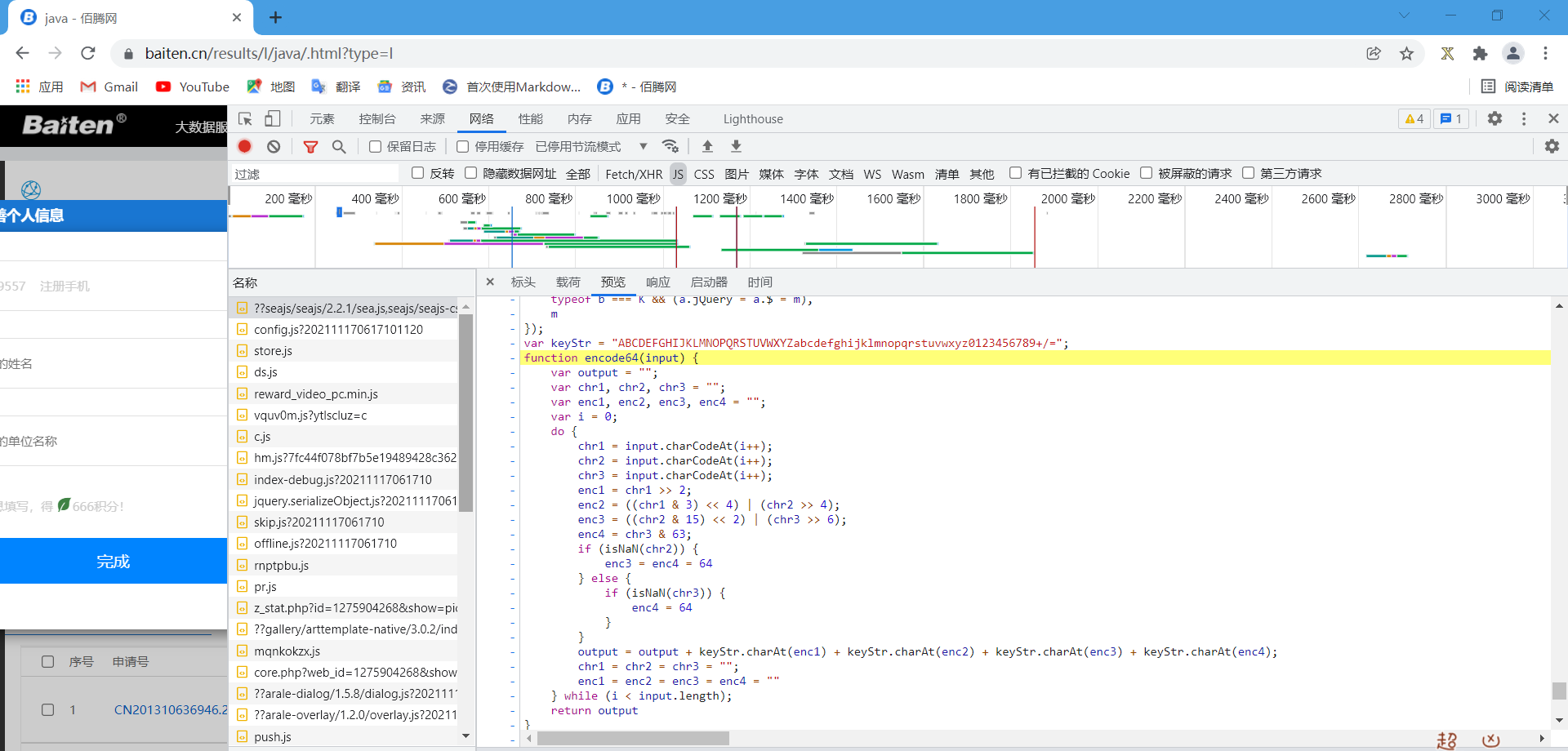
我们在python中运行一下这段代码(需要安装execjs模块来实现)
创建示例3.py文件实现加密方法
# 示例3.py代码
import execjs
ctx1 = execjs.compile("""
var keyStr = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=";
function encode64(input) {
var output = "";
var chr1, chr2, chr3 = "";
var enc1, enc2, enc3, enc4 = "";
var i = 0;
do {
chr1 = input.charCodeAt(i++);
chr2 = input.charCodeAt(i++);
chr3 = input.charCodeAt(i++);
enc1 = chr1 >> 2;
enc2 = ((chr1 & 3) << 4) | (chr2 >> 4);
enc3 = ((chr2 & 15) << 2) | (chr3 >> 6);
enc4 = chr3 & 63;
if (isNaN(chr2)) {
enc3 = enc4 = 64
} else {
if (isNaN(chr3)) {
enc4 = 64
}
}
output = output + keyStr.charAt(enc1) + keyStr.charAt(enc2) + keyStr.charAt(enc3) + keyStr.charAt(enc4);
chr1 = chr2 = chr3 = "";
enc1 = enc2 = enc3 = enc4 = ""
} while (i < input.length);
return output;
}
""")
print(ctx1.call("encode64", 'hasbdkjg8923876ajsbdahsd7a68ds7sa786d7aufkasd'))
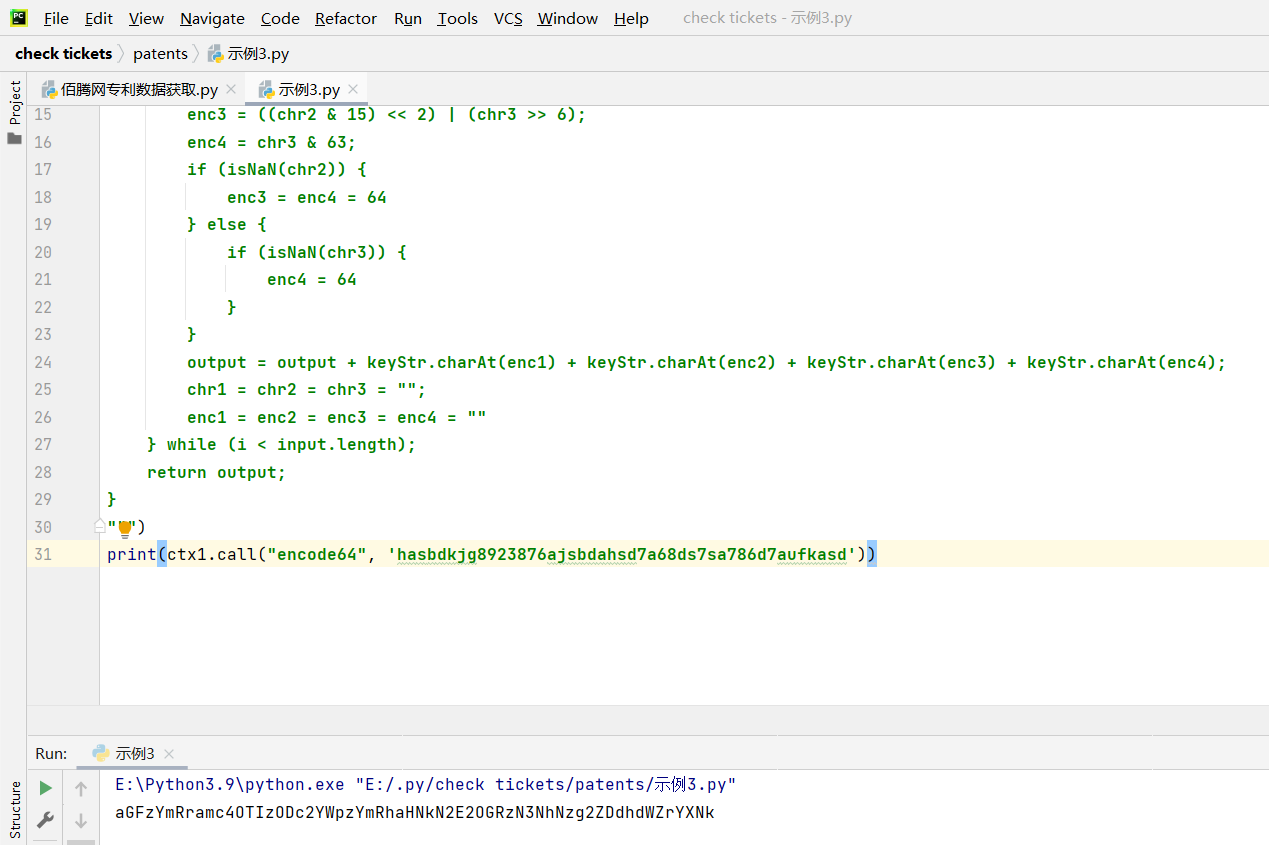
加密功能实现
然后我们只需要找到window.token这个变量就ok了。回到示例1,运行代码得到请求网页的内容,然后在内容中果然能发现这个变量,而且这个变量显示的位置不变,且每次一刷新,这个变量每次都会改变
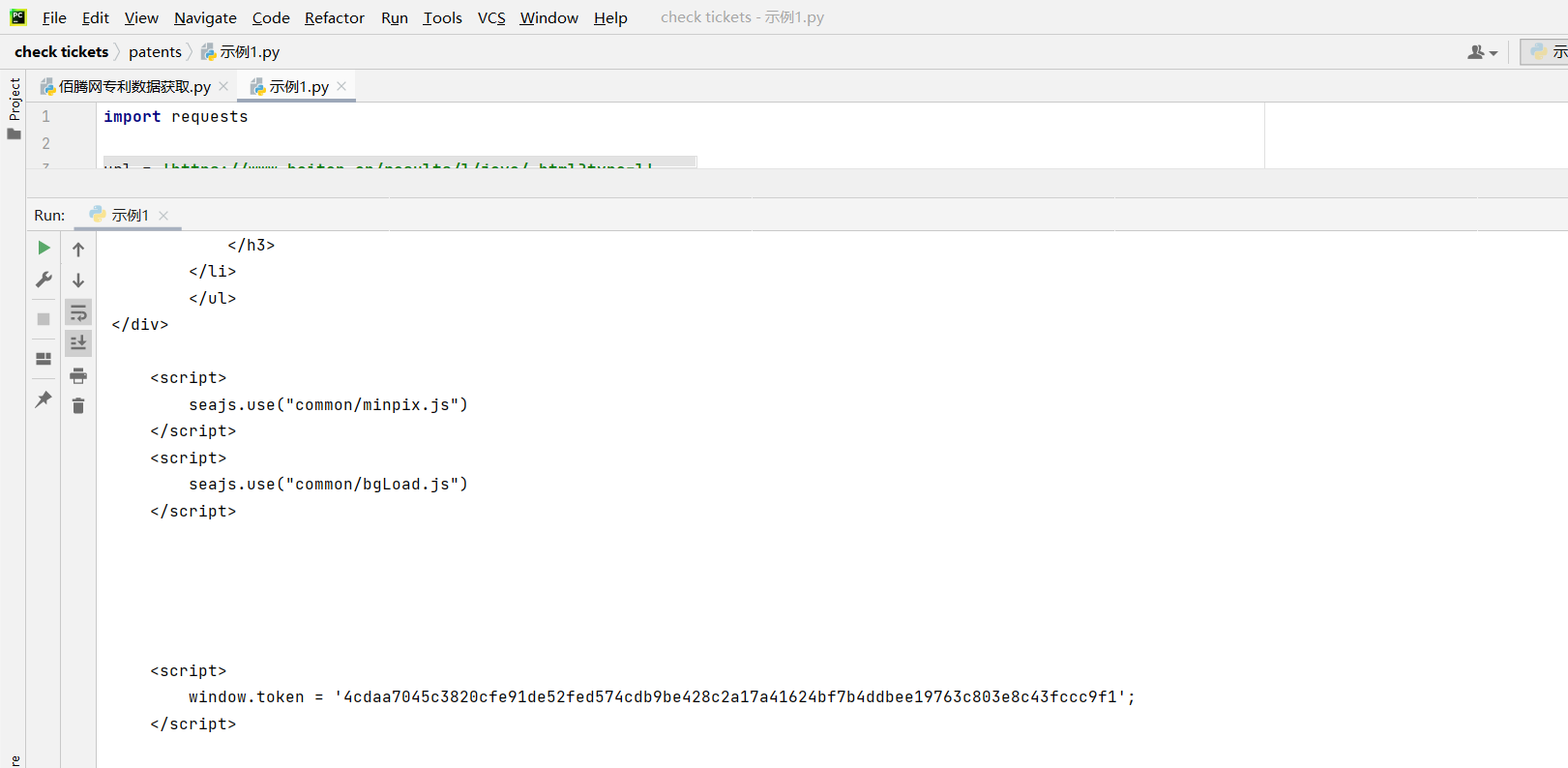
然后我们提取这个window.token,再填写到加密方法中,发现加密过后的内容果然是那串乱码。到这里位置,我们就可以实现爬取佰腾网专利数据了
实现代码(注意cookie隔一段时间会失效)
import requests
import execjs
pageSize = int(input('pageSize(不要大于100):'))
pageIndex = int(input('pageIndex(尽量小点):'))
# 获取到申请头网址的html页面数据
url = 'https://www.baiten.cn/results/l/java/.html?type=l'
headers = {
'Content-Type':'application/x-www-form-urlencoded',
'charset':'UTF-8',
'Host':'www.baiten.cn',
'Referer':'https://www.baiten.cn/results/l/java/.html?type=l',
'Cookie':'UM_distinctid=17cee04232917-0ce7616d753d2c-57b1a33-144000-17cee04232a152; BSESSION=ebd591955fd30d1257027dbb9963df56f77fa57e2713e5a3; CNZZDATA1275904268=820333148-1636079972-|1637373846; JSESSIONID=DB3783395EF3493A6442823BB3B78D64; Hm_lvt_7fc44f078bf7b5e19489428c362109a3=1637240043,1637284980,1637371390,1637376101; PD=e93016ff6f0fe59581642611bf9938c051020e206df9821a71254bbb888e02a4b29a183d16a1bf5e; Hm_lpvt_7fc44f078bf7b5e19489428c362109a3=1637376109; yunsuo_session_verify=ef4e7c0696a7484f649a0004398e3fdb',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36',
'X-Requested-With':'XMLHttpRequest'
}
response = requests.get(url=url, headers=headers).text
str = response
# 获取到被加密的数据token
token = ''
for i in range(5568, 5648):
token = token + str[i]
# 利用execjs模块对获取到的token进行加密
ctx1 = execjs.compile("""
var keyStr = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=";
function encode64(input) {
var output = "";
var chr1, chr2, chr3 = "";
var enc1, enc2, enc3, enc4 = "";
var i = 0;
do {
chr1 = input.charCodeAt(i++);
chr2 = input.charCodeAt(i++);
chr3 = input.charCodeAt(i++);
enc1 = chr1 >> 2;
enc2 = ((chr1 & 3) << 4) | (chr2 >> 4);
enc3 = ((chr2 & 15) << 2) | (chr3 >> 6);
enc4 = chr3 & 63;
if (isNaN(chr2)) {
enc3 = enc4 = 64
} else {
if (isNaN(chr3)) {
enc4 = 64
}
}
output = output + keyStr.charAt(enc1) + keyStr.charAt(enc2) + keyStr.charAt(enc3) + keyStr.charAt(enc4);
chr1 = chr2 = chr3 = "";
enc1 = enc2 = enc3 = enc4 = ""
} while (i < input.length);
return output;
}
""")
ctx1.call("encode64", token)
# 获取加密网站https://www.baiten.cn/results/list/token
url1 = ''
str1 = 'https://www.baiten.cn/results/list/'
str2 = ctx1.call("encode64", token)
url1 = url1 + str1 + str2
# 爬取到被加密的网站上专利的数据
url2 = url1
data = {
'sc':'',
'q':'java',
'sort':'',
'sortField':'',
'fq':'',
'pageSize':pageSize,
'pageIndex':pageIndex,
'type':'l',
'merge':'no-merge'
}
headers = {
'Content-Length':'79',
'Content-Type':'application/x-www-form-urlencoded',
'charset':'UTF-8',
'Host':'www.baiten.cn',
'Origin':'https://www.baiten.cn',
'Referer':'https://www.baiten.cn/results/l/java/.html?type=l',
'Cookie':'UM_distinctid=17cee04232917-0ce7616d753d2c-57b1a33-144000-17cee04232a152; BSESSION=ebd591955fd30d1257027dbb9963df56f77fa57e2713e5a3; CNZZDATA1275904268=820333148-1636079972-|1637373846; JSESSIONID=DB3783395EF3493A6442823BB3B78D64; Hm_lvt_7fc44f078bf7b5e19489428c362109a3=1637240043,1637284980,1637371390,1637376101; PD=e93016ff6f0fe59581642611bf9938c051020e206df9821a71254bbb888e02a4b29a183d16a1bf5e; Hm_lpvt_7fc44f078bf7b5e19489428c362109a3=1637376109; yunsuo_session_verify=ef4e7c0696a7484f649a0004398e3fdb',
'sec-ch-ua-mobile':'?0',
'sec-ch-ua-platform':'Windows',
'Sec-Fetch-Dest':'empty',
'Sec-Fetch-Mode':'cors',
'Sec-Fetch-Site':'same-origin',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36',
'X-Requested-With':'XMLHttpRequest'
}
requests1 = requests.post(url2, headers=headers, data=data).json()
result = requests1['cubePatentSearchResponse']['documents']
patentdata = open('data.txt', 'w+')
patentdata.write('第')
patentdata.write('%d' %pageIndex)
patentdata.write('页的专利产品' + '\n')
i = 0
while i < pageSize:
result = requests1['cubePatentSearchResponse']['documents'][i]['field_values']
ti = result['ti'] # 专利名称
id = result['id'] # 申请号
pn = result['pn'] # 公开号
pa = result['pa'] # 申请(专利权)人是个列表
str_pa = ''
for m1 in pa:
str_pa = str_pa + ' ' + m1
In = result['in'] # 发明人是个列表
str_in = ''
for m2 in pa:
str_in = str_in + ' ' + m2
ad = result['ad'] # 申请日
pd = result['pd'] # 公开日
ic1 = result['ic1'] # 主分类号
aic1 = result['aic1'] # 分类号
aa = result['aa'] # 地址
co = result['co'] # 国省代码
kw = result['kw'] # 技术关键词
str_kw = ''
for m3 in kw:
str_kw = str_kw + ' ' + m3
ls1 = result['ls1'] # 专利授权情况
ab = result['ab'] # 摘要
ac = result['ac'] # 学术搜索
num = i+1
patentdata.write('第')
patentdata.write('%d' %num)
patentdata.write('个专利产品' + '\n')
patentdata.write('专利名称:' + ti + '\n')
patentdata.write('申请号:' + id + '\n')
patentdata.write('公开号:' + pn + '\n')
patentdata.write('申请(专利权)人:' + str_pa + '\n')
patentdata.write('发明人:' + str_in + '\n')
patentdata.write('申请日:' + ad + '\n')
patentdata.write('公开日:' + pd + '\n')
patentdata.write('主分类号:' + ic1 + '\n')
patentdata.write('分类号:' + aic1 + '\n')
patentdata.write('地址:' + aa + '\n')
patentdata.write('国省代码:' + co + '\n')
patentdata.write('技术关键词:' + str_kw + '\n')
patentdata.write('专利授权情况:' + ls1 + '\n')
patentdata.write('摘要:' + ab + '\n')
patentdata.write('学术搜索:' + ac + '\n')
i += 1
else:
print("数据获取完毕!")
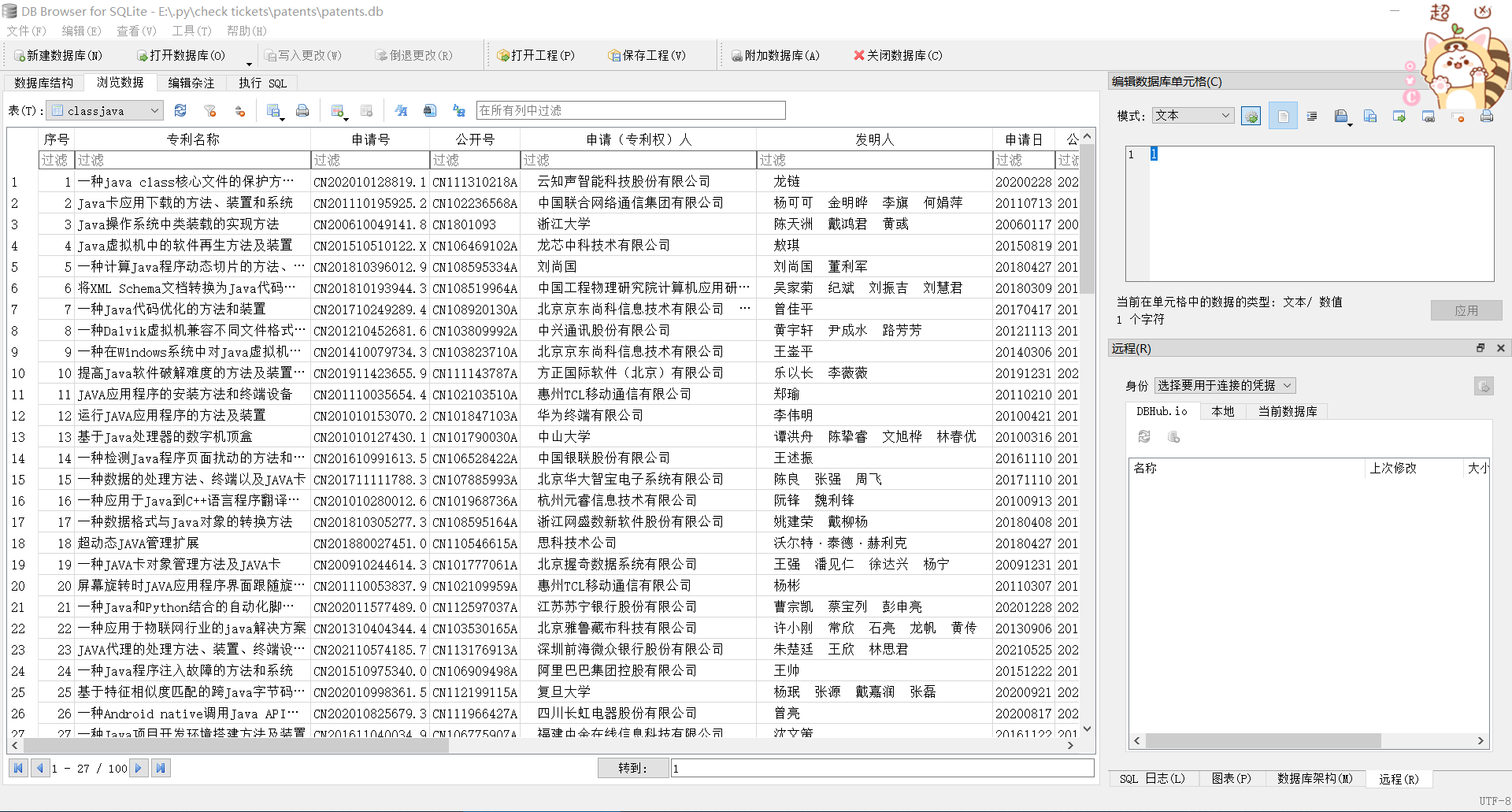
爬取效果(这里我们以第3页每页100个专利的设定爬取有关java的专利)
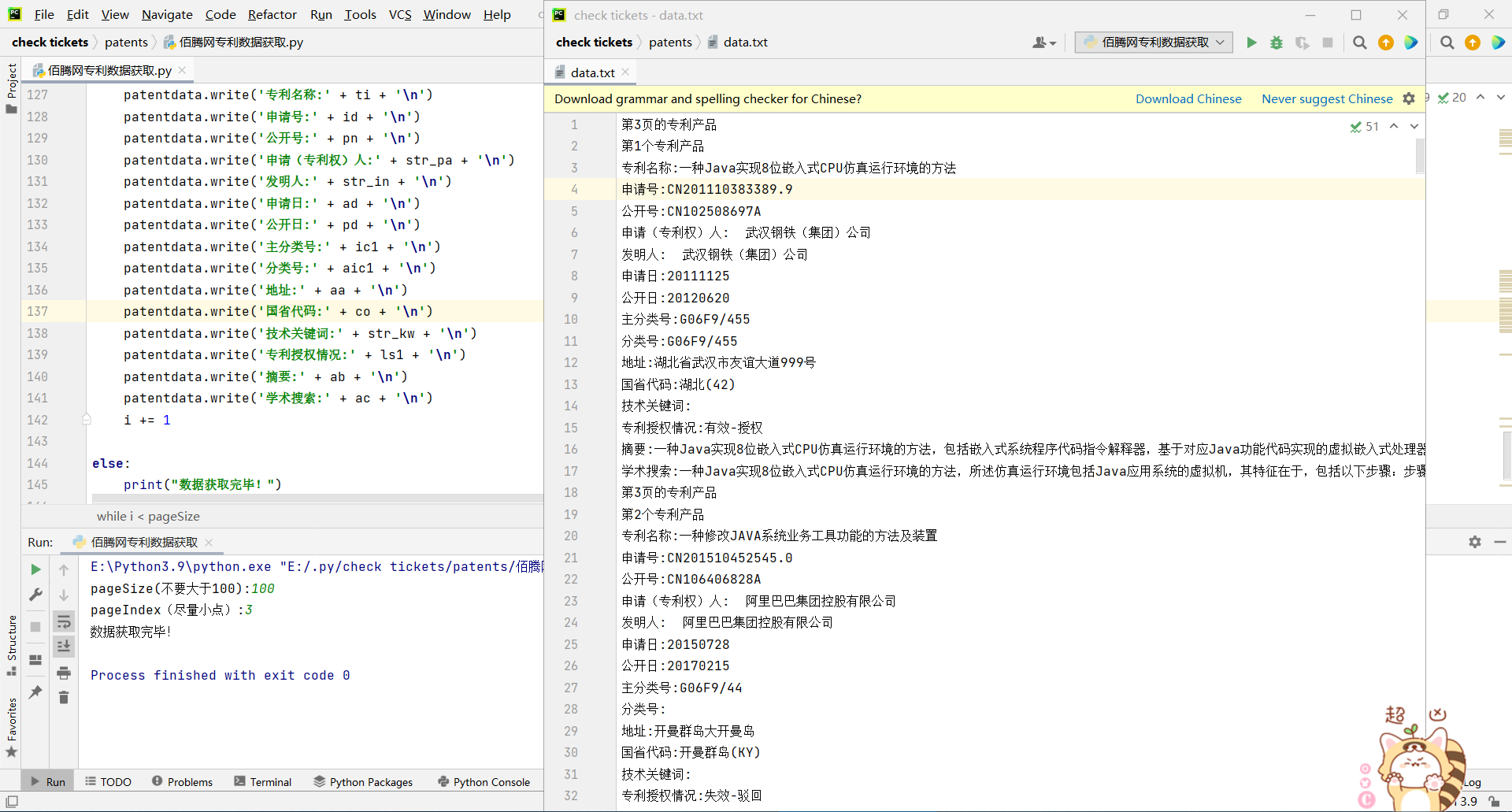
当然,我们也可以爬取其他类的专利,只需要修改相关代码和cookie就可以实现了,但是最最最重要的一点就是cookie是会失效的。
这里附上码云链接
感受
为了实现这个目标,我除了自学爬虫外,关于网页的很多知识都向我哥请教过,我也因此知道了很多比如html格式,json格式以及异步加载等等。给我最大的感受,那还是学习我们这块专业的人,就应当有终生学习的理念。
更新(添加注入SQL数据库和更新数据的功能)
代码实现如下
# 注入数据
def savadatatosql():
con = sqlite3.connect('patents.db')
cursor = con.cursor()
i = 0
while i < pageSize:
result = requests1['cubePatentSearchResponse']['documents'][i]['field_values']
i_ti = result['ti'] # 专利名称
i_id = result['id'] # 申请号
i_pn = result['pn'] # 公开号
i_pa = result['pa'] # 申请(专利权)人是个列表
i_str_pa = ''
for m1 in i_pa:
i_str_pa = i_str_pa + ' ' + m1
i_in = result['in'] # 发明人是个列表
i_str_in = ''
for m2 in i_in:
i_str_in = i_str_in + ' ' + m2
i_ad = result['ad'] # 申请日
i_pd = result['pd'] # 公开日
i_ic1 = result['ic1'] # 主分类号
i_aic1 = result['aic1'] # 分类号
i_aa = result['aa'] # 地址
i_co = result['co'] # 国省代码
i_kw = result['kw'] # 技术关键词
i_str_kw = ''
for m3 in i_kw:
i_str_kw = i_str_kw + ' ' + m3
i_ls1 = result['ls1'] # 专利授权情况
i_ab = result['ab'] # 摘要
i_ac = result['ac'] # 学术搜索
sql = 'INSERT INTO classjava (专利名称, 申请号, 公开号, 申请(专利权)人, 发明人, 申请日, 公开日, 主分类号, 分类号, 地址, 国省代码, 技术关键词, 专利授权情况, 摘要, 学术搜索) VALUES (?,?,?,?,?,?,?,?,?,?,?,?,?,?,?)'
cursor.execute(sql, [i_ti, i_id, i_pn, i_str_pa, i_str_in, i_ad, i_pd, i_ic1, i_aic1, i_aa, i_co, i_str_kw, i_ls1, i_ab, i_ac])
con.commit()
print("第{}条数据获取成功。".format(i+1))
i += 1
time.sleep(0.5)
else:
cursor.close()
con.close()
print("数据获取完毕!")
# 更新数据
def dataupdate():
con = sqlite3.connect('patents.db')
cursor = con.cursor()
i = 0
while i < pageSize:
result = requests1['cubePatentSearchResponse']['documents'][i]['field_values']
i_ti = result['ti'] # 专利名称
i_id = result['id'] # 申请号
i_pn = result['pn'] # 公开号
i_pa = result['pa'] # 申请(专利权)人是个列表
i_str_pa = ''
for m1 in i_pa:
i_str_pa = i_str_pa + ' ' + m1
i_in = result['in'] # 发明人是个列表
i_str_in = ''
for m2 in i_in:
i_str_in = i_str_in + ' ' + m2
i_ad = result['ad'] # 申请日
i_pd = result['pd'] # 公开日
i_ic1 = result['ic1'] # 主分类号
i_aic1 = result['aic1'] # 分类号
i_aa = result['aa'] # 地址
i_co = result['co'] # 国省代码
i_kw = result['kw'] # 技术关键词
i_str_kw = ''
for m3 in i_kw:
i_str_kw = i_str_kw + ' ' + m3
i_ls1 = result['ls1'] # 专利授权情况
i_ab = result['ab'] # 摘要
i_ac = result['ac'] # 学术搜索
sql = 'UPDATE classjava SET 专利名称=?, 申请号=?, 公开号=?, 申请(专利权)人=?, 发明人=?, 申请日=?, 公开日=?, 主分类号=?, 分类号=?, 地址=?, 国省代码=?, 技术关键词=?, 专利授权情况=?, 摘要=?, 学术搜索=? WHERE 序号=?'
cursor.execute(sql, [i_ti, i_id, i_pn, i_str_pa, i_str_in, i_ad, i_pd, i_ic1, i_aic1, i_aa, i_co, i_str_kw, i_ls1, i_ab, i_ac, i+1])
con.commit()
print("第{}条数据更新成功。".format(i+1))
i += 1
time.sleep(0.5)
else:
cursor.close()
con.close()
print("数据更新完毕!")
print("操作:" + '\n' + '1.获取数据(如果已经获取了数据,请不要使用此操作)' + '\n' + '2.更新数据')
operation = int(input('请输入你需要执行的操作的数字代号:'))
if operation == 1:
savadatatosql()
elif operation == 2:
dataupdate()
else:
print('操作无效,程序终止')
代码实现效果
更新前

开始更新
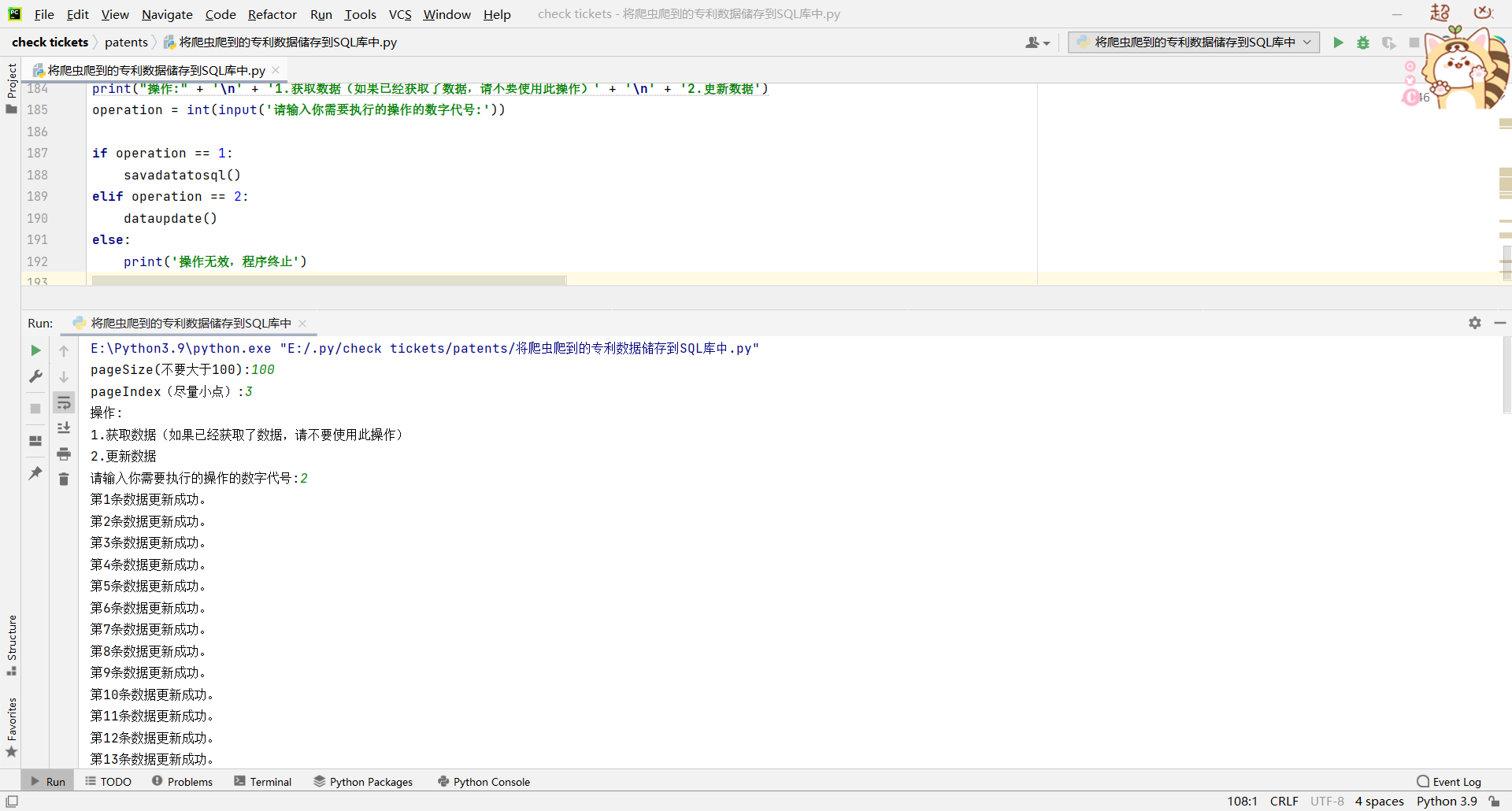
更新完毕(解释一下这里为什么数据是一样的,因为我没有关闭数据库导致数据无法更新,需要重新关闭后再打开才能更新数据,这里是我本人的一个小失误)
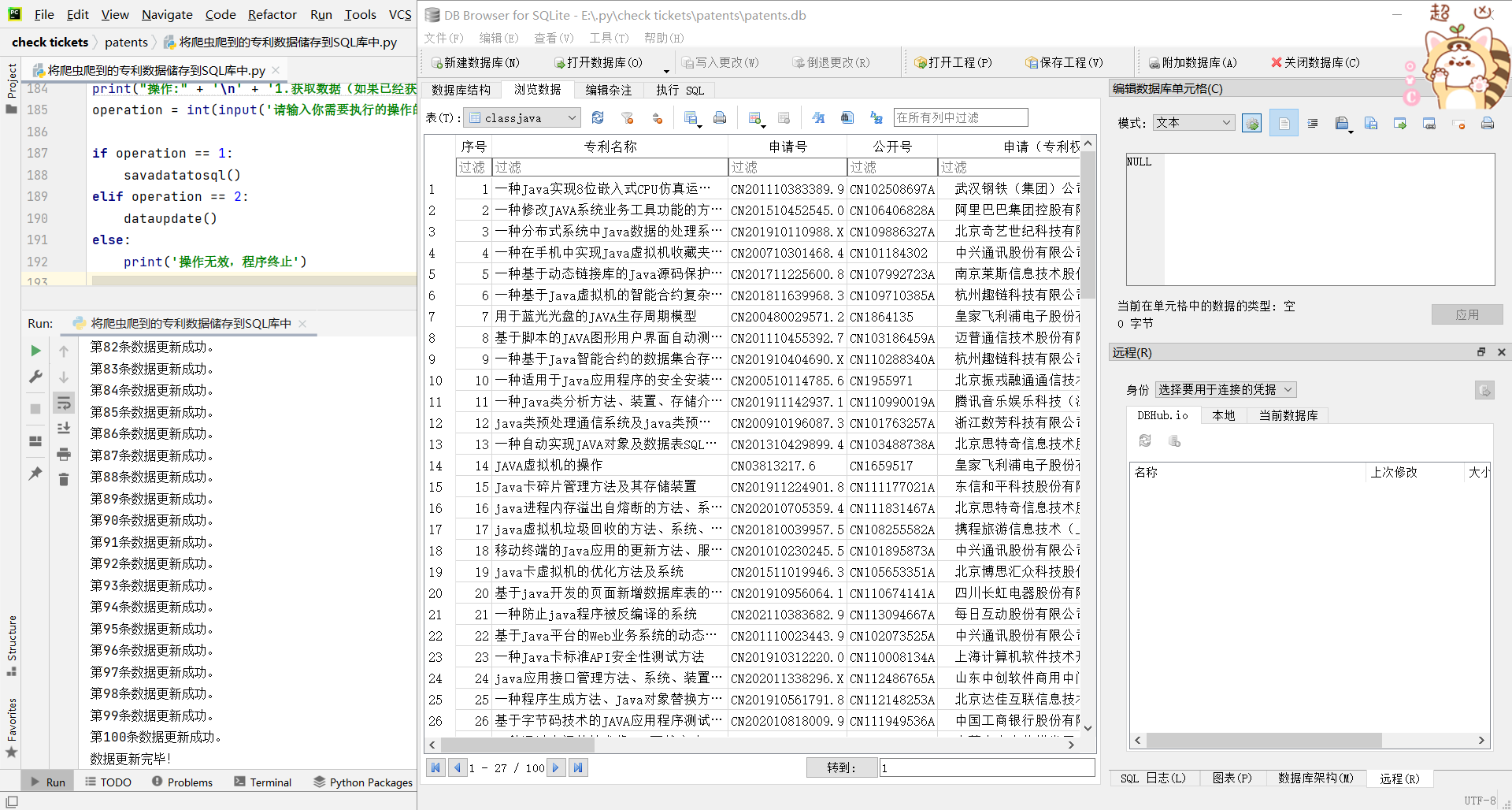
当然,在我设计的时候我发现上面的代码不够简洁,所以我将代码改得更加简洁了一点,如下
def datatosql():
con = sqlite3.connect('patents.db')
cursor = con.cursor()
i = 0
print("操作:" + '\n' + '1.获取数据(如果已经获取了数据,请不要使用此操作)' + '\n' + '2.更新数据')
operation = int(input('请输入你需要执行的操作的数字代号:'))
while i < pageSize:
result = requests1['cubePatentSearchResponse']['documents'][i]['field_values']
i_ti = result['ti'] # 专利名称
i_id = result['id'] # 申请号
i_pn = result['pn'] # 公开号
i_pa = result['pa'] # 申请(专利权)人是个列表
i_str_pa = ''
for m1 in i_pa:
i_str_pa = i_str_pa + ' ' + m1
i_in = result['in'] # 发明人是个列表
i_str_in = ''
for m2 in i_in:
i_str_in = i_str_in + ' ' + m2
i_ad = result['ad'] # 申请日
i_pd = result['pd'] # 公开日
i_ic1 = result['ic1'] # 主分类号
i_aic1 = result['aic1'] # 分类号
i_aa = result['aa'] # 地址
i_co = result['co'] # 国省代码
i_kw = result['kw'] # 技术关键词
i_str_kw = ''
for m3 in i_kw:
i_str_kw = i_str_kw + ' ' + m3
i_ls1 = result['ls1'] # 专利授权情况
i_ab = result['ab'] # 摘要
i_ac = result['ac'] # 学术搜索
# 注入数据
if operation == 1:
sql = 'INSERT INTO classjava (专利名称, 申请号, 公开号, 申请(专利权)人, 发明人, 申请日, 公开日, 主分类号, 分类号, 地址, 国省代码, 技术关键词, 专利授权情况, 摘要, 学术搜索) VALUES (?,?,?,?,?,?,?,?,?,?,?,?,?,?,?)'
cursor.execute(sql, [i_ti, i_id, i_pn, i_str_pa, i_str_in, i_ad, i_pd, i_ic1, i_aic1, i_aa, i_co, i_str_kw,
i_ls1, i_ab, i_ac])
con.commit()
print("第{}条数据获取成功。".format(i + 1))
i += 1
time.sleep(0.5)
elif operation == 2:
sql = 'UPDATE classjava SET 专利名称=?, 申请号=?, 公开号=?, 申请(专利权)人=?, 发明人=?, 申请日=?, 公开日=?, 主分类号=?, 分类号=?, 地址=?, 国省代码=?, 技术关键词=?, 专利授权情况=?, 摘要=?, 学术搜索=? WHERE 序号=?'
cursor.execute(sql, [i_ti, i_id, i_pn, i_str_pa, i_str_in, i_ad, i_pd, i_ic1, i_aic1, i_aa, i_co, i_str_kw,
i_ls1, i_ab, i_ac, i + 1])
con.commit()
print("第{}条数据更新成功。".format(i + 1))
i += 1
time.sleep(0.5)
else:
print('操作无效,程序终止')
break
if operation == 1:
cursor.close()
con.close()
print("数据获取完毕!")
elif operation == 2:
cursor.close()
con.close()
print("数据更新完毕!")
datatosql()
运行效果如下
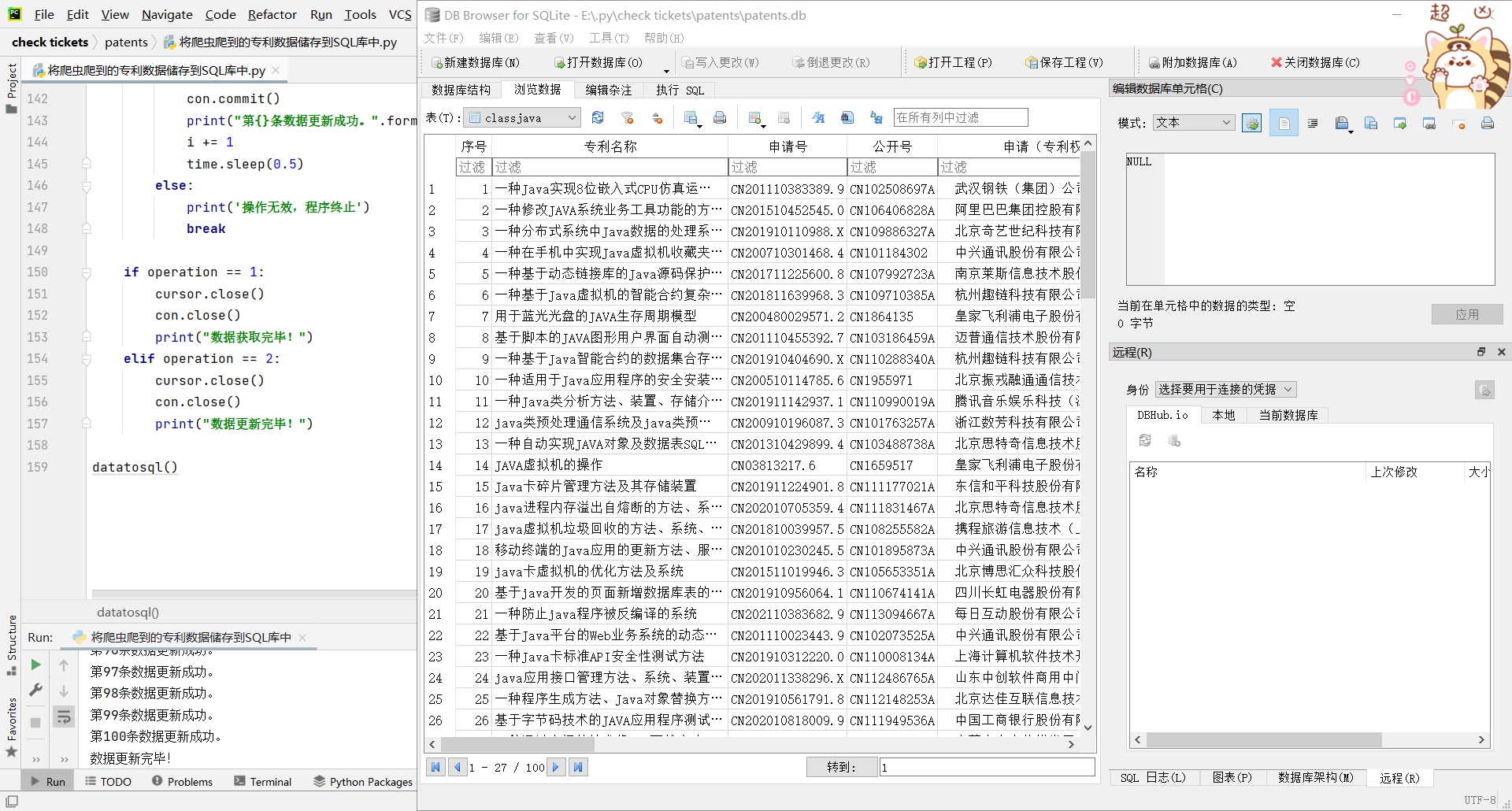
这里也是刚才没有关闭数据库的情况,再次打开就是下面图的效果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号