腾讯2017校招开发工程师笔试试卷(二)
请问下列代码的输出是多少()
1 #include <stdio.h> 2 int main() 3 { 4 int m []={1,2,3,4,5,6,7,8,9,0}; 5 int(*p)[4]=(int(*)[4])m; 6 printf(“%”,p[1][2]); 7 return 0; 8 }
解析
By FlyingByWind
1、int (*p)[4]:表示行指针,单位移动量为4个int类型。即p+1,则一次移动4个int类型
2、(int (*)[4])m:表示以数组指针类型组织m,每4个为一个数组
3、这样一来,m为{{1,2,3,4},{5,6,7,8},{9,0, , }},p指向第一行
4、故p[1][2]即*(*(p+1)+2),表示第二行第三个元素,为7
下面关于数据库唯一索引正确的是( )?
A.表可以包含多个唯一约束,但只能有一个主键
B.唯一约束列可以包含null值
C.唯一约束列可修改和更新
D.唯一约束不能用来定义外键
解析
By 爱到荼蘼_却不肯回头
1.主键约束(PRIMARY KEY)
1) 主键用于唯一地标识表中的每一条记录,可以定义一列或多列为主键。
2) 是不可能(或很难)更新.
3) 主键列上没有任何两行具有相同值(即重复值),不允许空(NULL).
4) 主健可作外健,唯一索引不可;
2.唯一性约束(UNIQUE)
1) 唯一性约束用来限制不受主键约束的列上的数据的唯一性,用于作为访问某行的可选手段,一个表上可以放置多个唯一性约束.
2) 只要唯一就可以更新.
3) 即表中任意两行在 指定列上都不允许有相同的值,允许空(NULL).
4) 一个表上可以放置多个唯一性约束
3.唯一索引(INDEX)
创建唯一索引可以确保任何生成重复键值的尝试都会失败。
唯一性约束和主键约束的区别:
(1).唯一性约束允许在该列上存在NULL值,而主键约束的限制更为严格,不但不允许有重复,而且也不允许有空值。
(2).在创建唯一性约束和主键约束时可以创建聚集索引和非聚集索引,但在 默认情况下主键约束产生聚集索引,而唯一性约束产生非聚集索引
约束和索引, 前者是用来检查数据的正确性,后者用来实现数据查询的优化,目的不同。
唯一性约束与唯一索引有所不同:
(1).创建唯一约束会在Oracle中创建一个Constraint,同时也会创建一个该约束对应的唯一索引。
(2).创建唯一索引只会创建一个唯一索引,不会创建Constraint。
也就是说其实唯一约束是通过创建唯一索引来实现的。
在删除时这两者也有一定的区别:
删除唯一约束时可以只删除约束而不删除对应的索引,所以对应的列还是必须唯一的,
而删除了唯一索引的话就可以插入不唯一的值
1) 主键用于唯一地标识表中的每一条记录,可以定义一列或多列为主键。
2) 是不可能(或很难)更新.
3) 主键列上没有任何两行具有相同值(即重复值),不允许空(NULL).
4) 主健可作外健,唯一索引不可;
2.唯一性约束(UNIQUE)
1) 唯一性约束用来限制不受主键约束的列上的数据的唯一性,用于作为访问某行的可选手段,一个表上可以放置多个唯一性约束.
2) 只要唯一就可以更新.
3) 即表中任意两行在 指定列上都不允许有相同的值,允许空(NULL).
4) 一个表上可以放置多个唯一性约束
3.唯一索引(INDEX)
创建唯一索引可以确保任何生成重复键值的尝试都会失败。
唯一性约束和主键约束的区别:
(1).唯一性约束允许在该列上存在NULL值,而主键约束的限制更为严格,不但不允许有重复,而且也不允许有空值。
(2).在创建唯一性约束和主键约束时可以创建聚集索引和非聚集索引,但在 默认情况下主键约束产生聚集索引,而唯一性约束产生非聚集索引
约束和索引, 前者是用来检查数据的正确性,后者用来实现数据查询的优化,目的不同。
唯一性约束与唯一索引有所不同:
(1).创建唯一约束会在Oracle中创建一个Constraint,同时也会创建一个该约束对应的唯一索引。
(2).创建唯一索引只会创建一个唯一索引,不会创建Constraint。
也就是说其实唯一约束是通过创建唯一索引来实现的。
在删除时这两者也有一定的区别:
删除唯一约束时可以只删除约束而不删除对应的索引,所以对应的列还是必须唯一的,
而删除了唯一索引的话就可以插入不唯一的值
employee的表结构及数据结构如图所示,以下语句结果分别为:
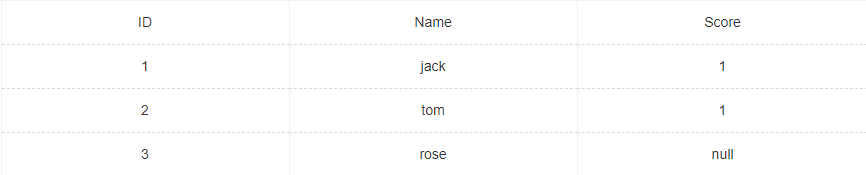
select count(*) from employee; select conut(1) from employee; select count(Score) from employee;
解析:
By jhuil
Count(1)和Count(*)实际上的意思是,评估Count()中的表达式是否为NULL,如果为NULL则不计数,而非NULL则会计数。
比如 select count( ) from tablename 则结果为零,而 select count(*) 或者 count(1)或者count('anything') from tablename 则都可以统计到表中所有行数。
假定一种编码的编码范围是a-y的25个字母,从1位到4位的编码,如果我们把该编码按字典序排序,形成一个数组如下:
a,aa,aaa,aaaa,aaab,aaac,.....,....,b,ba,baa,baaa,baab,baac,... ...,yyyw,yyyx,yyyy
其中a的Index为0,aa的Index为1,aaa的Index为2,以此类推。
编写一个函数,输入是任意一个编码,输出这个编码对应的index,如:
输入:baca
输出:16328
解析
By opps_li
#include <iostream>
#include <string>
#include <math.h>
using namespace std;
int main(){
string s;
while(cin>>s){
int len=s.length();
int index=0;
for(int i=0; i<len; i++,index++){
int n=s[i]-'a';
for(int j=0; j<4-i; j++)
index+=n*pow(25,j);
}
cout<<index-1<<endl;
}
return 0;
}
游戏里面有很多各种各样的任务,其中有一种任务玩家只能做一次,这类任务一共有1024个,任务ID范围[1,1024].请用32个unsigned int类型来记录着1024个任务是否已经完成。初始状态为未完成。
输入两个参数,都是任务ID,需要设置第一个ID的任务为已经完成;并检查第二个ID的任务是否已经完成。
输出一个参数,如果第二个ID的任务已经完成输出1,如果未完成输出0,。如果第一或第二个ID不在[1,1024]范围,则输出1.
如:
输入:1024 1024
输出:1
解析
By Vivian。~
//每个unsigned int 有32位,unsigned int target[32]就可表示 32*32个任务ID的状态。
#include<iostream>
using namespace std;
int main()
{
unsigned int target[32] = {0};
int ID1, ID2;
cin>>ID1>>ID2;
if(ID1<1||ID1>1024||ID2<1||ID2>1024)
{
cout<<-1<<endl;
return 0;
}
int groupID = ID1/32;
int indexID = ID1%32;
int marktmp = 1<<indexID;
target[groupID] = target[groupID]|marktmp;
groupID = ID2/32;
indexID = ID2%32;
marktmp = 1<<indexID;
if(marktmp & target[groupID]) cout<<1<<endl;
else cout<<0<<endl;
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号