

编程实现基于信息熵进行划分选择的决策树算法(ID3,C4.5)
1.题目理解
编程实现基于信息熵进行划分选择的决策树算法(包括ID3,C4.5两种算法),并为表4.3中的数据生成一棵决策树。
2.算法原理
2.1信息熵
度量样本集合纯度最常用的一种指标, 信息熵的值越小,则样本集合D的纯度越高。
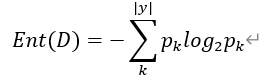
2.2信息增益(ID3中使用)
假定离散属性α有V个可能的取值{ a1 ,…,av},若使用α来对样本集D进行划分,则会产生V个分支结点,其中第v个分支结点包含了D中所有在属性α上取值为 av的样本,记为Dv 。计算出Dv 的信息熵,再考虑到不同的分支结点所包含的样本数不同,给分支结点赋予权重|Dv|/|D| .即样本数越多的分支结点的影响越大,于是可计算出用属性α对样本集D进行划分所获得的“信息增益”:
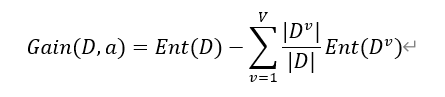
一般而言,信息增益越大,意味着使用属性a进行划分所获得的“纯度提升”越大,因此可以用信息增益来作为决策树的划分属性的准则。
不足:实际上,信息增益准则对可取值数目较多的属性有所偏好:当某一属性a可取值的数目较多时,每个属性值下的样本集合Dv数目较小,相对其他属性而言,样本集合Dv的纯度更高,从而导致该属性的信息增益偏大,影响决策树的泛化能力。
2.3信息增益率(C4.5中使用)
为了减少信息增益准则的不利影响,使用增益率来选择最优属性划分,增益率定义为:
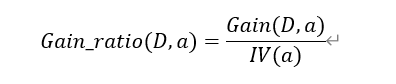
其中,
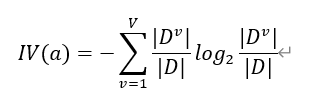
不足:通常属性a的可能取值数目越多,固有值通常会越大;当属性可取值数目较少时,固有值较小,导致增益率可能偏大,即增益率准则对可取值数目较少的属性有所偏好。
优化:综合信息增益和增益率的特点,C4.5算法并不是直接选择增益率最大的候选划分属性,而是使用了一个启发式:先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。
2.4决策树的生成算法
假设训练集是D,属性集是A,递归生成决策树。
首先生成结点node,如果D中的样本全部属于同一类别C,将node标记为C类叶结点,返回上一层递归;
如果属性集A是空集或者D中的样本有完全相同的属性值,将node标记为叶结点,类别是此时D中样本数最多的类,返回上一层递归;
否则,根据信息增益或增益率选出最优划分属性a,对a中的每一个属性值生成一个分支,选择D中对应属性值的样本作为子集Dv :如果某属性值对应的子集为空集,将该分支对应的子结点标记为叶结点,类别是D中样本数最多的类;如果某属性值对应的子集不是空集,将Dv 和A-a作为输入递归生成决策树。
3.算法设计和关键代码
3.1计算信息熵
在西瓜数据集中,统计好瓜和和坏瓜的数目;计算好瓜、坏瓜分别占西瓜总数的比例;根据公式计算出信息熵;

1 # 信息熵 2 def entropy(melons): 3 m_num = len(melons) # 瓜数 4 good_num = 0 5 bad_num = 0 6 for i in range(m_num): 7 if melons[i][7]==1: good_num +=1 8 bad_num = m_num - good_num 9 p_good = good_num/m_num 10 p_bad = bad_num/m_num 11 ent = -(p_good * math.log(p_good, 2) + p_bad * math.log(p_bad, 2)) 12 return ent
3.2计算不同属性的信息增益(属性分为连续值和离散值计算)并选择最佳属性(ID3树)
离散值有明显的类别可以直接计算,连续值使用二分法进行分类,将每种不同的分法都看作一类,最终与离散值一起选择使信息增益最高的属性;
求解信息熵时和信息增益时,要注意每类西瓜数不能为零;如果Dv类西瓜数量为0,则对应的信息熵为0;信息增益同理。(防止除数为0和log0的情况)。
1 # 计算信息增益 2 def Gain(melons, chara): 3 feature_ent = 0 4 gain = 0 5 m_num = len(melons) 6 7 # 连续density 8 if chara >= 6: 9 d1_good = 0 # 小于等于div 10 d1_bad = 0 11 d2_good = 0 12 d2_bad = 0 13 14 # for div in divide_point: 15 for j in range(m_num): 16 if melons[j][6] <= divide_point[chara - 6] and melons[j][7] == 1: d1_good += 1 17 if melons[j][6] <= divide_point[chara - 6] and melons[j][7] == 0: d1_bad += 1 18 if melons[j][6] > divide_point[chara - 6] and melons[j][7] == 1: d2_good += 1 19 if melons[j][6] > divide_point[chara - 6] and melons[j][7] == 0: d2_bad += 1 20 d1 = d1_good + d1_bad 21 d2 = d2_good + d2_bad 22 # 防止除以0 23 if d1_good==0 and d1_bad==0: 24 p1g = 0 25 p1b = 0 26 else: 27 p1g = d1_good/d1 28 p1b = d1_bad/d1 29 if d2_good==0 and d2_bad==0: 30 p2g = 0 31 p2b = 0 32 else: 33 p2g = d2_good/d2 34 p2b = d2_bad/d2 35 # 防止log0 36 if d1_good != 0 and d1_bad != 0: 37 entd1 = -d1 / m_num * (-(p1g * math.log(p1g, 2) + p1b * math.log(p1b, 2))) 38 elif d1_good==0 and d1_bad!=0: 39 entd1 = -d1 / m_num *(-p1b * math.log(p1b, 2)) 40 elif d1_good!=0 and d1_bad==0: 41 entd1 = -d1 / m_num * (-p1g * math.log(p1g, 2)) 42 else: 43 entd1 = 0 44 45 if d2_good != 0 and d2_bad != 0: 46 entd2 = -d2 / m_num * (-(p2g * math.log(p2g, 2) + p2b * math.log(p2b, 2))) 47 elif d2_good==0 and d2_bad!=0: 48 entd2 = -d2 / m_num *(-p2b * math.log(p2b, 2)) 49 elif d2_good!=0 and d2_bad==0: 50 entd2 = -d2 / m_num * (-p2g * math.log(p2g, 2)) 51 else: 52 entd2 = 0 53 gain = entropy(melons) + entd1 + entd2 54 55 # 触感 56 elif chara==5: 57 d1_good = 0 58 d1_bad = 0 59 d2_good =0 60 d2_bad = 0 61 for i in range(m_num): 62 if melons[i][5] == 0 and melons[i][7] == 1: d1_good += 1 63 if melons[i][5] == 0 and melons[i][7] == 0: d1_bad += 1 64 if melons[i][5] == 1 and melons[i][7] == 1: d2_good += 1 65 if melons[i][5] == 1 and melons[i][7] == 0: d2_bad += 1 66 d1 = d1_good + d1_bad 67 d2 = d2_good + d2_bad 68 69 if d1 == 0: 70 entd1 = 0 71 elif d1_good == 0: 72 p1b = d1_bad / d1 73 entd1 = -(p1b * math.log(p1b, 2)) 74 elif d1_bad == 0: 75 p1g = d1_good / d1 76 entd1 = -(p1g * math.log(p1g, 2)) 77 elif d1_good != 0 and d1_bad != 0: 78 p1g = d1_good / d1 79 p1b = d1_bad / d1 80 entd1 = -(p1g * math.log(p1g, 2) + p1b * math.log(p1b, 2)) 81 82 if d2 == 0: 83 entd2 = 0 84 elif d2_good == 0: 85 p2b = d2_bad / d2 86 entd2 = -(p2b * math.log(p2b, 2)) 87 elif d2_bad == 0: 88 p2g = d2_good / d2 89 entd2 = -(p2g * math.log(p2g, 2)) 90 elif d2_good != 0 and d2_bad != 0: 91 p2g = d2_good / d2 92 p2b = d2_bad / d2 93 entd2 = -(p2g * math.log(p2g, 2) + p2b * math.log(p2b, 2)) 94 feature_ent = feature_ent-(entd1*d1/m_num+entd2*d2/m_num) 95 gain = entropy(melons) + feature_ent 96 97 # 其余离散特征 98 else: # chara==0 or chara==1 or chara==2 or chara==3 or chara==4: 99 attr_mat = [['青绿', '乌黑', '浅白'], ['蜷缩', '稍蜷', '硬挺'], ['浊响', '沉闷', '清脆'], ['清晰', '稍糊', '模糊'], ['凹陷', '稍凹', '平坦']] 100 d1_good = 0 101 d1_bad = 0 102 d2_good = 0 103 d2_bad = 0 104 d3_good = 0 105 d3_bad = 0 106 for i in range(m_num): 107 if melons[i][chara] == 0 and melons[i][7] == 1: d1_good += 1 108 if melons[i][chara] == 0 and melons[i][7] == 0: d1_bad += 1 109 if melons[i][chara] == 1 and melons[i][7] == 1: d2_good += 1 110 if melons[i][chara] == 1 and melons[i][7] == 0: d2_bad += 1 111 if melons[i][chara] == 2 and melons[i][7] == 1: d3_good += 1 112 if melons[i][chara] == 2 and melons[i][7] == 0: d3_bad += 1 113 d1 = d1_good + d1_bad 114 d2 = d2_good + d2_bad 115 d3 = d3_good + d3_bad 116 if d1 == 0: 117 entd1 = 0 118 elif d1_good == 0: 119 p1b = d1_bad / d1 120 entd1 = -(p1b * math.log(p1b, 2)) 121 elif d1_bad == 0: 122 p1g = d1_good / d1 123 entd1 = -(p1g * math.log(p1g, 2)) 124 elif d1_good != 0 and d1_bad != 0: 125 p1g = d1_good / d1 126 p1b = d1_bad / d1 127 entd1 = -(p1g * math.log(p1g, 2) + p1b * math.log(p1b, 2)) 128 129 if d2 == 0: 130 entd2 = 0 131 elif d2_good == 0: 132 p2b = d2_bad / d2 133 entd2 = -(p2b * math.log(p2b, 2)) 134 elif d2_bad == 0: 135 p2g = d2_good / d2 136 entd2 = -(p2g * math.log(p2g, 2)) 137 elif d2_good != 0 and d2_bad != 0: 138 p2g = d2_good / d2 139 p2b = d2_bad / d2 140 entd2 = -(p2g * math.log(p2g, 2) + p2b * math.log(p2b, 2)) 141 142 if d3 == 0: 143 entd3 = 0 144 elif d3_good == 0: 145 p3b = d3_bad / d3 146 entd3 = -(p3b * math.log(p3b, 2)) 147 elif d3_bad == 0: 148 p3g = d3_good / d3 149 entd3 = -(p3g * math.log(p3g, 2)) 150 elif d3_good != 0 and d3_bad != 0: 151 p3g = d3_good / d3 152 p3b = d3_bad / d3 153 entd3 = -(p3g * math.log(p3g, 2) + p3b * math.log(p3b, 2)) 154 155 feature_ent = feature_ent-(entd1 * d1 / m_num + entd2 * d2 / m_num + entd3 * d3 / m_num) 156 gain = entropy(melons) + feature_ent 157 158 return [gain, chara]
1 def choose_best_feature(melons, A): 2 max_ent= Gain(melons, A[0]) 3 for i in range(len(A)): 4 ent_temp = Gain(melons, A[i]) 5 if ent_temp[0]>max_ent[0]: 6 max_ent = ent_temp 7 return max_ent
3.3计算不同属性的信息增益率并选择最佳属性
1 # 计算增益率 2 def Gainratio(melons, chara): 3 # 离散值 4 if chara<5: 5 in_value = 0 6 num0 = len(melons) 7 for i in range(3): 8 num = 0 9 for dd in melons: 10 if dd[chara]==i: 11 num += 1 12 if num!=0: 13 in_value -= abs(num/num0)*math.log(abs(num/num0), 2) 14 gain = Gain(melons, chara) 15 g_ratio = gain[0]/in_value 16 17 elif chara==5: 18 in_value = 0 19 num0 = len(melons) 20 for i in range(2): 21 num = 0 22 for dd in melons: 23 if dd[chara] == i: 24 num += 1 25 if num != 0: 26 in_value -= abs(num / num0) * math.log(abs(num / num0), 2) 27 gain = Gain(melons, chara) 28 g_ratio = gain[0] / in_value 29 30 else: 31 # 连续值 32 in_value = 0 33 num0 = len(melons) 34 s = 0 35 l = 0 36 for j in melons: 37 if j[6]>divide_point[chara-6]: 38 l += 1 39 else: 40 s += 1 41 if l!=0 and s!=0: 42 in_value -= abs(l / num0) * math.log(abs(l / num0), 2) 43 in_value -= abs(s / num0) * math.log(abs(s / num0), 2) 44 elif s==0 and l!=0: 45 in_value -= abs(l/num0)*math.log(abs(l/num0), 2) 46 elif l==0 and s!=0: 47 in_value -= abs(s/num0)*math.log(abs(s/num0), 2) 48 # if in_value==0: 49 # g_ratio = 0 50 # else: 51 gain = Gain(melons, chara) 52 g_ratio = gain[0] / in_value 53 54 return [g_ratio, chara]
1 def choose_best_feature(melons, A): 2 new_ent, new_A = choose_some_feature(melons, A) 3 max_ent= Gainratio(melons, new_A[0]) 4 for i in range(len(new_A)): 5 ent_temp = Gainratio(melons, new_A[i]) 6 if ent_temp[0]>max_ent[0]: 7 max_ent = ent_temp 8 return max_ent
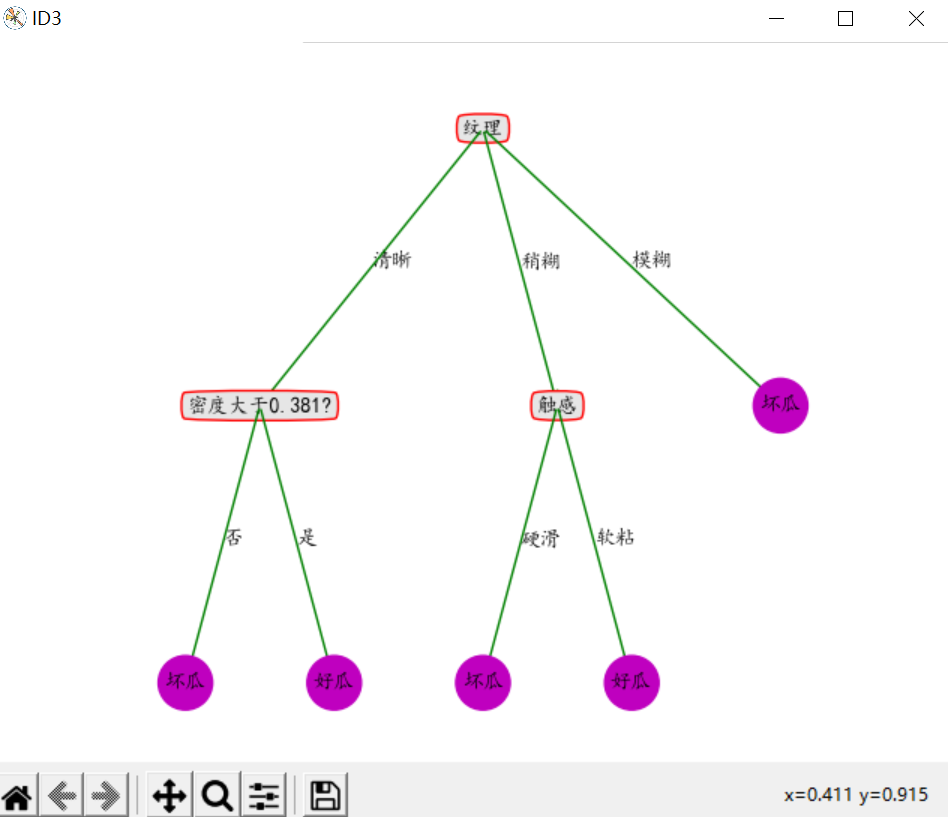
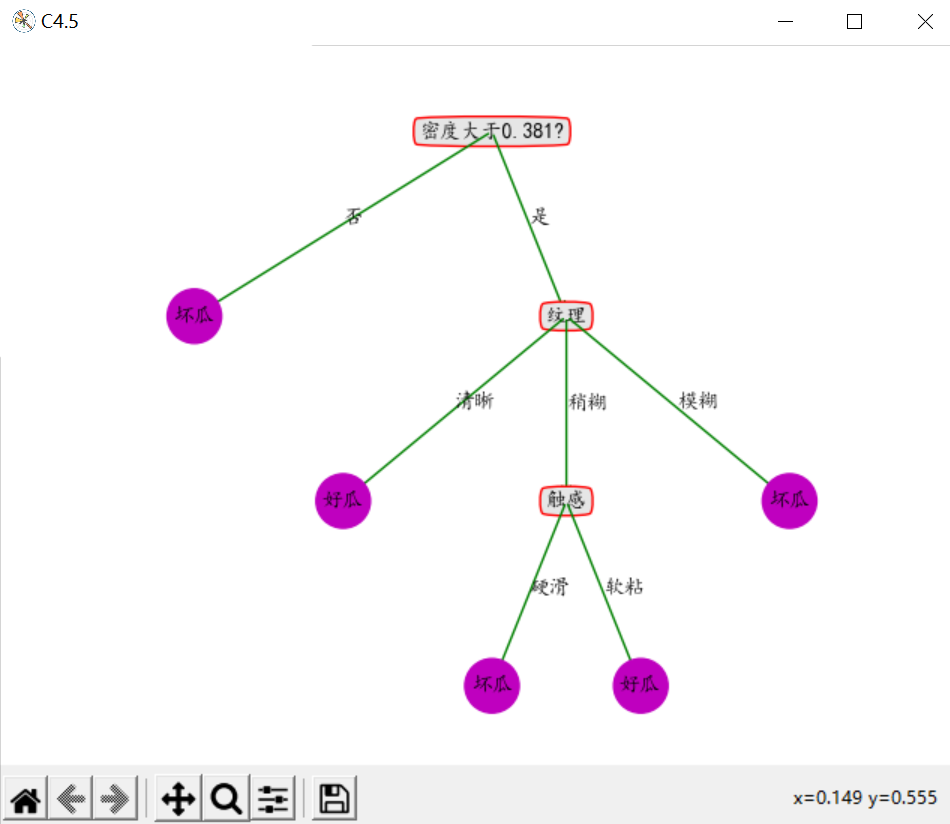
5.结果展示




· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· 字符编码:从基础到乱码解决
· 提示词工程——AI应用必不可少的技术