图书推荐系统
- 实验介绍
通过在阿里云天池上获取关于图书书本的数据集,核心是围绕协同过滤算法进行推荐,主要是完成以下目标:
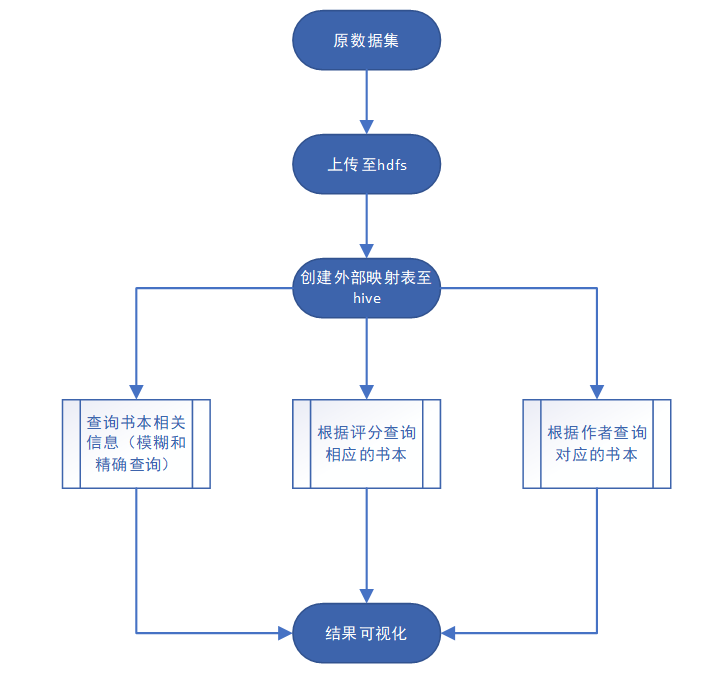
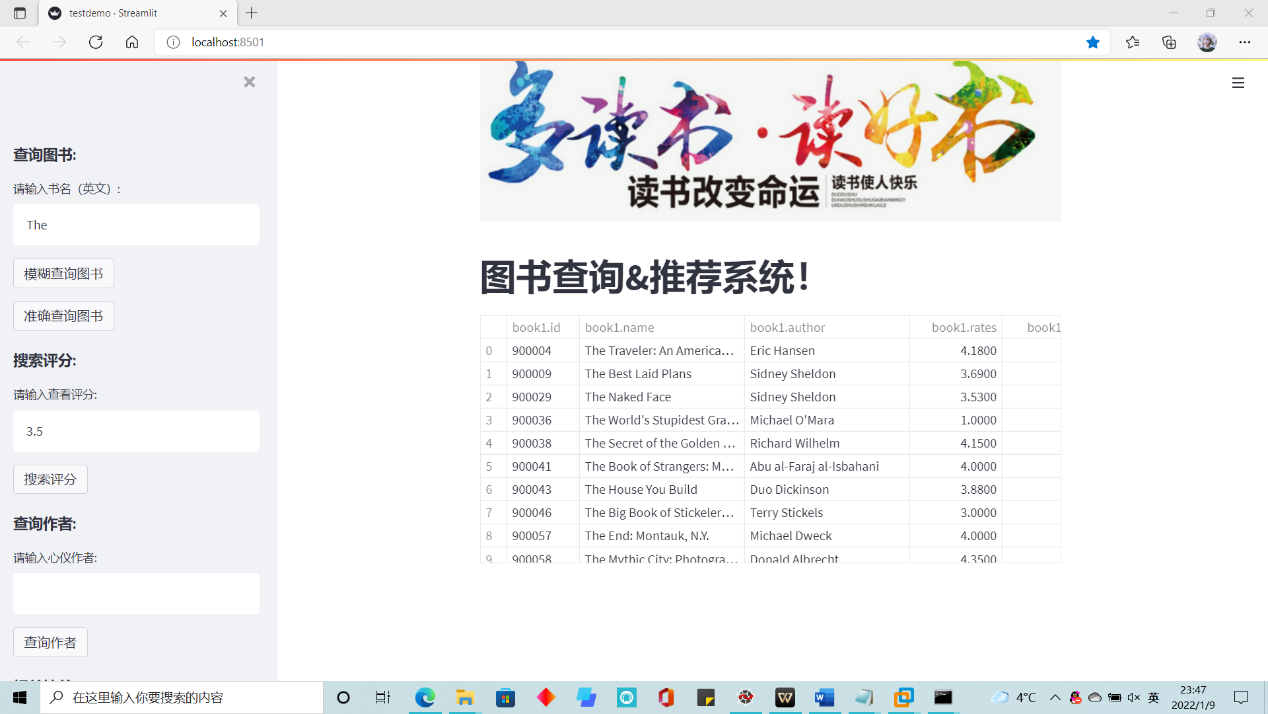
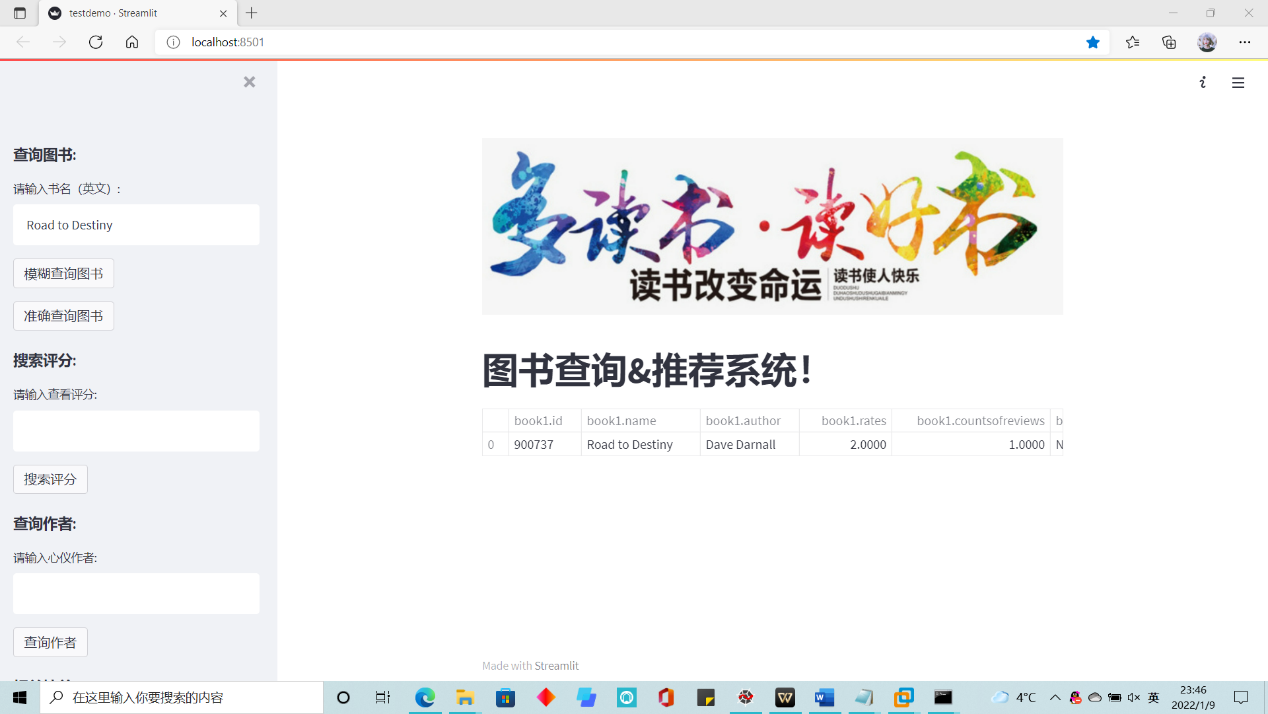
查询功能:基于图书名实现模糊查询和准确查询,基于评分和作者名进行准确查询。
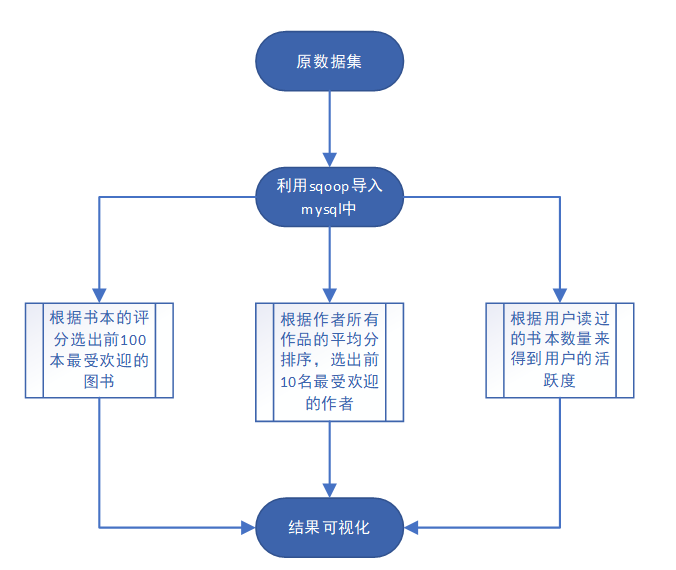
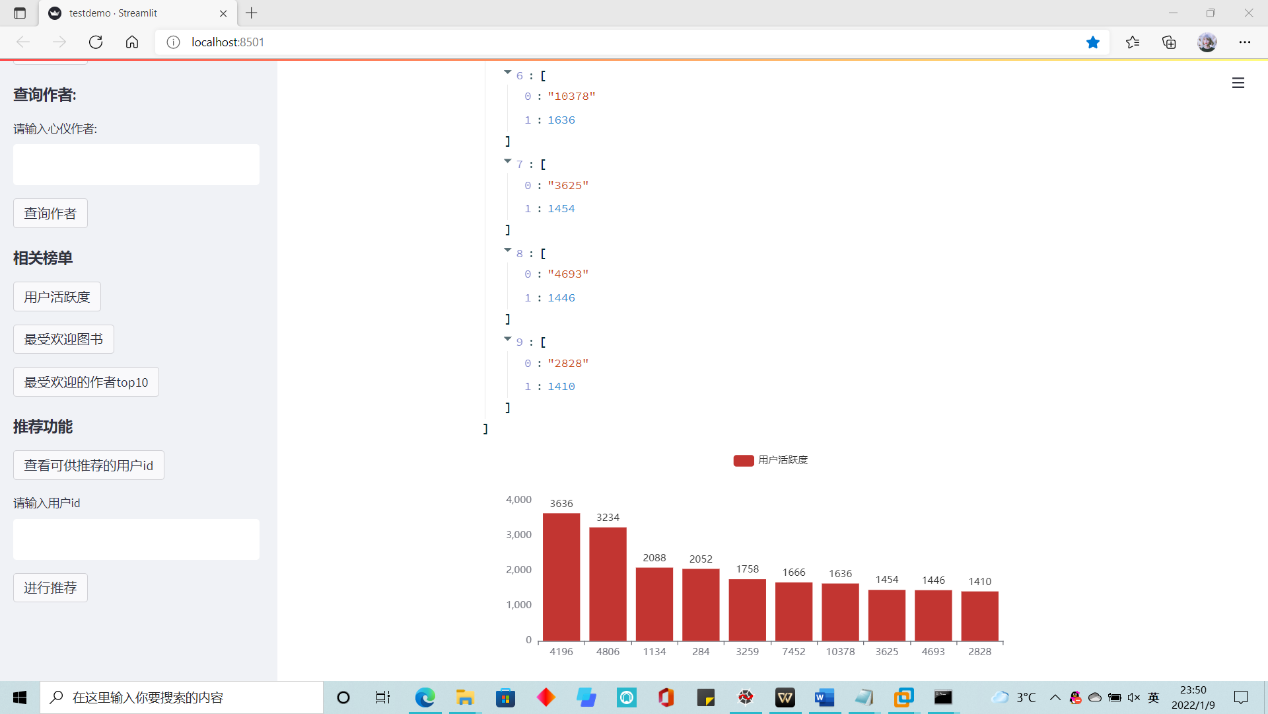
统计功能:基于图书的平均评分、读者对于某书的平均评分和用户评论数作为依据,进行相关统计。
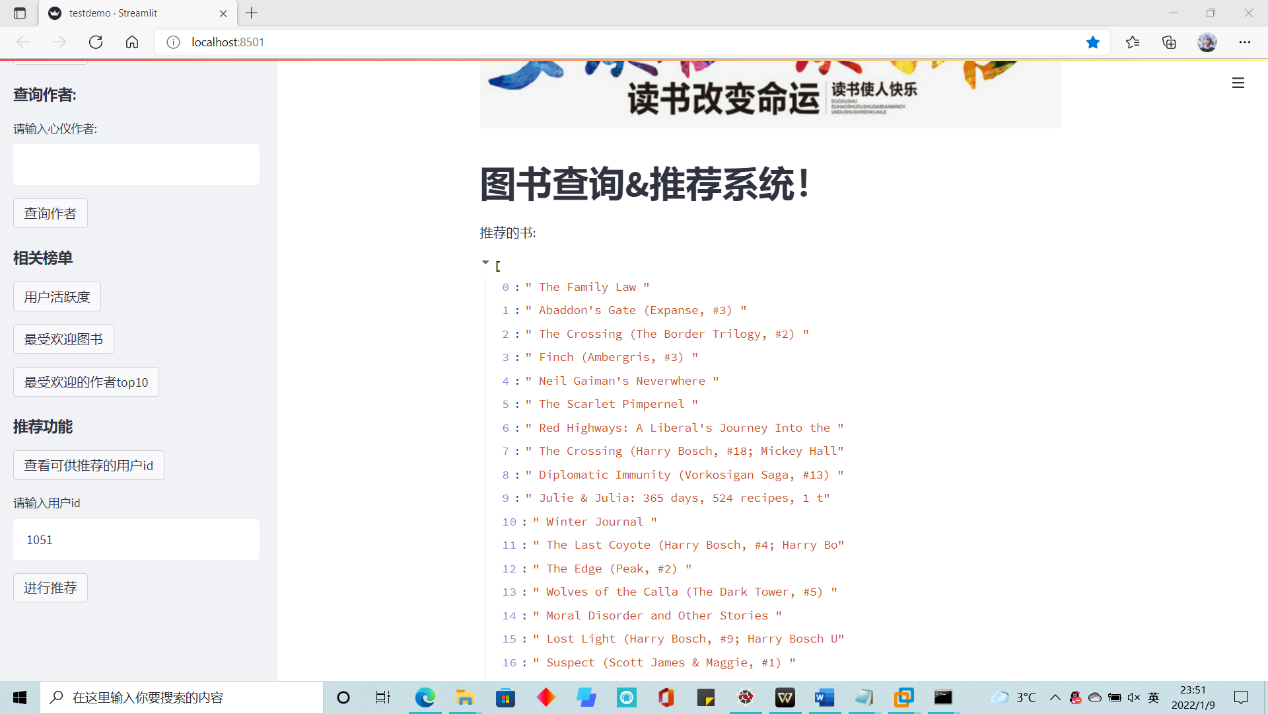
推荐功能:基于mapreduce和协同过滤算法,对某用户进行图书推荐。
- 实验框架
- 流程设计
- 查询功能
![]()
- 统计功能
![]()
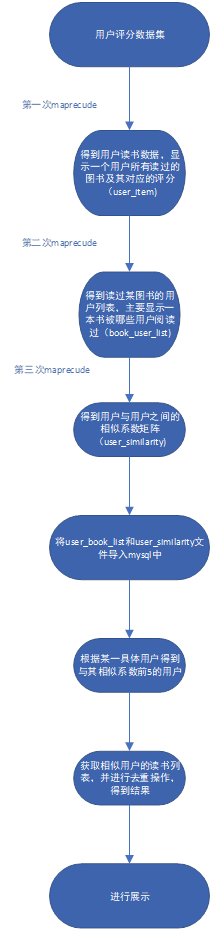
- 推荐功能
![]()
- 关键代码
- 查询功能:主要是基于hive来进行查询,主要是用sql语句来进行查询功能,如模糊查询书名;
先连接hive,然后编写sql语句进行相关查询,最后用impala库中自带的as_pandas函数进行相关展示。
-
1. if st.sidebar.button("模糊查询图书"): 2. sizee=0 3. if bookn=="": 4. st.info('请输入查询书名!') 5. else: 6. sql='''''select * from book1 where name like '''+'\''+str(bookn)+'%'+'\''+' limit 10' 7. cursor.execute(sql) 8. a=as_pandas(cursor) 9. 10. b=np.mat(a) 11. result=b.tolist() 12. if len(result)==0: 13. st.info('抱歉,未查询到对应书目。') 14. else: 15. 16. st.dataframe(a)
- 统计功能:这块主要是用mysql进行查询,然后用pyecharts画相关表进行展示。
-
1. if st.sidebar.button("用户活跃度"): 2. 3. sql = '''''select userid ,count(*) from rate1 group by userid order by count(*) desc limit 10''' 4. sqlcursor.execute(sql) 5. users = sqlcursor.fetchall() 6. users 7. user=[] 8. num=[] 9. for u in users: 10. user.append(u[0]) 11. num.append(u[1]) 12. bar=Bar() 13. bar.add_xaxis(user) 14. bar.add_yaxis('用户活跃度', num) 15. 16. streamlit_echarts.st_pyecharts(bar)
- 推荐功能:
本实验中的图书推荐系统是基于用户的协同过滤算法实现的:主要分为3个Mapreduce步骤:
第一步:根据用户评分数据集得到用户-评分矩阵:
Map操作:key=user_id;values=[书名, 评分]
Reduce操作:key=user_id;values=[阅读量,总评分,[书名, 评分],[ 书名, 评分]]
-
1. class Step1(MRJob): 2. def map_user(self, key, line): 3. user_id, item_name, rating = line.split('^') # 将原数据划分 4. yield user_id, (item_name, float(rating)) # map结果 user_id, [书名, 评分] 5. 6. def reduce_item(self, user_id, values): 7. item_count = 0 # 用户读过的图书总数 后续计算用户相似度需要 8. item_sum = 0 # 所有评分总和 9. final = [] 10. for item_name, rating in values: 11. item_count += 1 12. item_sum += rating 13. final.append((item_name, rating)) # reduce书名和评分 14. yield user_id, (item_count, item_sum, final) # user_id, [count, sum, ratings] 15. 16. def steps(self): 17. return [MRStep(mapper=self.map_user, 18. reducer=self.reduce_item),]
第二步:以第一步得到的用户-评分矩阵作为输入,寻找读过某图书的用户列表;考虑到数据节点的性能,为了便于计算,将上一步的结果筛选,使用阅读量在[300, 500]的用户数据;
Map操作:key=图书名;values=[user_id,阅读量]
Reduce操作:key=图书名;values=[[user_id1,阅读量1]…… [user_idn,阅读量n]]。
-
1. class Step2(MRJob): 2. # map输出的key:图书名, value:用户,阅读量 3. def map_item(self, id, line): 4. strr = line.split('\t', 1) # 划分一次 5. user_id = eval(strr[0]) 6. values = eval(strr[1]) 7. item_count, item_sum, ratings = values 8. for item in ratings: 9. yield item[0], (user_id, item_count) 10. 11. # 得到book user_list 12. def reduce_user(self, item, values): 13. user_list = [] 14. for user in values: 15. user_list.append(user) 16. yield item, (user_list) 17. 18. def steps(self): 19. return [MRStep(mapper=self.map_item, 20. reducer=self.reduce_user), ]
第三步:以上一步得到的图书用户列表作为输入文件,计算用户之间的相似度;
Map操作:key=[用户id1,用户id2];values=[id1阅读量,id2阅读量]
Reduce操作:key=[用户id1,用户id2];values=[相似度,共同图书阅读量]
-
1. class Step3(MRJob): 2. def pair_users(self, user_id, line): 3. values = eval(line.split('\t')[1]) 4. for user1, user2 in combinations(values, 2): 5. yield (user1[0], user2[0]), (user1[1], user2[1]) 6. # user1[0]是用户名,user1[1]是用户阅读量 7. 8. def cal_similarity(self, users, counts): 9. num = 0 # num表示两人共同读过的图书数量 10. user_pair, count = users, counts # count是用户1和用户2的阅读量 11. user1, user2 = user_pair 12. cnt1 = 0 13. cnt2 = 0 14. for c1, c2 in count: 15. num += 1 # 当两个key相同时,num++,表示共同图书加一 16. cnt1 = c1 17. cnt2 = c2 18. fenmu = cnt1 + cnt2 -num 19. similarity = float(num / fenmu) 20. yield (user1, user2), (similarity, num)
- 查询功能:主要是基于hive来进行查询,主要是用sql语句来进行查询功能,如模糊查询书名;
- 结果展示
- 查询功能:根据书名进行模糊查询和准确查询;查询评分、查询作者。
![]()
![]()
- 统计功能:用户活跃度、最受欢迎图书等
![]()
- 推荐功能:
考虑到有的用户读的书本很少,相比之下无法进行准确推荐,对于这部分用户进行推荐查询时会提醒用户去查看相关榜单;
![]()
- 该图书推荐系统的关键在于
- 推荐算法的实现,使用了基于用户的协同过滤算法,利用三次mapreduce操作实现算法;
- 将数据存放至hdfs,使用Hadoop分布式平台。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号