时间序列数据库:
1,时间序列数据库是指对带时间戳或时间序列数据优化的数据库。
2,时间序列数据库专门用于处理带时间戳的指标和事件或测量,随时间跟踪,监控,下采样和聚合的度量或事件
3,常规数据的时间序列数据的主要区别在于,您随时都会询问有关它的问题,可以是服务器指标,应用程序性能监控,网络数据,传感器数据,事件,点击,市场交易以及许多其他类型的分析数据
4,TSDB针对测量随时间的变化进行了优化,底层平台需要不断发展以支持这些新工作负载 - 更多数据点,更多数据源,更多监控,更多控制,一切都有或将有传感器,公司内外的一切都在发出的指标和事件或时间序列数据流
5,时间序列数据库,通常会在很长一段时间内请求数据摘要。这需要通过一系列数据点来执行一些计算,对于分布式密钥值存储,这种工作负载很难优化。TSDB针对此用例进行了优化,可在数月的数据内提供毫秒级查询时间
influxDB 操作提供了三种方式:
1)客户端命令行方式
2)HTTP API接口
3)各语言API库
以下使用客户端命令的方式:
对于数据库操作
# 查看所有的数据库
show databases;
#创建数据库!
create database test;
#删除数据库
drop database test;
#使用数据库
use xk_name;
对于表操作
# 显示所有的表
SHOW MEASUREMENTS;
#InfluxDB中没有显式的新建表的语句,只能通过insert数据的方式来建立新表
#disk_free是表名,hostname=server01是tag,属于索引,value=xx是field,这个可以随意写,随意定义。
#InfluxDB规定格式,首先是表名,后面是tags,然后是field,最后是时间戳。tags、field和时间戳三者之间以空格相分隔
insert disk_free,hostname=server01 value=442221834240i 1435362189575692182;
influxDB 常见字段与说明:现实之中的influx 都是一个 value 字段!
# influxdb的数据都有一列名为time的列,里面存储UTC时间戳
tag #索引字段 ,根据这个字段查询会很快,如果不根据这个字段查询相当于遍历表。
field key,field value,field set #字段键key,值value 两者合并称之为 set
field key, #它们为string类型
field value #可以为string,float,integer或boolean类型
retention policy #指数据保留策略,默认的autogen,它表示数据一直保留永不过期,副本数量为1
series #共享同一个retention policy,measurement以及tag set的数据集合
point #point则是同一个series中具有相同时间的field set,points相当于SQL中的数据行
influx 数据保存策略
1,InfluxDB的数据保留策略(RP) 用来定义数据在InfluxDB中存放的时间,或者定义保存某个期间的数据。
2,一个数据库可以有多个保留策略,但每个策略必须是独一无二的。
3,InfluxDB本身不提供数据的删除操作,因此用来控制数据量的方式就是定义数据保留策略。
4,数据保留策略的目的是让InfluxDB能够知道可以丢弃哪些数据,从而更高效的处理数据
# 对于 数据库 mydb 创建一个策略 '2_hours' duration(持续时间)为2小时,副本为1,设置为默认策略。
create retention policy "2_hours" on "mydb" duration 2h replication 1 default
# 对于数据库 mydb 展示出所有的策略
show retention policies on mydb;
# 修改策略 2_hours 为默认策略 ,持续时间为 2h
alter retention policy "2_hours" on "mydb" duration 4h default;
# 查看使用 default 策略的 cpu 表信息
select * from "default".cpu limit 2
![]()
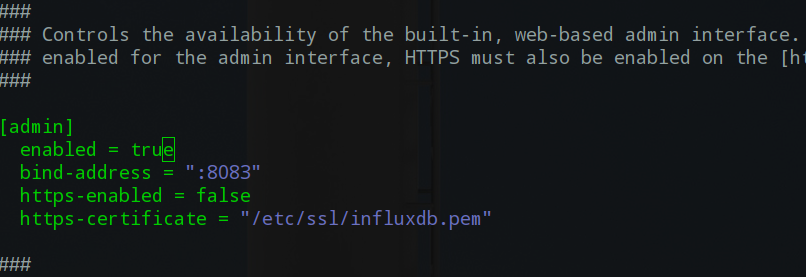
二,HTTP API接口说明
在配置文件/etc/influxdb/influxdb.conf之中,定义web端口与ip <IP>:8083 就可以访问
![]()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号