![]()
![]()
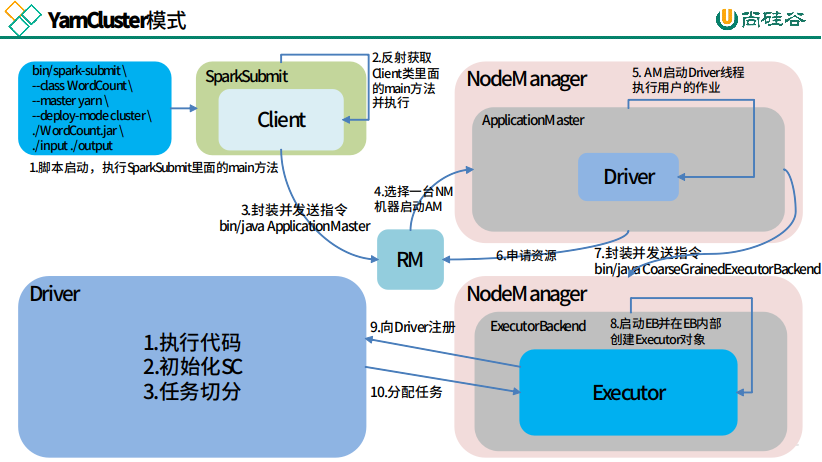
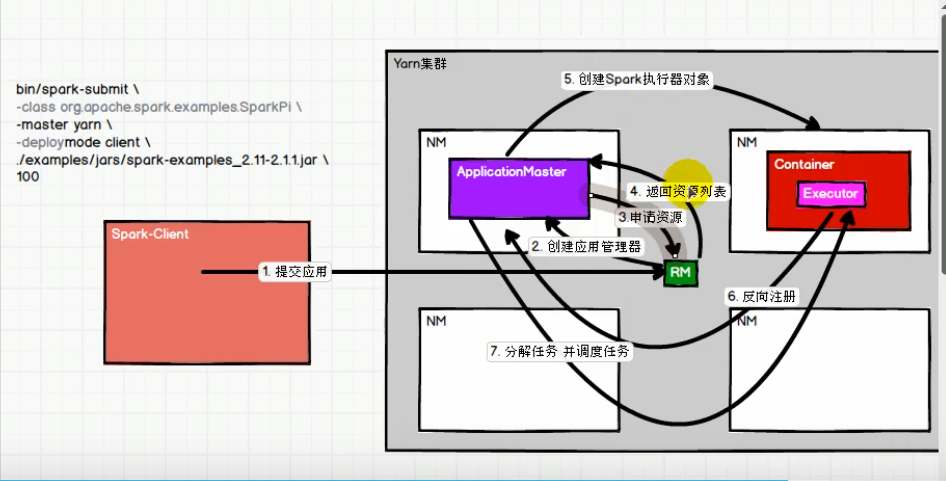
三,yarn-cluster 模式提交流程
1, 启动脚本, 执行 Spark-Submit 里面的 main 方法
1),对提交参数进行模式匹配,比如 client 模式匹配到的 --class 传递给变量 mainclass
2, 如果是 cluster 模式 , mainclass = "org.apache.spark.deploy.yarn.Client"
2, 反射调用 mainclass
1), 查找 main 方法 mainClass.getMethod("main",new Array[String](0).getClass)
2), 调用 main 方法 mainMethod.invoke
3), client 类之中获取参数 --class 传递给变量 userClass
4), 创建yarn 集群连接对象 yarnClient = YarnClient.createYarnClient, 运行 yarnClient.run()
3,封装并发送指令,选择一台nodemanager启动ApplicationMaster,run() 方法之中
1),初始化 containerContext, 封装指令 command = "bin/java org.apache.spark.deploy.yarn.ApplicationMaster"
3),向yarn提交封装参数(也就是RM) yarnClient.submitApplication(appContext),生成 appId(application_1557709015812_0001)
2),yarnClient.submitApplication() 之中找到一个nodemanager 执行 command. 产生JVM进程,也就是ApplicationMaster进程
4,启动ApplicationMaster
1),创建 应用管理器对象master = new ApplicationMaster(args,new YarnRMClient()) new YarnRMClient()是RM连接对象
2), master.run()
1> runDriver() 获取userClass之中的main方法,
2> 并且开启线程执 main方法,userThread.setname("driver") 此线程名字叫做driver
5,AM 启动driver线程, 执行用户作业,申请资源
1),在 driver线程之中: 使用rpc注册AM, client.register 获取 yarn 资源
2),AM rpc通信到 RM 分配资源 allocator.allocateResources(),获取可用container
6,封装并发送指令,
NdClient连接nodemanager,在nodemanager启动container,准备 CoarseGrainedExecutorBackend command
7, 根据数据与计算本地化(进程本地化,节点本地化,机架本地化)来选择启动 CoarseGrainedExecutorBackend:
1> 使用 rpc向ApplicationMaster进行反向注册,rpc接收到ApplicationMaster回复消息之后,创建executor对象 executor= new Executor()
2> 当ApplicationMaster(driver 的 job(taskSet))发送LaunchTask之后, executor 开始启动 executor.LaunchTask()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号