kudu的介绍:
KUDU在 HDFS 和 HBase 这两个中平衡了随机读写和批量分析的性能,既支持了SQL实时查询,也支持了数据更新插入操作
kudu 术语:
Tablet(段):一个tablet是一张table连续的segment,与其它数据存储引擎或关系型数据库partition(分区)相似。在一定的时间范围内,tablet的副本冗余到多个tserver服务器上,其中一个副本被认为是leader tablet。任何副本都可以对读取进行服务,并且写入时需要为tablet服务的一组tablet server之间达成一致性。一张表分成多个tablet,分布在不同的tablet server中,最大并行化操作,Tablet在Kudu中被切分为更小的单元,叫做RowSets,RowSets分为两种MemRowSets和DiskRowSet,MemRowSets每生成32M,就溢写到磁盘中,也就是DiskRowSet
Catalog Table(目录表):catalog table是Kudu 的 metadata(元数据中)的中心位置。它存储有关tables和tablets的信息。该catalog table(目录表)可能不会被直接读取或写入。相反,它只能通过客户端 API中公开的元数据操作访问
MetaData: block和block在data中的位置。
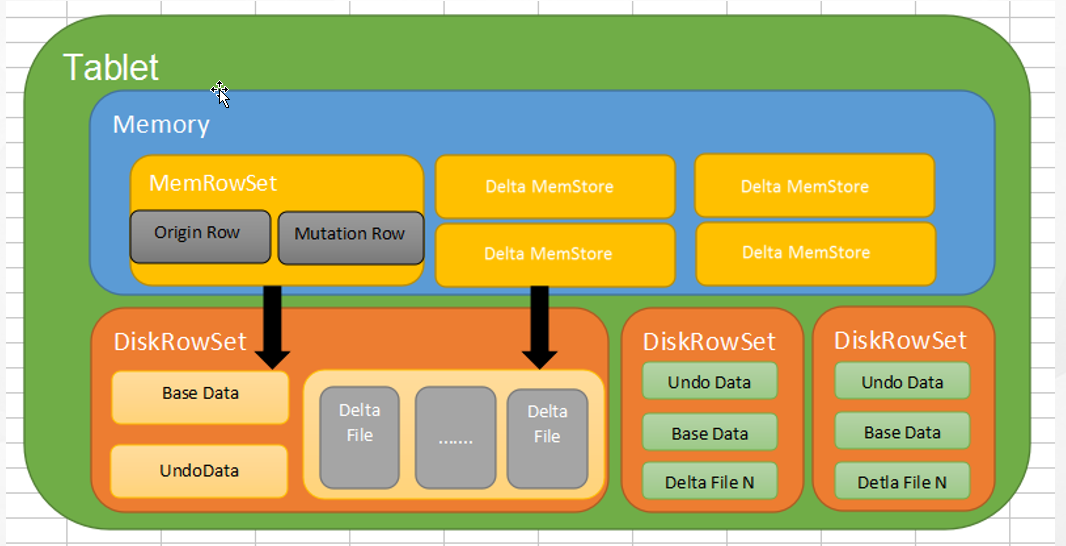
MemRowSet:其中MemRowSet用于存储insert数据和update后的数据,写满后会刷新到磁盘中也就是多个DiskRowSet中,默认是1G刷新一次或者是2分钟。
BloomFile:根据DiskRowSet中key生成一个bloom filter,用于快速模糊的定位某一个key是否在DiskRowSet中。
Ad_hoc Index:是主键的索引,用于定位key在DiskRowSet中具体哪个偏移位置。
BaseData:是MemRowSet flush下来的数据,按照列存储,按照主键有序。
UndoFile:是BaseData之前的数据历史数据。
RedoFile:是BaseData之后的mutation记录,可以获得较新的数据。
DeltaMem:用于在内存中存储mutation记录,先写到内存中,然后写满后flush到磁盘,形成deltafile。
Minor Compaction:多个DeltaFile进行合并生成一个大的DeltaFile。默认是1000个DeltaFile进行合并一次
Major Compaction:DeltaFile文件的大小和Base data的文件的比例为0.1的时候,会进行合并操作,生成Undo data
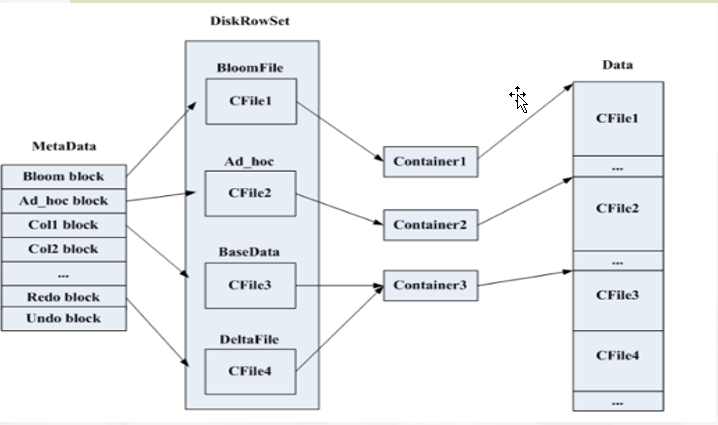
tablet 架构图:
1,kudu中的Tablet是负责Table表的一部分的读写工作,Tablet是有多个或一个Rowset组成的,其中一个Rowset处于内存中,叫做MemRowSet,MemRowSet主要是负责处理新的数据写入请求。DiskRowSet是MemRowSet达到1G刷新一次或者是时间超过2分钟后刷新到磁盘后生成的,实际底层存储是是有Base Data(一个CFile文件)、多个Delta file(Undo data、Redo data组成)的和Delta MemStore,其中位于磁盘中的Base data、Undo data、Redo data是不可修改的,Delta Memstore达到一定程度后会刷新到磁盘中的生成Redo data,其中kudu后台有一个类似HBase的compaction线程策略进行合并处理
2,当创建Kudu客户端时,其会从主master上获取tablet位置信息,然后直接与服务于该tablet的服务器进行交谈。为了优化读取和写入路径,客户端将保留该信息的本地缓存,以防止他们在每个请求时需要查询主机的tablet位置信息。随着时间的推移,客户端的缓存可能会变得过时,并且当写入被发送到不是领导者的tablet服务器时,则将被拒绝。然后,客户端将通过查询主服务器发现新领导者的位置来更新其缓存。
读流程:
1、客户端连接TMaster获取表的相关信息,包括分区信息,表中所有tablet的信息
2、客户端找到需要读取的数据的tablet所在的TServer,Kudu接受读请求,并记录timestamp信息,如果没有显式指定,那么表示使用当前时间
3、从内存中读取数据,也就是MemRowSet和DeltaRowSet中读取数据,根据timestamp来找到对应的mutation链表
4、从磁盘中读取数据,从metadata文件中使用boom filter快速模糊的判断所有候选RowSet是否含有此key。然后从DiskRowSet中读取数据,实际是根据B+树,判断key在那些DiskRowSet的range范围内,然后从metadata文件中,获取index来判断rowId在Data中的偏移,或者是利用validex来判断数据的偏移(只有一个key),根据读操作中包含的timestamp信息判断是否需要将base data进行回滚操作从而获取数据
写流程(Kudu插入一条新数据):
1、客户端连接TMaster获取表的相关信息,包括分区信息,表中所有tablet的信息
2、客户端找到负责处理读写请求的tablet所负责维护的TServer。Kudu接受客户端的请求,检查请求是否符合要求(表结构)
3、Kudu在Tablet中的所有rowset(memrowset,diskrowset)中进行查找,看是否存在与待插入数据相同主键的数据,如果存在就返回错误,否则继续
4、写入操作先被提交到tablet的预写日志(WAL),并根据Raft一致性算法取得追随节点的同意,然后才会被添加到其中一个tablet的内存中,插入会被添加到tablet的MemRowSet中。为了在MemRowSet中支持多版本并发控制(MVCC),对最近插入的行(即尚未刷新到磁盘的新的行)的更新和删除操作将被追加到MemRowSet中的原始行之后以生成REDO记录的列表
5、Kudu在MemRowset中写入一行新数据,在MemRowset(1G或者是120s)数据达到一定大小时,MemRowset将数据落盘,并生成一个diskrowset用于持久化数据,还生成一个memrowset继续接收新数据的请求
数据的更新流程:
1、客户端连接TMaster获取表的相关信息,包括分区信息,表中所有tablet的信息
2、Kudu接受请求,检查请求是否符合要求
3、因为待更新数数据可能位于memrowset中,也可能已经flush到磁盘上,形成diskrowset。因 此根据待更新数据所处位置不同,kudu有不同的做法
1),当待更新数据位于memrowset时,找到待更新数据所在行,然后将更新操作记录在所在行中一个mutation链表中;在memrowset将数据落盘时,Kudu会将更新合并到base data,并生成UNDO records用于查看历史版本的数据,REDO records实际上也是以DeltaFile的形式存放
2),当待更新数据位于DiskRowset时,找到待更新数据所在的DiskRowset,每个DiskRowset都会在内存中设置一个DeltaMemStore,将更新操作记录在DeltaMemStore中,在DeltaMemStore达到一定大小时,flush在磁盘,形成DeltaFile中。


