kafaka 常用组件:
1,producer:消息的生产者, 自己决定哪个 partions 中生产消息, 两种机制:hash 与 轮询
2,consumer:通过 zookeeper 进行维护消费者偏移量, consumer有自己的消费组,不同组之间维护同一个 topic 数据,互不影响.相同组的不同 consumer消费同一个 topic,这个 topic相同的数据只被消费一次
3,broker:broker 组成 kafka 集群的节点,之间没有主从关系, 依赖 zookeeper进行协调, broker 负责消息的读写与存储, 一个 broker可以管理读个 partions
4,topic:一类消息的总称/消息队里, topic是由 partions组成, 一个 topic 由多台 server 里的 partions 组成
5,zookeeper 协调 kafka broker,存储元数据, consumer的 offset+ broker 信息 +topic信息+ partions信息
6,partions 组成 topic 的单元, 每个 topic有副本(创建 topic 指定), 每个 partions 只能有有个 broker管理
kafka的消息存储和生产消费模型:
1,一个topic分成多个partition(就是读写文件),多个 partition 是为了增加并行化,也就是可以多一个consumer去连接
2,每个partition内部消息强有序,其中的每个消息都有一个序号叫offset
3,一个partition只对应一个broker,一个broker可以管多个partition
4,消息直接写入文件,并不是存储在内存中,根据时间策略(默认一周)删除,而不是消费完就删除
5,producer自己决定往哪个partition写消息,可以是轮询的负载均衡,或者是基于hash的partition策略
kafka的消息存储和生产消费模型:
1,kafka里面的消息是有topic来组织的,简单的我们可以想象为一个队列,一个队列就是一个topic,然后它把每个topic又分为很多个partition,这个是为了做并行的,在每个partition里面是有序的,相当于有序的队列,其中每个消息都有个序号,比如0到12,从前面读往后面写。
2,一个partition对应一个broker,一个broker可以管多个partition,比如说,topic有6个partition,有两个broker,那每个broker就管3个partition。
3,这个partition可以很简单想象为一个文件,当数据发过来的时候它就往这个partition上面append,追加就行,kafka和很多消息系统不一样,很多消息系统是消费完了我就把它删掉,而kafka是根据时间策略删除,而不是消费完就删除,在kafka里面没有一个消费完这么个概念,只有过期这样一个概念
kafka 使用操作:
# 创建 topic 指定分区个数, 可以不指定 端口,使用默认
./kafka-topics.sh --zookeeper master:2181,slave1,slave2 --create --topic t0425 --partitions 3
# 查看 topic list
./kafka-topics.sh --zookeeper sr128:2181,sr129,sr130 --list
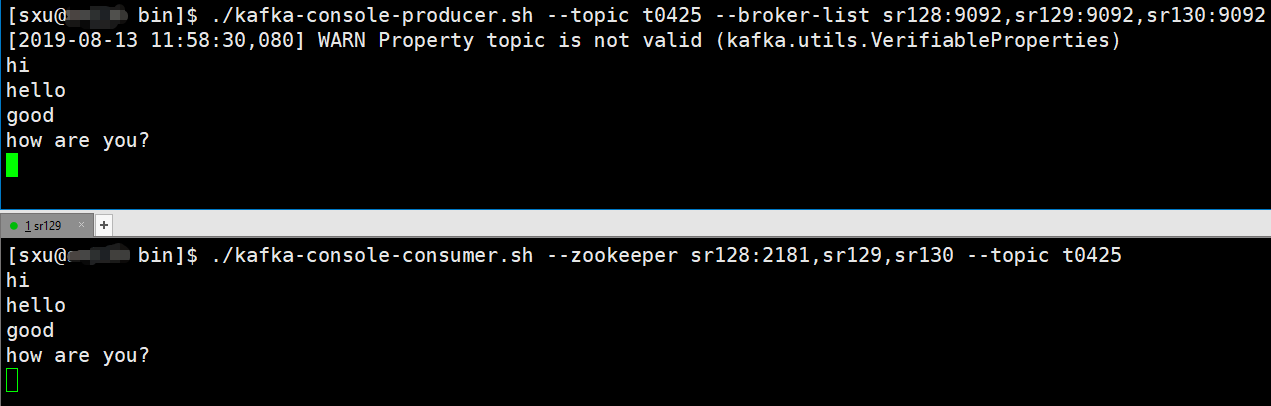
# 生产者
./kafka-console-producer.sh --topic t0425 --broker-list master:9092,slave1:9092,slave2:9092
# 消费者
./kafka-console-consumer.sh --zookeeper master:2181,slave1,slave2 --topic t0425
![]()
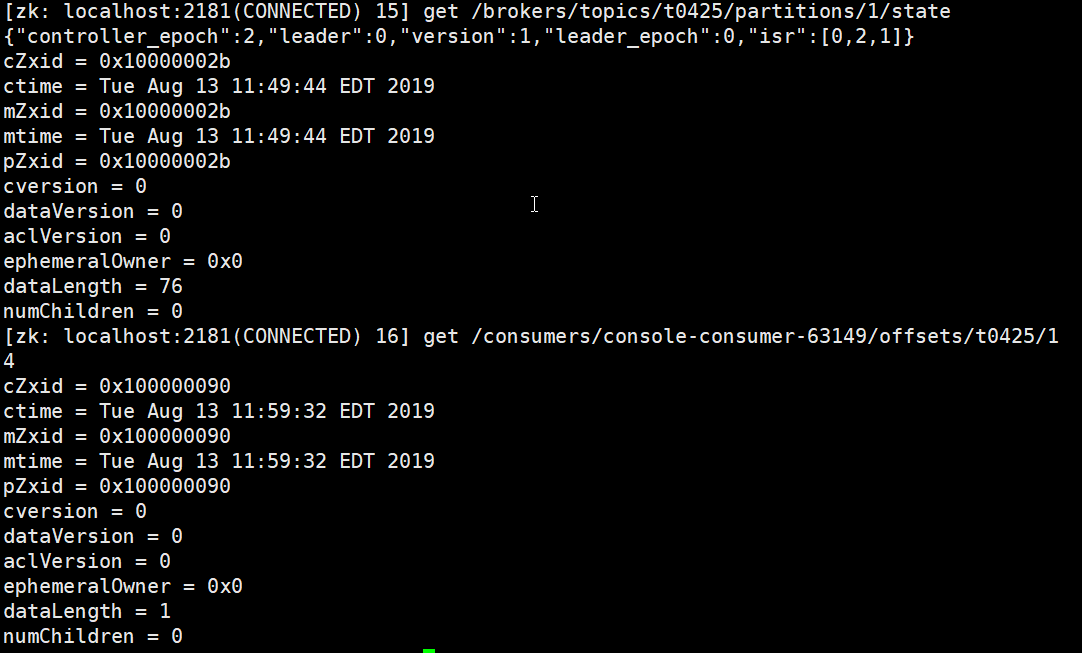
zookeeper 查看元数据(上述存储的只有 v ,k 为 none 所以只会一个partition)
![]()
kafka 便签:
1,Offset:kafka的存储文件都是按照offset.kafka来命名,用offset做名字的好处是方便查找。例如你想找位于2049的位置,只要找到2048.kafka的文件即可。当然the first offset就是00000000000.kafka
2,每个group中可以有多个consumer,每个consumer属于一个consumer group,通常情况下,一个group中会包含多个consumer,这样不仅可以提高topic中消息的并发消费能力,而且还能提高"故障容错"性,如果group中的某个consumer失效那么其消费的partitions将会有其他consumer自动接管

 浙公网安备 33010602011771号
浙公网安备 33010602011771号