/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.hadoop.mapred;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.DataOutputStream;
import java.io.File;
import java.io.IOException;
import java.io.OutputStream;
import java.nio.ByteBuffer;
import java.nio.ByteOrder;
import java.nio.IntBuffer;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.ReentrantLock;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.FileSystem.Statistics;
import org.apache.hadoop.fs.LocalFileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.RawLocalFileSystem;
import org.apache.hadoop.io.DataInputBuffer;
import org.apache.hadoop.io.RawComparator;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.SequenceFile.CompressionType;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.DefaultCodec;
import org.apache.hadoop.io.serializer.Deserializer;
import org.apache.hadoop.io.serializer.SerializationFactory;
import org.apache.hadoop.io.serializer.Serializer;
import org.apache.hadoop.mapred.IFile.Writer;
import org.apache.hadoop.mapred.Merger.Segment;
import org.apache.hadoop.mapred.SortedRanges.SkipRangeIterator;
import org.apache.hadoop.mapreduce.JobContext;
import org.apache.hadoop.mapreduce.MRJobConfig;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.TaskCounter;
import org.apache.hadoop.mapreduce.TaskType;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormatCounter;
import org.apache.hadoop.mapreduce.lib.map.WrappedMapper;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormatCounter;
import org.apache.hadoop.mapreduce.split.JobSplit.TaskSplitIndex;
import org.apache.hadoop.mapreduce.task.MapContextImpl;
import org.apache.hadoop.mapreduce.CryptoUtils;
import org.apache.hadoop.util.IndexedSortable;
import org.apache.hadoop.util.IndexedSorter;
import org.apache.hadoop.util.Progress;
import org.apache.hadoop.util.QuickSort;
import org.apache.hadoop.util.ReflectionUtils;
import org.apache.hadoop.util.StringInterner;
import org.apache.hadoop.util.StringUtils;
/** A Map task. */
@InterfaceAudience.LimitedPrivate({"MapReduce"})
@InterfaceStability.Unstable
public class MapTask extends Task {
/**
* The size of each record in the index file for the map-outputs.
*/
public static final int MAP_OUTPUT_INDEX_RECORD_LENGTH = 24;
private TaskSplitIndex splitMetaInfo = new TaskSplitIndex();
private final static int APPROX_HEADER_LENGTH = 150;
private static final Log LOG = LogFactory.getLog(MapTask.class.getName());
private Progress mapPhase;
private Progress sortPhase;
{ // set phase for this task
setPhase(TaskStatus.Phase.MAP);
getProgress().setStatus("map");
}
public MapTask() {
super();
}
public MapTask(String jobFile, TaskAttemptID taskId,
int partition, TaskSplitIndex splitIndex,
int numSlotsRequired) {
super(jobFile, taskId, partition, numSlotsRequired);
this.splitMetaInfo = splitIndex;
}
@Override
public boolean isMapTask() {
return true;
}
@Override
public void localizeConfiguration(JobConf conf)
throws IOException {
super.localizeConfiguration(conf);
}
@Override
public void write(DataOutput out) throws IOException {
super.write(out);
if (isMapOrReduce()) {
splitMetaInfo.write(out);
splitMetaInfo = null;
}
}
@Override
public void readFields(DataInput in) throws IOException {
super.readFields(in);
if (isMapOrReduce()) {
splitMetaInfo.readFields(in);
}
}
/**
* This class wraps the user's record reader to update the counters and progress
* as records are read.
* @param <K>
* @param <V>
*/
class TrackedRecordReader<K, V>
implements RecordReader<K,V> {
private RecordReader<K,V> rawIn;
private Counters.Counter fileInputByteCounter;
private Counters.Counter inputRecordCounter;
private TaskReporter reporter;
private long bytesInPrev = -1;
private long bytesInCurr = -1;
private final List<Statistics> fsStats;
TrackedRecordReader(TaskReporter reporter, JobConf job)
throws IOException{
inputRecordCounter = reporter.getCounter(TaskCounter.MAP_INPUT_RECORDS);
fileInputByteCounter = reporter.getCounter(FileInputFormatCounter.BYTES_READ);
this.reporter = reporter;
List<Statistics> matchedStats = null;
if (this.reporter.getInputSplit() instanceof FileSplit) {
matchedStats = getFsStatistics(((FileSplit) this.reporter
.getInputSplit()).getPath(), job);
}
fsStats = matchedStats;
bytesInPrev = getInputBytes(fsStats);
rawIn = job.getInputFormat().getRecordReader(reporter.getInputSplit(),
job, reporter);
bytesInCurr = getInputBytes(fsStats);
fileInputByteCounter.increment(bytesInCurr - bytesInPrev);
}
public K createKey() {
return rawIn.createKey();
}
public V createValue() {
return rawIn.createValue();
}
public synchronized boolean next(K key, V value)
throws IOException {
boolean ret = moveToNext(key, value);
if (ret) {
incrCounters();
}
return ret;
}
protected void incrCounters() {
inputRecordCounter.increment(1);
}
protected synchronized boolean moveToNext(K key, V value)
throws IOException {
bytesInPrev = getInputBytes(fsStats);
boolean ret = rawIn.next(key, value);
bytesInCurr = getInputBytes(fsStats);
fileInputByteCounter.increment(bytesInCurr - bytesInPrev);
reporter.setProgress(getProgress());
return ret;
}
public long getPos() throws IOException { return rawIn.getPos(); }
public void close() throws IOException {
bytesInPrev = getInputBytes(fsStats);
rawIn.close();
bytesInCurr = getInputBytes(fsStats);
fileInputByteCounter.increment(bytesInCurr - bytesInPrev);
}
public float getProgress() throws IOException {
return rawIn.getProgress();
}
TaskReporter getTaskReporter() {
return reporter;
}
private long getInputBytes(List<Statistics> stats) {
if (stats == null) return 0;
long bytesRead = 0;
for (Statistics stat: stats) {
bytesRead = bytesRead + stat.getBytesRead();
}
return bytesRead;
}
}
/**
* This class skips the records based on the failed ranges from previous
* attempts.
*/
class SkippingRecordReader<K, V> extends TrackedRecordReader<K,V> {
private SkipRangeIterator skipIt;
private SequenceFile.Writer skipWriter;
private boolean toWriteSkipRecs;
private TaskUmbilicalProtocol umbilical;
private Counters.Counter skipRecCounter;
private long recIndex = -1;
SkippingRecordReader(TaskUmbilicalProtocol umbilical,
TaskReporter reporter, JobConf job) throws IOException{
super(reporter, job);
this.umbilical = umbilical;
this.skipRecCounter = reporter.getCounter(TaskCounter.MAP_SKIPPED_RECORDS);
this.toWriteSkipRecs = toWriteSkipRecs() &&
SkipBadRecords.getSkipOutputPath(conf)!=null;
skipIt = getSkipRanges().skipRangeIterator();
}
public synchronized boolean next(K key, V value)
throws IOException {
if(!skipIt.hasNext()) {
LOG.warn("Further records got skipped.");
return false;
}
boolean ret = moveToNext(key, value);
long nextRecIndex = skipIt.next();
long skip = 0;
while(recIndex<nextRecIndex && ret) {
if(toWriteSkipRecs) {
writeSkippedRec(key, value);
}
ret = moveToNext(key, value);
skip++;
}
//close the skip writer once all the ranges are skipped
if(skip>0 && skipIt.skippedAllRanges() && skipWriter!=null) {
skipWriter.close();
}
skipRecCounter.increment(skip);
reportNextRecordRange(umbilical, recIndex);
if (ret) {
incrCounters();
}
return ret;
}
protected synchronized boolean moveToNext(K key, V value)
throws IOException {
recIndex++;
return super.moveToNext(key, value);
}
@SuppressWarnings("unchecked")
private void writeSkippedRec(K key, V value) throws IOException{
if(skipWriter==null) {
Path skipDir = SkipBadRecords.getSkipOutputPath(conf);
Path skipFile = new Path(skipDir, getTaskID().toString());
skipWriter =
SequenceFile.createWriter(
skipFile.getFileSystem(conf), conf, skipFile,
(Class<K>) createKey().getClass(),
(Class<V>) createValue().getClass(),
CompressionType.BLOCK, getTaskReporter());
}
skipWriter.append(key, value);
}
}
@Override
public void run(final JobConf job, final TaskUmbilicalProtocol umbilical)
throws IOException, ClassNotFoundException, InterruptedException {
this.umbilical = umbilical;
if (isMapTask()) {
// If there are no reducers then there won't be any sort. Hence the map
// phase will govern the entire attempt's progress.
// 如果没有 reduce
if (conf.getNumReduceTasks() == 0) {
mapPhase = getProgress().addPhase("map", 1.0f);
} else {
// If there are reducers then the entire attempt's progress will be
// split between the map phase (67%) and the sort phase (33%).
mapPhase = getProgress().addPhase("map", 0.667f);
// sort 排序
sortPhase = getProgress().addPhase("sort", 0.333f);
}
}
TaskReporter reporter = startReporter(umbilical);
boolean useNewApi = job.getUseNewMapper();
initialize(job, getJobID(), reporter, useNewApi);
// check if it is a cleanupJobTask
if (jobCleanup) {
runJobCleanupTask(umbilical, reporter);
return;
}
if (jobSetup) {
runJobSetupTask(umbilical, reporter);
return;
}
if (taskCleanup) {
runTaskCleanupTask(umbilical, reporter);
return;
}
if (useNewApi) {
// 新的 API
runNewMapper(job, splitMetaInfo, umbilical, reporter);
} else {
runOldMapper(job, splitMetaInfo, umbilical, reporter);
}
done(umbilical, reporter);
}
public Progress getSortPhase() {
return sortPhase;
}
@SuppressWarnings("unchecked")
private <T> T getSplitDetails(Path file, long offset)
throws IOException {
FileSystem fs = file.getFileSystem(conf);
FSDataInputStream inFile = fs.open(file);
inFile.seek(offset);
String className = StringInterner.weakIntern(Text.readString(inFile));
Class<T> cls;
try {
cls = (Class<T>) conf.getClassByName(className);
} catch (ClassNotFoundException ce) {
IOException wrap = new IOException("Split class " + className +
" not found");
wrap.initCause(ce);
throw wrap;
}
SerializationFactory factory = new SerializationFactory(conf);
Deserializer<T> deserializer =
(Deserializer<T>) factory.getDeserializer(cls);
deserializer.open(inFile);
T split = deserializer.deserialize(null);
long pos = inFile.getPos();
getCounters().findCounter(
TaskCounter.SPLIT_RAW_BYTES).increment(pos - offset);
inFile.close();
return split;
}
@SuppressWarnings("unchecked")
private <KEY, VALUE> MapOutputCollector<KEY, VALUE>
createSortingCollector(JobConf job, TaskReporter reporter)
throws IOException, ClassNotFoundException {
MapOutputCollector.Context context =
new MapOutputCollector.Context(this, job, reporter);
// MapOutputBuffer = MapOutputBuffer
Class<?>[] collectorClasses = job.getClasses(
JobContext.MAP_OUTPUT_COLLECTOR_CLASS_ATTR, MapOutputBuffer.class);
int remainingCollectors = collectorClasses.length;
Exception lastException = null;
for (Class clazz : collectorClasses) {
try {
if (!MapOutputCollector.class.isAssignableFrom(clazz)) {
throw new IOException("Invalid output collector class: " + clazz.getName() +
" (does not implement MapOutputCollector)");
}
Class<? extends MapOutputCollector> subclazz =
clazz.asSubclass(MapOutputCollector.class);
LOG.debug("Trying map output collector class: " + subclazz.getName());
MapOutputCollector<KEY, VALUE> collector =
ReflectionUtils.newInstance(subclazz, job);
collector.init(context);
LOG.info("Map output collector class = " + collector.getClass().getName());
return collector;
} catch (Exception e) {
String msg = "Unable to initialize MapOutputCollector " + clazz.getName();
if (--remainingCollectors > 0) {
msg += " (" + remainingCollectors + " more collector(s) to try)";
}
lastException = e;
LOG.warn(msg, e);
}
}
throw new IOException("Initialization of all the collectors failed. " +
"Error in last collector was :" + lastException.getMessage(), lastException);
}
@SuppressWarnings("unchecked")
private <INKEY,INVALUE,OUTKEY,OUTVALUE>
void runOldMapper(final JobConf job,
final TaskSplitIndex splitIndex,
final TaskUmbilicalProtocol umbilical,
TaskReporter reporter
) throws IOException, InterruptedException,
ClassNotFoundException {
InputSplit inputSplit = getSplitDetails(new Path(splitIndex.getSplitLocation()),
splitIndex.getStartOffset());
updateJobWithSplit(job, inputSplit);
reporter.setInputSplit(inputSplit);
RecordReader<INKEY,INVALUE> in = isSkipping() ?
new SkippingRecordReader<INKEY,INVALUE>(umbilical, reporter, job) :
new TrackedRecordReader<INKEY,INVALUE>(reporter, job);
job.setBoolean(JobContext.SKIP_RECORDS, isSkipping());
int numReduceTasks = conf.getNumReduceTasks();
LOG.info("numReduceTasks: " + numReduceTasks);
MapOutputCollector<OUTKEY, OUTVALUE> collector = null;
if (numReduceTasks > 0) {
collector = createSortingCollector(job, reporter);
} else {
collector = new DirectMapOutputCollector<OUTKEY, OUTVALUE>();
MapOutputCollector.Context context =
new MapOutputCollector.Context(this, job, reporter);
collector.init(context);
}
MapRunnable<INKEY,INVALUE,OUTKEY,OUTVALUE> runner =
ReflectionUtils.newInstance(job.getMapRunnerClass(), job);
try {
runner.run(in, new OldOutputCollector(collector, conf), reporter);
mapPhase.complete();
// start the sort phase only if there are reducers
if (numReduceTasks > 0) {
setPhase(TaskStatus.Phase.SORT);
}
statusUpdate(umbilical);
collector.flush();
in.close();
in = null;
collector.close();
collector = null;
} finally {
closeQuietly(in);
closeQuietly(collector);
}
}
/**
* Update the job with details about the file split
* @param job the job configuration to update
* @param inputSplit the file split
*/
private void updateJobWithSplit(final JobConf job, InputSplit inputSplit) {
if (inputSplit instanceof FileSplit) {
FileSplit fileSplit = (FileSplit) inputSplit;
job.set(JobContext.MAP_INPUT_FILE, fileSplit.getPath().toString());
job.setLong(JobContext.MAP_INPUT_START, fileSplit.getStart());
job.setLong(JobContext.MAP_INPUT_PATH, fileSplit.getLength());
}
LOG.info("Processing split: " + inputSplit);
}
static class NewTrackingRecordReader<K,V>
extends org.apache.hadoop.mapreduce.RecordReader<K,V> {
private final org.apache.hadoop.mapreduce.RecordReader<K,V> real;
private final org.apache.hadoop.mapreduce.Counter inputRecordCounter;
private final org.apache.hadoop.mapreduce.Counter fileInputByteCounter;
private final TaskReporter reporter;
private final List<Statistics> fsStats;
NewTrackingRecordReader(org.apache.hadoop.mapreduce.InputSplit split,
org.apache.hadoop.mapreduce.InputFormat<K, V> inputFormat,
TaskReporter reporter,
org.apache.hadoop.mapreduce.TaskAttemptContext taskContext)
throws InterruptedException, IOException {
this.reporter = reporter;
this.inputRecordCounter = reporter
.getCounter(TaskCounter.MAP_INPUT_RECORDS);
this.fileInputByteCounter = reporter
.getCounter(FileInputFormatCounter.BYTES_READ);
List <Statistics> matchedStats = null;
if (split instanceof org.apache.hadoop.mapreduce.lib.input.FileSplit) {
matchedStats = getFsStatistics(((org.apache.hadoop.mapreduce.lib.input.FileSplit) split)
.getPath(), taskContext.getConfiguration());
}
fsStats = matchedStats;
long bytesInPrev = getInputBytes(fsStats);
// 为输入对象创建输入记录器(默认 LineRecordReader)
this.real = inputFormat.createRecordReader(split, taskContext);
long bytesInCurr = getInputBytes(fsStats);
fileInputByteCounter.increment(bytesInCurr - bytesInPrev);
}
@Override
public void close() throws IOException {
long bytesInPrev = getInputBytes(fsStats);
real.close();
long bytesInCurr = getInputBytes(fsStats);
fileInputByteCounter.increment(bytesInCurr - bytesInPrev);
}
@Override
public K getCurrentKey() throws IOException, InterruptedException {
return real.getCurrentKey();
}
@Override
public V getCurrentValue() throws IOException, InterruptedException {
return real.getCurrentValue();
}
@Override
public float getProgress() throws IOException, InterruptedException {
return real.getProgress();
}
@Override
public void initialize(org.apache.hadoop.mapreduce.InputSplit split,
org.apache.hadoop.mapreduce.TaskAttemptContext context
) throws IOException, InterruptedException {
long bytesInPrev = getInputBytes(fsStats);
real.initialize(split, context);
long bytesInCurr = getInputBytes(fsStats);
fileInputByteCounter.increment(bytesInCurr - bytesInPrev);
}
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
long bytesInPrev = getInputBytes(fsStats);
boolean result = real.nextKeyValue();
long bytesInCurr = getInputBytes(fsStats);
if (result) {
inputRecordCounter.increment(1);
}
fileInputByteCounter.increment(bytesInCurr - bytesInPrev);
reporter.setProgress(getProgress());
return result;
}
private long getInputBytes(List<Statistics> stats) {
if (stats == null) return 0;
long bytesRead = 0;
for (Statistics stat: stats) {
bytesRead = bytesRead + stat.getBytesRead();
}
return bytesRead;
}
}
/**
* Since the mapred and mapreduce Partitioners don't share a common interface
* (JobConfigurable is deprecated and a subtype of mapred.Partitioner), the
* partitioner lives in Old/NewOutputCollector. Note that, for map-only jobs,
* the configured partitioner should not be called. It's common for
* partitioners to compute a result mod numReduces, which causes a div0 error
*/
private static class OldOutputCollector<K,V> implements OutputCollector<K,V> {
private final Partitioner<K,V> partitioner;
private final MapOutputCollector<K,V> collector;
private final int numPartitions;
@SuppressWarnings("unchecked")
OldOutputCollector(MapOutputCollector<K,V> collector, JobConf conf) {
numPartitions = conf.getNumReduceTasks();
if (numPartitions > 1) {
partitioner = (Partitioner<K,V>)
ReflectionUtils.newInstance(conf.getPartitionerClass(), conf);
} else {
partitioner = new Partitioner<K,V>() {
@Override
public void configure(JobConf job) { }
@Override
public int getPartition(K key, V value, int numPartitions) {
return numPartitions - 1;
}
};
}
this.collector = collector;
}
@Override
public void collect(K key, V value) throws IOException {
try {
collector.collect(key, value,
partitioner.getPartition(key, value, numPartitions));
} catch (InterruptedException ie) {
Thread.currentThread().interrupt();
throw new IOException("interrupt exception", ie);
}
}
}
private class NewDirectOutputCollector<K,V>
extends org.apache.hadoop.mapreduce.RecordWriter<K,V> {
private final org.apache.hadoop.mapreduce.RecordWriter out;
private final TaskReporter reporter;
private final Counters.Counter mapOutputRecordCounter;
private final Counters.Counter fileOutputByteCounter;
private final List<Statistics> fsStats;
@SuppressWarnings("unchecked")
NewDirectOutputCollector(MRJobConfig jobContext,
JobConf job, TaskUmbilicalProtocol umbilical, TaskReporter reporter)
throws IOException, ClassNotFoundException, InterruptedException {
this.reporter = reporter;
mapOutputRecordCounter = reporter
.getCounter(TaskCounter.MAP_OUTPUT_RECORDS);
fileOutputByteCounter = reporter
.getCounter(FileOutputFormatCounter.BYTES_WRITTEN);
List<Statistics> matchedStats = null;
if (outputFormat instanceof org.apache.hadoop.mapreduce.lib.output.FileOutputFormat) {
matchedStats = getFsStatistics(org.apache.hadoop.mapreduce.lib.output.FileOutputFormat
.getOutputPath(taskContext), taskContext.getConfiguration());
}
fsStats = matchedStats;
long bytesOutPrev = getOutputBytes(fsStats);
out = outputFormat.getRecordWriter(taskContext);
long bytesOutCurr = getOutputBytes(fsStats);
fileOutputByteCounter.increment(bytesOutCurr - bytesOutPrev);
}
@Override
@SuppressWarnings("unchecked")
public void write(K key, V value)
throws IOException, InterruptedException {
reporter.progress();
long bytesOutPrev = getOutputBytes(fsStats);
out.write(key, value);
long bytesOutCurr = getOutputBytes(fsStats);
fileOutputByteCounter.increment(bytesOutCurr - bytesOutPrev);
mapOutputRecordCounter.increment(1);
}
@Override
public void close(TaskAttemptContext context)
throws IOException,InterruptedException {
reporter.progress();
if (out != null) {
long bytesOutPrev = getOutputBytes(fsStats);
out.close(context);
long bytesOutCurr = getOutputBytes(fsStats);
fileOutputByteCounter.increment(bytesOutCurr - bytesOutPrev);
}
}
private long getOutputBytes(List<Statistics> stats) {
if (stats == null) return 0;
long bytesWritten = 0;
for (Statistics stat: stats) {
bytesWritten = bytesWritten + stat.getBytesWritten();
}
return bytesWritten;
}
}
private class NewOutputCollector<K,V>
extends org.apache.hadoop.mapreduce.RecordWriter<K,V> {
private final MapOutputCollector<K,V> collector;
private final org.apache.hadoop.mapreduce.Partitioner<K,V> partitioner;
private final int partitions;
@SuppressWarnings("unchecked")
NewOutputCollector(org.apache.hadoop.mapreduce.JobContext jobContext,
JobConf job,
TaskUmbilicalProtocol umbilical,
TaskReporter reporter
) throws IOException, ClassNotFoundException {
// 创建容器
collector = createSortingCollector(job, reporter);
// 此时可以得出reduce数量等于 partions
partitions = jobContext.getNumReduceTasks();
if (partitions > 1) {
// partitioner 分区器
partitioner = (org.apache.hadoop.mapreduce.Partitioner<K,V>)
ReflectionUtils.newInstance(jobContext.getPartitionerClass(), job);
} else {
partitioner = new org.apache.hadoop.mapreduce.Partitioner<K,V>() {
@Override
public int getPartition(K key, V value, int numPartitions) {
// 当 reduce 为 1 的时候,返回分区号 0, 所有的都在一个分区
return partitions - 1;
}
};
}
}
@Override
public void write(K key, V value) throws IOException, InterruptedException {
collector.collect(key, value,
partitioner.getPartition(key, value, partitions));
}
// output close() 方法
@Override
public void close(TaskAttemptContext context
) throws IOException,InterruptedException {
try {
//
collector.flush();
} catch (ClassNotFoundException cnf) {
throw new IOException("can't find class ", cnf);
}
collector.close();
}
}
@SuppressWarnings("unchecked")
private <INKEY,INVALUE,OUTKEY,OUTVALUE>
void runNewMapper(final JobConf job,
final TaskSplitIndex splitIndex,
final TaskUmbilicalProtocol umbilical,
TaskReporter reporter
) throws IOException, ClassNotFoundException,
InterruptedException {
// make a task context so we can get the classes
// taskContext 任务上下文 job 包含任务信息(来自提交的配置信息与 jar 包 )
org.apache.hadoop.mapreduce.TaskAttemptContext taskContext =
new org.apache.hadoop.mapreduce.task.TaskAttemptContextImpl(job,
getTaskID(),
reporter);
// make a mapper
// 使用反射 taskContext.getMapperClass() 取出 mapper Class
org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE> mapper =
(org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE>)
ReflectionUtils.newInstance(taskContext.getMapperClass(), job);
// make the input format
// 使用反射 得到 输入格式化类
org.apache.hadoop.mapreduce.InputFormat<INKEY,INVALUE> inputFormat =
(org.apache.hadoop.mapreduce.InputFormat<INKEY,INVALUE>)
ReflectionUtils.newInstance(taskContext.getInputFormatClass(), job);
// rebuild the input split
// 将切片信息反序列化重构成一个对象
// 客户端提交 配置信息+切片详单(序列化)+以及jar包
/*
输入端输入格式化切片清单:
map 端为输入对象创建输入读取器(默认 LineRecordReader )
* */
org.apache.hadoop.mapreduce.InputSplit split = null;
split = getSplitDetails(new Path(splitIndex.getSplitLocation()),
splitIndex.getStartOffset());
LOG.info("Processing split: " + split);
org.apache.hadoop.mapreduce.RecordReader<INKEY,INVALUE> input =
new NewTrackingRecordReader<INKEY,INVALUE>
(split, inputFormat, reporter, taskContext);
job.setBoolean(JobContext.SKIP_RECORDS, isSkipping());
org.apache.hadoop.mapreduce.RecordWriter output = null;
// get an output object
if (job.getNumReduceTasks() == 0) {
output =
new NewDirectOutputCollector(taskContext, job, umbilical, reporter);
} else {
// 得到输出对象 使用分区器进行分区
output = new NewOutputCollector(taskContext, job, umbilical, reporter);
}
//
org.apache.hadoop.mapreduce.MapContext<INKEY, INVALUE, OUTKEY, OUTVALUE>
mapContext =
new MapContextImpl<INKEY, INVALUE, OUTKEY, OUTVALUE>(job, getTaskID(),
input, output,
committer,
reporter, split);
org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE>.Context
mapperContext =
new WrappedMapper<INKEY, INVALUE, OUTKEY, OUTVALUE>().getMapContext(
mapContext);
try {
// 输入初始化
/*
初始化过程:
1,首先创建 HDFS 的输入流
2,将偏移量 seek 到自己的切片位置
3, 将自己的切片偏移量往下多移动一行,也就是多读一行
* */
// 调用 LineRecordReader 的 initialize
input.initialize(split, mapperContext);
// 调用 LineRecordReader 的 nextKeyValue
mapper.run(mapperContext);
mapPhase.complete();
setPhase(TaskStatus.Phase.SORT);
statusUpdate(umbilical);
input.close();
input = null;
// 输出关闭
output.close(mapperContext);
output = null;
} finally {
closeQuietly(input);
closeQuietly(output, mapperContext);
}
}
class DirectMapOutputCollector<K, V>
implements MapOutputCollector<K, V> {
private RecordWriter<K, V> out = null;
private TaskReporter reporter = null;
private Counters.Counter mapOutputRecordCounter;
private Counters.Counter fileOutputByteCounter;
private List<Statistics> fsStats;
public DirectMapOutputCollector() {
}
@SuppressWarnings("unchecked")
public void init(MapOutputCollector.Context context
) throws IOException, ClassNotFoundException {
this.reporter = context.getReporter();
JobConf job = context.getJobConf();
String finalName = getOutputName(getPartition());
FileSystem fs = FileSystem.get(job);
OutputFormat<K, V> outputFormat = job.getOutputFormat();
mapOutputRecordCounter = reporter.getCounter(TaskCounter.MAP_OUTPUT_RECORDS);
fileOutputByteCounter = reporter
.getCounter(FileOutputFormatCounter.BYTES_WRITTEN);
List<Statistics> matchedStats = null;
if (outputFormat instanceof FileOutputFormat) {
matchedStats = getFsStatistics(FileOutputFormat.getOutputPath(job), job);
}
fsStats = matchedStats;
long bytesOutPrev = getOutputBytes(fsStats);
out = job.getOutputFormat().getRecordWriter(fs, job, finalName, reporter);
long bytesOutCurr = getOutputBytes(fsStats);
fileOutputByteCounter.increment(bytesOutCurr - bytesOutPrev);
}
public void close() throws IOException {
if (this.out != null) {
long bytesOutPrev = getOutputBytes(fsStats);
out.close(this.reporter);
long bytesOutCurr = getOutputBytes(fsStats);
fileOutputByteCounter.increment(bytesOutCurr - bytesOutPrev);
}
}
public void flush() throws IOException, InterruptedException,
ClassNotFoundException {
}
public void collect(K key, V value, int partition) throws IOException {
reporter.progress();
long bytesOutPrev = getOutputBytes(fsStats);
out.write(key, value);
long bytesOutCurr = getOutputBytes(fsStats);
fileOutputByteCounter.increment(bytesOutCurr - bytesOutPrev);
mapOutputRecordCounter.increment(1);
}
private long getOutputBytes(List<Statistics> stats) {
if (stats == null) return 0;
long bytesWritten = 0;
for (Statistics stat: stats) {
bytesWritten = bytesWritten + stat.getBytesWritten();
}
return bytesWritten;
}
}
@InterfaceAudience.LimitedPrivate({"MapReduce"})
@InterfaceStability.Unstable
public static class MapOutputBuffer<K extends Object, V extends Object>
implements MapOutputCollector<K, V>, IndexedSortable {
private int partitions;
private JobConf job;
private TaskReporter reporter;
private Class<K> keyClass;
private Class<V> valClass;
private RawComparator<K> comparator;
private SerializationFactory serializationFactory;
private Serializer<K> keySerializer;
private Serializer<V> valSerializer;
private CombinerRunner<K,V> combinerRunner;
private CombineOutputCollector<K, V> combineCollector;
// Compression for map-outputs
private CompressionCodec codec;
// k/v accounting
private IntBuffer kvmeta; // metadata overlay on backing store
int kvstart; // marks origin of spill metadata
int kvend; // marks end of spill metadata
int kvindex; // marks end of fully serialized records
int equator; // marks origin of meta/serialization
int bufstart; // marks beginning of spill
int bufend; // marks beginning of collectable
int bufmark; // marks end of record
int bufindex; // marks end of collected
int bufvoid; // marks the point where we should stop
// reading at the end of the buffer
byte[] kvbuffer; // main output buffer
private final byte[] b0 = new byte[0];
private static final int VALSTART = 0; // val offset in acct
private static final int KEYSTART = 1; // key offset in acct
private static final int PARTITION = 2; // partition offset in acct
private static final int VALLEN = 3; // length of value
private static final int NMETA = 4; // num meta ints
private static final int METASIZE = NMETA * 4; // size in bytes
// spill accounting
private int maxRec;
private int softLimit;
boolean spillInProgress;;
int bufferRemaining;
volatile Throwable sortSpillException = null;
int numSpills = 0;
private int minSpillsForCombine;
private IndexedSorter sorter;
final ReentrantLock spillLock = new ReentrantLock();
final Condition spillDone = spillLock.newCondition();
final Condition spillReady = spillLock.newCondition();
final BlockingBuffer bb = new BlockingBuffer();
volatile boolean spillThreadRunning = false;
final SpillThread spillThread = new SpillThread();
private FileSystem rfs;
// Counters
private Counters.Counter mapOutputByteCounter;
private Counters.Counter mapOutputRecordCounter;
private Counters.Counter fileOutputByteCounter;
final ArrayList<SpillRecord> indexCacheList =
new ArrayList<SpillRecord>();
private int totalIndexCacheMemory;
private int indexCacheMemoryLimit;
private static final int INDEX_CACHE_MEMORY_LIMIT_DEFAULT = 1024 * 1024;
private MapTask mapTask;
private MapOutputFile mapOutputFile;
private Progress sortPhase;
private Counters.Counter spilledRecordsCounter;
public MapOutputBuffer() {
}
@SuppressWarnings("unchecked")
public void init(MapOutputCollector.Context context
) throws IOException, ClassNotFoundException {
job = context.getJobConf();
reporter = context.getReporter();
mapTask = context.getMapTask();
mapOutputFile = mapTask.getMapOutputFile();
sortPhase = mapTask.getSortPhase();
spilledRecordsCounter = reporter.getCounter(TaskCounter.SPILLED_RECORDS);
partitions = job.getNumReduceTasks();
rfs = ((LocalFileSystem)FileSystem.getLocal(job)).getRaw();
//sanity checks
// 100 指的是内存缓冲区大小
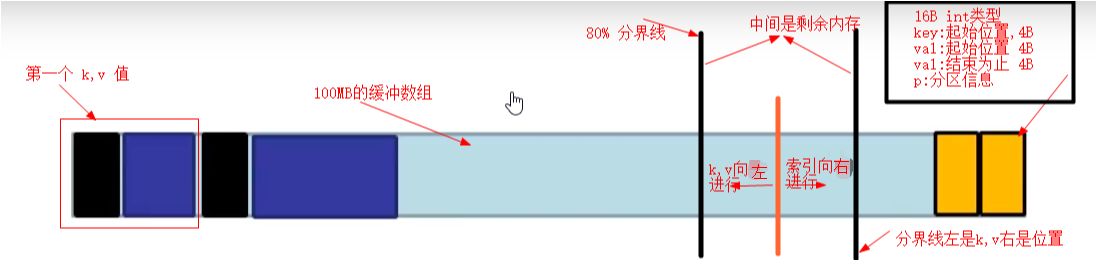
// 80% 指的是 如果超过内存缓冲区大小 80% 那么就溢写到磁盘(80%的部分), 是为了能够使溢写与取出并行效果
final float spillper =
job.getFloat(JobContext.MAP_SORT_SPILL_PERCENT, (float)0.8);
final int sortmb = job.getInt(JobContext.IO_SORT_MB, 100);
indexCacheMemoryLimit = job.getInt(JobContext.INDEX_CACHE_MEMORY_LIMIT,
INDEX_CACHE_MEMORY_LIMIT_DEFAULT);
if (spillper > (float)1.0 || spillper <= (float)0.0) {
throw new IOException("Invalid \"" + JobContext.MAP_SORT_SPILL_PERCENT +
"\": " + spillper);
}
if ((sortmb & 0x7FF) != sortmb) {
throw new IOException(
"Invalid \"" + JobContext.IO_SORT_MB + "\": " + sortmb);
}
// 排序器 默认是快排算法 在内存缓冲区溢写的过程之前进行, 溢写是写到文件之中, 此时的排序是保证文件的内部有序
sorter = ReflectionUtils.newInstance(job.getClass("map.sort.class",
QuickSort.class, IndexedSorter.class), job);
// buffers and accounting
int maxMemUsage = sortmb << 20;
maxMemUsage -= maxMemUsage % METASIZE;
kvbuffer = new byte[maxMemUsage];
bufvoid = kvbuffer.length;
kvmeta = ByteBuffer.wrap(kvbuffer)
.order(ByteOrder.nativeOrder())
.asIntBuffer();
setEquator(0);
bufstart = bufend = bufindex = equator;
kvstart = kvend = kvindex;
maxRec = kvmeta.capacity() / NMETA;
softLimit = (int)(kvbuffer.length * spillper);
bufferRemaining = softLimit;
LOG.info(JobContext.IO_SORT_MB + ": " + sortmb);
LOG.info("soft limit at " + softLimit);
LOG.info("bufstart = " + bufstart + "; bufvoid = " + bufvoid);
LOG.info("kvstart = " + kvstart + "; length = " + maxRec);
// k/v serialization
// 比较器(排序器使用) 用户设置去用户 JobContext.KEY_COMPARATOR , 如果没有配置去 k自身的比较器
comparator = job.getOutputKeyComparator();
keyClass = (Class<K>)job.getMapOutputKeyClass();
valClass = (Class<V>)job.getMapOutputValueClass();
serializationFactory = new SerializationFactory(job);
keySerializer = serializationFactory.getSerializer(keyClass);
keySerializer.open(bb);
valSerializer = serializationFactory.getSerializer(valClass);
valSerializer.open(bb);
// output counters
mapOutputByteCounter = reporter.getCounter(TaskCounter.MAP_OUTPUT_BYTES);
mapOutputRecordCounter =
reporter.getCounter(TaskCounter.MAP_OUTPUT_RECORDS);
fileOutputByteCounter = reporter
.getCounter(TaskCounter.MAP_OUTPUT_MATERIALIZED_BYTES);
// compression
if (job.getCompressMapOutput()) {
Class<? extends CompressionCodec> codecClass =
job.getMapOutputCompressorClass(DefaultCodec.class);
codec = ReflectionUtils.newInstance(codecClass, job);
} else {
codec = null;
}
// combiner
// map 之中的 'reduce' , 可以使用 combiner 来先行聚合(数据来自一个map程序的数据)一次,
final Counters.Counter combineInputCounter =
reporter.getCounter(TaskCounter.COMBINE_INPUT_RECORDS);
combinerRunner = CombinerRunner.create(job, getTaskID(),
combineInputCounter,
reporter, null);
if (combinerRunner != null) {
final Counters.Counter combineOutputCounter =
reporter.getCounter(TaskCounter.COMBINE_OUTPUT_RECORDS);
combineCollector= new CombineOutputCollector<K,V>(combineOutputCounter, reporter, job);
} else {
combineCollector = null;
}
spillInProgress = false;
// 3 代表是 map 进行聚合(reduce 之前), 配置的 文件大小,如果大于三, 继续调用 combiner,知道不能合并为止
minSpillsForCombine = job.getInt(JobContext.MAP_COMBINE_MIN_SPILLS, 3);
spillThread.setDaemon(true);
// 溢写线程(指的是 缓冲区的溢写与输出是异步的)
spillThread.setName("SpillThread");
spillLock.lock();
try {
spillThread.start();
while (!spillThreadRunning) {
spillDone.await();
}
} catch (InterruptedException e) {
throw new IOException("Spill thread failed to initialize", e);
} finally {
spillLock.unlock();
}
if (sortSpillException != null) {
throw new IOException("Spill thread failed to initialize",
sortSpillException);
}
}
/**
* Serialize the key, value to intermediate storage.
* When this method returns, kvindex must refer to sufficient unused
* storage to store one METADATA.
*/
public synchronized void collect(K key, V value, final int partition
) throws IOException {
reporter.progress();
if (key.getClass() != keyClass) {
throw new IOException("Type mismatch in key from map: expected "
+ keyClass.getName() + ", received "
+ key.getClass().getName());
}
if (value.getClass() != valClass) {
throw new IOException("Type mismatch in value from map: expected "
+ valClass.getName() + ", received "
+ value.getClass().getName());
}
if (partition < 0 || partition >= partitions) {
throw new IOException("Illegal partition for " + key + " (" +
partition + ")");
}
checkSpillException();
bufferRemaining -= METASIZE;
if (bufferRemaining <= 0) {
// start spill if the thread is not running and the soft limit has been
// reached
spillLock.lock();
try {
do {
if (!spillInProgress) {
final int kvbidx = 4 * kvindex;
final int kvbend = 4 * kvend;
// serialized, unspilled bytes always lie between kvindex and
// bufindex, crossing the equator. Note that any void space
// created by a reset must be included in "used" bytes
final int bUsed = distanceTo(kvbidx, bufindex);
final boolean bufsoftlimit = bUsed >= softLimit;
if ((kvbend + METASIZE) % kvbuffer.length !=
equator - (equator % METASIZE)) {
// spill finished, reclaim space
resetSpill();
bufferRemaining = Math.min(
distanceTo(bufindex, kvbidx) - 2 * METASIZE,
softLimit - bUsed) - METASIZE;
continue;
} else if (bufsoftlimit && kvindex != kvend) {
// spill records, if any collected; check latter, as it may
// be possible for metadata alignment to hit spill pcnt
startSpill();
final int avgRec = (int)
(mapOutputByteCounter.getCounter() /
mapOutputRecordCounter.getCounter());
// leave at least half the split buffer for serialization data
// ensure that kvindex >= bufindex
final int distkvi = distanceTo(bufindex, kvbidx);
final int newPos = (bufindex +
Math.max(2 * METASIZE - 1,
Math.min(distkvi / 2,
distkvi / (METASIZE + avgRec) * METASIZE)))
% kvbuffer.length;
setEquator(newPos);
bufmark = bufindex = newPos;
final int serBound = 4 * kvend;
// bytes remaining before the lock must be held and limits
// checked is the minimum of three arcs: the metadata space, the
// serialization space, and the soft limit
bufferRemaining = Math.min(
// metadata max
distanceTo(bufend, newPos),
Math.min(
// serialization max
distanceTo(newPos, serBound),
// soft limit
softLimit)) - 2 * METASIZE;
}
}
} while (false);
} finally {
spillLock.unlock();
}
}
try {
// serialize key bytes into buffer
int keystart = bufindex;
// 对 key 值进行序列化操作
keySerializer.serialize(key);
if (bufindex < keystart) {
// wrapped the key; must make contiguous
bb.shiftBufferedKey();
keystart = 0;
}
// serialize value bytes into buffer
final int valstart = bufindex;
valSerializer.serialize(value);
// It's possible for records to have zero length, i.e. the serializer
// will perform no writes. To ensure that the boundary conditions are
// checked and that the kvindex invariant is maintained, perform a
// zero-length write into the buffer. The logic monitoring this could be
// moved into collect, but this is cleaner and inexpensive. For now, it
// is acceptable.
bb.write(b0, 0, 0);
// the record must be marked after the preceding write, as the metadata
// for this record are not yet written
int valend = bb.markRecord();
mapOutputRecordCounter.increment(1);
mapOutputByteCounter.increment(
distanceTo(keystart, valend, bufvoid));
// write accounting info
kvmeta.put(kvindex + PARTITION, partition);
kvmeta.put(kvindex + KEYSTART, keystart);
kvmeta.put(kvindex + VALSTART, valstart);
kvmeta.put(kvindex + VALLEN, distanceTo(valstart, valend));
// advance kvindex
kvindex = (kvindex - NMETA + kvmeta.capacity()) % kvmeta.capacity();
} catch (MapBufferTooSmallException e) {
LOG.info("Record too large for in-memory buffer: " + e.getMessage());
spillSingleRecord(key, value, partition);
mapOutputRecordCounter.increment(1);
return;
}
}
private TaskAttemptID getTaskID() {
return mapTask.getTaskID();
}
/**
* Set the point from which meta and serialization data expand. The meta
* indices are aligned with the buffer, so metadata never spans the ends of
* the circular buffer.
*/
private void setEquator(int pos) {
equator = pos;
// set index prior to first entry, aligned at meta boundary
final int aligned = pos - (pos % METASIZE);
// Cast one of the operands to long to avoid integer overflow
kvindex = (int)
(((long)aligned - METASIZE + kvbuffer.length) % kvbuffer.length) / 4;
LOG.info("(EQUATOR) " + pos + " kvi " + kvindex +
"(" + (kvindex * 4) + ")");
}
/**
* The spill is complete, so set the buffer and meta indices to be equal to
* the new equator to free space for continuing collection. Note that when
* kvindex == kvend == kvstart, the buffer is empty.
*/
private void resetSpill() {
final int e = equator;
bufstart = bufend = e;
final int aligned = e - (e % METASIZE);
// set start/end to point to first meta record
// Cast one of the operands to long to avoid integer overflow
kvstart = kvend = (int)
(((long)aligned - METASIZE + kvbuffer.length) % kvbuffer.length) / 4;
LOG.info("(RESET) equator " + e + " kv " + kvstart + "(" +
(kvstart * 4) + ")" + " kvi " + kvindex + "(" + (kvindex * 4) + ")");
}
/**
* Compute the distance in bytes between two indices in the serialization
* buffer.
* @see #distanceTo(int,int,int)
*/
final int distanceTo(final int i, final int j) {
return distanceTo(i, j, kvbuffer.length);
}
/**
* Compute the distance between two indices in the circular buffer given the
* max distance.
*/
int distanceTo(final int i, final int j, final int mod) {
return i <= j
? j - i
: mod - i + j;
}
/**
* For the given meta position, return the offset into the int-sized
* kvmeta buffer.
*/
int offsetFor(int metapos) {
return metapos * NMETA;
}
/**
* Compare logical range, st i, j MOD offset capacity.
* Compare by partition, then by key.
* @see IndexedSortable#compare
*/
public int compare(final int mi, final int mj) {
final int kvi = offsetFor(mi % maxRec);
final int kvj = offsetFor(mj % maxRec);
final int kvip = kvmeta.get(kvi + PARTITION);
final int kvjp = kvmeta.get(kvj + PARTITION);
// sort by partition
if (kvip != kvjp) {
return kvip - kvjp;
}
// sort by key
return comparator.compare(kvbuffer,
kvmeta.get(kvi + KEYSTART),
kvmeta.get(kvi + VALSTART) - kvmeta.get(kvi + KEYSTART),
kvbuffer,
kvmeta.get(kvj + KEYSTART),
kvmeta.get(kvj + VALSTART) - kvmeta.get(kvj + KEYSTART));
}
final byte META_BUFFER_TMP[] = new byte[METASIZE];
/**
* Swap metadata for items i, j
* @see IndexedSortable#swap
*/
public void swap(final int mi, final int mj) {
int iOff = (mi % maxRec) * METASIZE;
int jOff = (mj % maxRec) * METASIZE;
System.arraycopy(kvbuffer, iOff, META_BUFFER_TMP, 0, METASIZE);
System.arraycopy(kvbuffer, jOff, kvbuffer, iOff, METASIZE);
System.arraycopy(META_BUFFER_TMP, 0, kvbuffer, jOff, METASIZE);
}
/**
* Inner class managing the spill of serialized records to disk.
*/
protected class BlockingBuffer extends DataOutputStream {
public BlockingBuffer() {
super(new Buffer());
}
/**
* Mark end of record. Note that this is required if the buffer is to
* cut the spill in the proper place.
*/
public int markRecord() {
bufmark = bufindex;
return bufindex;
}
/**
* Set position from last mark to end of writable buffer, then rewrite
* the data between last mark and kvindex.
* This handles a special case where the key wraps around the buffer.
* If the key is to be passed to a RawComparator, then it must be
* contiguous in the buffer. This recopies the data in the buffer back
* into itself, but starting at the beginning of the buffer. Note that
* this method should <b>only</b> be called immediately after detecting
* this condition. To call it at any other time is undefined and would
* likely result in data loss or corruption.
* @see #markRecord()
*/
protected void shiftBufferedKey() throws IOException {
// spillLock unnecessary; both kvend and kvindex are current
int headbytelen = bufvoid - bufmark;
bufvoid = bufmark;
final int kvbidx = 4 * kvindex;
final int kvbend = 4 * kvend;
final int avail =
Math.min(distanceTo(0, kvbidx), distanceTo(0, kvbend));
if (bufindex + headbytelen < avail) {
System.arraycopy(kvbuffer, 0, kvbuffer, headbytelen, bufindex);
System.arraycopy(kvbuffer, bufvoid, kvbuffer, 0, headbytelen);
bufindex += headbytelen;
bufferRemaining -= kvbuffer.length - bufvoid;
} else {
byte[] keytmp = new byte[bufindex];
System.arraycopy(kvbuffer, 0, keytmp, 0, bufindex);
bufindex = 0;
out.write(kvbuffer, bufmark, headbytelen);
out.write(keytmp);
}
}
}
public class Buffer extends OutputStream {
private final byte[] scratch = new byte[1];
@Override
public void write(int v)
throws IOException {
scratch[0] = (byte)v;
write(scratch, 0, 1);
}
/**
* Attempt to write a sequence of bytes to the collection buffer.
* This method will block if the spill thread is running and it
* cannot write.
* @throws MapBufferTooSmallException if record is too large to
* deserialize into the collection buffer.
*/
@Override
public void write(byte b[], int off, int len)
throws IOException {
// must always verify the invariant that at least METASIZE bytes are
// available beyond kvindex, even when len == 0
bufferRemaining -= len;
if (bufferRemaining <= 0) {
// writing these bytes could exhaust available buffer space or fill
// the buffer to soft limit. check if spill or blocking are necessary
boolean blockwrite = false;
spillLock.lock();
try {
do {
checkSpillException();
final int kvbidx = 4 * kvindex;
final int kvbend = 4 * kvend;
// ser distance to key index
final int distkvi = distanceTo(bufindex, kvbidx);
// ser distance to spill end index
final int distkve = distanceTo(bufindex, kvbend);
// if kvindex is closer than kvend, then a spill is neither in
// progress nor complete and reset since the lock was held. The
// write should block only if there is insufficient space to
// complete the current write, write the metadata for this record,
// and write the metadata for the next record. If kvend is closer,
// then the write should block if there is too little space for
// either the metadata or the current write. Note that collect
// ensures its metadata requirement with a zero-length write
blockwrite = distkvi <= distkve
? distkvi <= len + 2 * METASIZE
: distkve <= len || distanceTo(bufend, kvbidx) < 2 * METASIZE;
if (!spillInProgress) {
if (blockwrite) {
if ((kvbend + METASIZE) % kvbuffer.length !=
equator - (equator % METASIZE)) {
// spill finished, reclaim space
// need to use meta exclusively; zero-len rec & 100% spill
// pcnt would fail
resetSpill(); // resetSpill doesn't move bufindex, kvindex
bufferRemaining = Math.min(
distkvi - 2 * METASIZE,
softLimit - distanceTo(kvbidx, bufindex)) - len;
continue;
}
// we have records we can spill; only spill if blocked
if (kvindex != kvend) {
startSpill();
// Blocked on this write, waiting for the spill just
// initiated to finish. Instead of repositioning the marker
// and copying the partial record, we set the record start
// to be the new equator
setEquator(bufmark);
} else {
// We have no buffered records, and this record is too large
// to write into kvbuffer. We must spill it directly from
// collect
final int size = distanceTo(bufstart, bufindex) + len;
setEquator(0);
bufstart = bufend = bufindex = equator;
kvstart = kvend = kvindex;
bufvoid = kvbuffer.length;
throw new MapBufferTooSmallException(size + " bytes");
}
}
}
if (blockwrite) {
// wait for spill
try {
while (spillInProgress) {
reporter.progress();
spillDone.await();
}
} catch (InterruptedException e) {
throw new IOException(
"Buffer interrupted while waiting for the writer", e);
}
}
} while (blockwrite);
} finally {
spillLock.unlock();
}
}
// here, we know that we have sufficient space to write
if (bufindex + len > bufvoid) {
final int gaplen = bufvoid - bufindex;
System.arraycopy(b, off, kvbuffer, bufindex, gaplen);
len -= gaplen;
off += gaplen;
bufindex = 0;
}
System.arraycopy(b, off, kvbuffer, bufindex, len);
bufindex += len;
}
}
public void flush() throws IOException, ClassNotFoundException,
InterruptedException {
LOG.info("Starting flush of map output");
if (kvbuffer == null) {
LOG.info("kvbuffer is null. Skipping flush.");
return;
}
spillLock.lock();
try {
while (spillInProgress) {
reporter.progress();
spillDone.await();
}
checkSpillException();
final int kvbend = 4 * kvend;
if ((kvbend + METASIZE) % kvbuffer.length !=
equator - (equator % METASIZE)) {
// spill finished
resetSpill();
}
if (kvindex != kvend) {
kvend = (kvindex + NMETA) % kvmeta.capacity();
bufend = bufmark;
LOG.info("Spilling map output");
LOG.info("bufstart = " + bufstart + "; bufend = " + bufmark +
"; bufvoid = " + bufvoid);
LOG.info("kvstart = " + kvstart + "(" + (kvstart * 4) +
"); kvend = " + kvend + "(" + (kvend * 4) +
"); length = " + (distanceTo(kvend, kvstart,
kvmeta.capacity()) + 1) + "/" + maxRec);
sortAndSpill();
}
} catch (InterruptedException e) {
throw new IOException("Interrupted while waiting for the writer", e);
} finally {
spillLock.unlock();
}
assert !spillLock.isHeldByCurrentThread();
// shut down spill thread and wait for it to exit. Since the preceding
// ensures that it is finished with its work (and sortAndSpill did not
// throw), we elect to use an interrupt instead of setting a flag.
// Spilling simultaneously from this thread while the spill thread
// finishes its work might be both a useful way to extend this and also
// sufficient motivation for the latter approach.
try {
spillThread.interrupt();
spillThread.join();
} catch (InterruptedException e) {
throw new IOException("Spill failed", e);
}
// release sort buffer before the merge
kvbuffer = null;
mergeParts();
Path outputPath = mapOutputFile.getOutputFile();
fileOutputByteCounter.increment(rfs.getFileStatus(outputPath).getLen());
}
public void close() { }
protected class SpillThread extends Thread {
@Override
public void run() {
spillLock.lock();
spillThreadRunning = true;
try {
while (true) {
spillDone.signal();
while (!spillInProgress) {
spillReady.await();
}
try {
spillLock.unlock();
sortAndSpill();
} catch (Throwable t) {
sortSpillException = t;
} finally {
spillLock.lock();
if (bufend < bufstart) {
bufvoid = kvbuffer.length;
}
kvstart = kvend;
bufstart = bufend;
spillInProgress = false;
}
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
} finally {
spillLock.unlock();
spillThreadRunning = false;
}
}
}
private void checkSpillException() throws IOException {
final Throwable lspillException = sortSpillException;
if (lspillException != null) {
if (lspillException instanceof Error) {
final String logMsg = "Task " + getTaskID() + " failed : " +
StringUtils.stringifyException(lspillException);
mapTask.reportFatalError(getTaskID(), lspillException, logMsg);
}
throw new IOException("Spill failed", lspillException);
}
}
private void startSpill() {
assert !spillInProgress;
kvend = (kvindex + NMETA) % kvmeta.capacity();
bufend = bufmark;
spillInProgress = true;
LOG.info("Spilling map output");
LOG.info("bufstart = " + bufstart + "; bufend = " + bufmark +
"; bufvoid = " + bufvoid);
LOG.info("kvstart = " + kvstart + "(" + (kvstart * 4) +
"); kvend = " + kvend + "(" + (kvend * 4) +
"); length = " + (distanceTo(kvend, kvstart,
kvmeta.capacity()) + 1) + "/" + maxRec);
spillReady.signal();
}
private void sortAndSpill() throws IOException, ClassNotFoundException,
InterruptedException {
//approximate the length of the output file to be the length of the
//buffer + header lengths for the partitions
final long size = distanceTo(bufstart, bufend, bufvoid) +
partitions * APPROX_HEADER_LENGTH;
FSDataOutputStream out = null;
try {
// create spill file
final SpillRecord spillRec = new SpillRecord(partitions);
final Path filename =
mapOutputFile.getSpillFileForWrite(numSpills, size);
out = rfs.create(filename);
final int mstart = kvend / NMETA;
final int mend = 1 + // kvend is a valid record
(kvstart >= kvend
? kvstart
: kvmeta.capacity() + kvstart) / NMETA;
sorter.sort(MapOutputBuffer.this, mstart, mend, reporter);
int spindex = mstart;
final IndexRecord rec = new IndexRecord();
final InMemValBytes value = new InMemValBytes();
for (int i = 0; i < partitions; ++i) {
IFile.Writer<K, V> writer = null;
try {
long segmentStart = out.getPos();
FSDataOutputStream partitionOut = CryptoUtils.wrapIfNecessary(job, out);
writer = new Writer<K, V>(job, partitionOut, keyClass, valClass, codec,
spilledRecordsCounter);
if (combinerRunner == null) {
// spill directly
DataInputBuffer key = new DataInputBuffer();
while (spindex < mend &&
kvmeta.get(offsetFor(spindex % maxRec) + PARTITION) == i) {
final int kvoff = offsetFor(spindex % maxRec);
int keystart = kvmeta.get(kvoff + KEYSTART);
int valstart = kvmeta.get(kvoff + VALSTART);
key.reset(kvbuffer, keystart, valstart - keystart);
getVBytesForOffset(kvoff, value);
writer.append(key, value);
++spindex;
}
} else {
int spstart = spindex;
while (spindex < mend &&
kvmeta.get(offsetFor(spindex % maxRec)
+ PARTITION) == i) {
++spindex;
}
// Note: we would like to avoid the combiner if we've fewer
// than some threshold of records for a partition
if (spstart != spindex) {
combineCollector.setWriter(writer);
RawKeyValueIterator kvIter =
new MRResultIterator(spstart, spindex);
combinerRunner.combine(kvIter, combineCollector);
}
}
// close the writer
writer.close();
// record offsets
rec.startOffset = segmentStart;
rec.rawLength = writer.getRawLength() + CryptoUtils.cryptoPadding(job);
rec.partLength = writer.getCompressedLength() + CryptoUtils.cryptoPadding(job);
spillRec.putIndex(rec, i);
writer = null;
} finally {
if (null != writer) writer.close();
}
}
if (totalIndexCacheMemory >= indexCacheMemoryLimit) {
// create spill index file
Path indexFilename =
mapOutputFile.getSpillIndexFileForWrite(numSpills, partitions
* MAP_OUTPUT_INDEX_RECORD_LENGTH);
spillRec.writeToFile(indexFilename, job);
} else {
indexCacheList.add(spillRec);
totalIndexCacheMemory +=
spillRec.size() * MAP_OUTPUT_INDEX_RECORD_LENGTH;
}
LOG.info("Finished spill " + numSpills);
++numSpills;
} finally {
if (out != null) out.close();
}
}
/**
* Handles the degenerate case where serialization fails to fit in
* the in-memory buffer, so we must spill the record from collect
* directly to a spill file. Consider this "losing".
*/
private void spillSingleRecord(final K key, final V value,
int partition) throws IOException {
long size = kvbuffer.length + partitions * APPROX_HEADER_LENGTH;
FSDataOutputStream out = null;
try {
// create spill file
final SpillRecord spillRec = new SpillRecord(partitions);
final Path filename =
mapOutputFile.getSpillFileForWrite(numSpills, size);
out = rfs.create(filename);
// we don't run the combiner for a single record
IndexRecord rec = new IndexRecord();
for (int i = 0; i < partitions; ++i) {
IFile.Writer<K, V> writer = null;
try {
long segmentStart = out.getPos();
// Create a new codec, don't care!
FSDataOutputStream partitionOut = CryptoUtils.wrapIfNecessary(job, out);
writer = new IFile.Writer<K,V>(job, partitionOut, keyClass, valClass, codec,
spilledRecordsCounter);
if (i == partition) {
final long recordStart = out.getPos();
writer.append(key, value);
// Note that our map byte count will not be accurate with
// compression
mapOutputByteCounter.increment(out.getPos() - recordStart);
}
writer.close();
// record offsets
rec.startOffset = segmentStart;
rec.rawLength = writer.getRawLength() + CryptoUtils.cryptoPadding(job);
rec.partLength = writer.getCompressedLength() + CryptoUtils.cryptoPadding(job);
spillRec.putIndex(rec, i);
writer = null;
} catch (IOException e) {
if (null != writer) writer.close();
throw e;
}
}
if (totalIndexCacheMemory >= indexCacheMemoryLimit) {
// create spill index file
Path indexFilename =
mapOutputFile.getSpillIndexFileForWrite(numSpills, partitions
* MAP_OUTPUT_INDEX_RECORD_LENGTH);
spillRec.writeToFile(indexFilename, job);
} else {
indexCacheList.add(spillRec);
totalIndexCacheMemory +=
spillRec.size() * MAP_OUTPUT_INDEX_RECORD_LENGTH;
}
++numSpills;
} finally {
if (out != null) out.close();
}
}
/**
* Given an offset, populate vbytes with the associated set of
* deserialized value bytes. Should only be called during a spill.
*/
private void getVBytesForOffset(int kvoff, InMemValBytes vbytes) {
// get the keystart for the next serialized value to be the end
// of this value. If this is the last value in the buffer, use bufend
final int vallen = kvmeta.get(kvoff + VALLEN);
assert vallen >= 0;
vbytes.reset(kvbuffer, kvmeta.get(kvoff + VALSTART), vallen);
}
/**
* Inner class wrapping valuebytes, used for appendRaw.
*/
protected class InMemValBytes extends DataInputBuffer {
private byte[] buffer;
private int start;
private int length;
public void reset(byte[] buffer, int start, int length) {
this.buffer = buffer;
this.start = start;
this.length = length;
if (start + length > bufvoid) {
this.buffer = new byte[this.length];
final int taillen = bufvoid - start;
System.arraycopy(buffer, start, this.buffer, 0, taillen);
System.arraycopy(buffer, 0, this.buffer, taillen, length-taillen);
this.start = 0;
}
super.reset(this.buffer, this.start, this.length);
}
}
protected class MRResultIterator implements RawKeyValueIterator {
private final DataInputBuffer keybuf = new DataInputBuffer();
private final InMemValBytes vbytes = new InMemValBytes();
private final int end;
private int current;
public MRResultIterator(int start, int end) {
this.end = end;
current = start - 1;
}
public boolean next() throws IOException {
return ++current < end;
}
public DataInputBuffer getKey() throws IOException {
final int kvoff = offsetFor(current % maxRec);
keybuf.reset(kvbuffer, kvmeta.get(kvoff + KEYSTART),
kvmeta.get(kvoff + VALSTART) - kvmeta.get(kvoff + KEYSTART));
return keybuf;
}
public DataInputBuffer getValue() throws IOException {
getVBytesForOffset(offsetFor(current % maxRec), vbytes);
return vbytes;
}
public Progress getProgress() {
return null;
}
public void close() { }
}
private void mergeParts() throws IOException, InterruptedException,
ClassNotFoundException {
// get the approximate size of the final output/index files
long finalOutFileSize = 0;
long finalIndexFileSize = 0;
final Path[] filename = new Path[numSpills];
final TaskAttemptID mapId = getTaskID();
for(int i = 0; i < numSpills; i++) {
filename[i] = mapOutputFile.getSpillFile(i);
finalOutFileSize += rfs.getFileStatus(filename[i]).getLen();
}
if (numSpills == 1) { //the spill is the final output
sameVolRename(filename[0],
mapOutputFile.getOutputFileForWriteInVolume(filename[0]));
if (indexCacheList.size() == 0) {
sameVolRename(mapOutputFile.getSpillIndexFile(0),
mapOutputFile.getOutputIndexFileForWriteInVolume(filename[0]));
} else {
indexCacheList.get(0).writeToFile(
mapOutputFile.getOutputIndexFileForWriteInVolume(filename[0]), job);
}
sortPhase.complete();
return;
}
// read in paged indices
for (int i = indexCacheList.size(); i < numSpills; ++i) {
Path indexFileName = mapOutputFile.getSpillIndexFile(i);
indexCacheList.add(new SpillRecord(indexFileName, job));
}
//make correction in the length to include the sequence file header
//lengths for each partition
finalOutFileSize += partitions * APPROX_HEADER_LENGTH;
finalIndexFileSize = partitions * MAP_OUTPUT_INDEX_RECORD_LENGTH;
Path finalOutputFile =
mapOutputFile.getOutputFileForWrite(finalOutFileSize);
Path finalIndexFile =
mapOutputFile.getOutputIndexFileForWrite(finalIndexFileSize);
//The output stream for the final single output file
FSDataOutputStream finalOut = rfs.create(finalOutputFile, true, 4096);
if (numSpills == 0) {
//create dummy files
IndexRecord rec = new IndexRecord();
SpillRecord sr = new SpillRecord(partitions);
try {
for (int i = 0; i < partitions; i++) {
long segmentStart = finalOut.getPos();
FSDataOutputStream finalPartitionOut = CryptoUtils.wrapIfNecessary(job, finalOut);
Writer<K, V> writer =
new Writer<K, V>(job, finalPartitionOut, keyClass, valClass, codec, null);
writer.close();
rec.startOffset = segmentStart;
rec.rawLength = writer.getRawLength() + CryptoUtils.cryptoPadding(job);
rec.partLength = writer.getCompressedLength() + CryptoUtils.cryptoPadding(job);
sr.putIndex(rec, i);
}
sr.writeToFile(finalIndexFile, job);
} finally {
finalOut.close();
}
sortPhase.complete();
return;
}
{
sortPhase.addPhases(partitions); // Divide sort phase into sub-phases
IndexRecord rec = new IndexRecord();
final SpillRecord spillRec = new SpillRecord(partitions);
for (int parts = 0; parts < partitions; parts++) {
//create the segments to be merged
List<Segment<K,V>> segmentList =
new ArrayList<Segment<K, V>>(numSpills);
for(int i = 0; i < numSpills; i++) {
IndexRecord indexRecord = indexCacheList.get(i).getIndex(parts);
Segment<K,V> s =
new Segment<K,V>(job, rfs, filename[i], indexRecord.startOffset,
indexRecord.partLength, codec, true);
segmentList.add(i, s);
if (LOG.isDebugEnabled()) {
LOG.debug("MapId=" + mapId + " Reducer=" + parts +
"Spill =" + i + "(" + indexRecord.startOffset + "," +
indexRecord.rawLength + ", " + indexRecord.partLength + ")");
}
}
int mergeFactor = job.getInt(JobContext.IO_SORT_FACTOR, 100);
// sort the segments only if there are intermediate merges
boolean sortSegments = segmentList.size() > mergeFactor;
//merge
@SuppressWarnings("unchecked")
RawKeyValueIterator kvIter = Merger.merge(job, rfs,
keyClass, valClass, codec,
segmentList, mergeFactor,
new Path(mapId.toString()),
job.getOutputKeyComparator(), reporter, sortSegments,
null, spilledRecordsCounter, sortPhase.phase(),
TaskType.MAP);
//write merged output to disk
long segmentStart = finalOut.getPos();
FSDataOutputStream finalPartitionOut = CryptoUtils.wrapIfNecessary(job, finalOut);
Writer<K, V> writer =
new Writer<K, V>(job, finalPartitionOut, keyClass, valClass, codec,
spilledRecordsCounter);
if (combinerRunner == null || numSpills < minSpillsForCombine) {
Merger.writeFile(kvIter, writer, reporter, job);
} else {
// combineCollector 再次调用
combineCollector.setWriter(writer);
combinerRunner.combine(kvIter, combineCollector);
}
//close
writer.close();
sortPhase.startNextPhase();
// record offsets
rec.startOffset = segmentStart;
rec.rawLength = writer.getRawLength() + CryptoUtils.cryptoPadding(job);
rec.partLength = writer.getCompressedLength() + CryptoUtils.cryptoPadding(job);
spillRec.putIndex(rec, parts);
}
spillRec.writeToFile(finalIndexFile, job);
finalOut.close();
for(int i = 0; i < numSpills; i++) {
rfs.delete(filename[i],true);
}
}
}
/**
* Rename srcPath to dstPath on the same volume. This is the same
* as RawLocalFileSystem's rename method, except that it will not
* fall back to a copy, and it will create the target directory
* if it doesn't exist.
*/
private void sameVolRename(Path srcPath,
Path dstPath) throws IOException {
RawLocalFileSystem rfs = (RawLocalFileSystem)this.rfs;
File src = rfs.pathToFile(srcPath);
File dst = rfs.pathToFile(dstPath);
if (!dst.getParentFile().exists()) {
if (!dst.getParentFile().mkdirs()) {
throw new IOException("Unable to rename " + src + " to "
+ dst + ": couldn't create parent directory");
}
}
if (!src.renameTo(dst)) {
throw new IOException("Unable to rename " + src + " to " + dst);
}
}
} // MapOutputBuffer
/**
* Exception indicating that the allocated sort buffer is insufficient
* to hold the current record.
*/
@SuppressWarnings("serial")
private static class MapBufferTooSmallException extends IOException {
public MapBufferTooSmallException(String s) {
super(s);
}
}
private <INKEY,INVALUE,OUTKEY,OUTVALUE>
void closeQuietly(RecordReader<INKEY, INVALUE> c) {
if (c != null) {
try {
c.close();
} catch (IOException ie) {
// Ignore
LOG.info("Ignoring exception during close for " + c, ie);
}
}
}
private <OUTKEY, OUTVALUE>
void closeQuietly(MapOutputCollector<OUTKEY, OUTVALUE> c) {
if (c != null) {
try {
c.close();
} catch (Exception ie) {
// Ignore
LOG.info("Ignoring exception during close for " + c, ie);
}
}
}
private <INKEY, INVALUE, OUTKEY, OUTVALUE>
void closeQuietly(
org.apache.hadoop.mapreduce.RecordReader<INKEY, INVALUE> c) {
if (c != null) {
try {
c.close();
} catch (Exception ie) {
// Ignore
LOG.info("Ignoring exception during close for " + c, ie);
}
}
}
private <INKEY, INVALUE, OUTKEY, OUTVALUE>
void closeQuietly(
org.apache.hadoop.mapreduce.RecordWriter<OUTKEY, OUTVALUE> c,
org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE>.Context
mapperContext) {
if (c != null) {
try {
c.close(mapperContext);
} catch (Exception ie) {
// Ignore
LOG.info("Ignoring exception during close for " + c, ie);
}
}
}
}



 浙公网安备 33010602011771号
浙公网安备 33010602011771号