一,HBASE 数据库
1,非关系型数据库
2,hadoop databases 简称 hbase ,是一个高可靠性,高性能,面向列(按照列,在添加数据时候,进行创建表结构),可伸缩,实时读写的分布式数据库
3,主要是用来存储非结构化和半结构化的松散模型
二,数据模型
Row Key:
1,row key是用来检索记录的主键
2,决定一行数据
3,按照字典进行排序
4,只能存储 64K 字节数据
time Stamp:
1,时间戳,标注版本,每一个 cell 存储单元对同一个数据有多个版本,根据唯一的时间戳来区分版本的差异,按照时间来倒叙,最新的在最前面
2,时间戳类型是 64位整型
3,时间戳可以hbase 自动赋值,此时是精确到毫秒的系统时间
4,可以自定义,保证唯一性,避免版本冲突
Column Family 列族(处理最小单位) qualifier 列 :
1, HBASE 每列都属于一个列族,列族必须作为表模式定义的一部分预先给出
2, 列明以列族为前缀,每个列族有多个列成员
3, hbase 之中把同一列族里面的数据存储同一目录下,由几个文件保存
4, 权限控制,存储以及调优都是在列族的层面进行的
cell 单元格
1,由行和列交叉决定, Row Key + CF +列名称+ version
2,区别在于列,是有版本的
3,没有类型,全部是字节码形式存储
hlog(WAL log)
1,写入了数据的归属信息
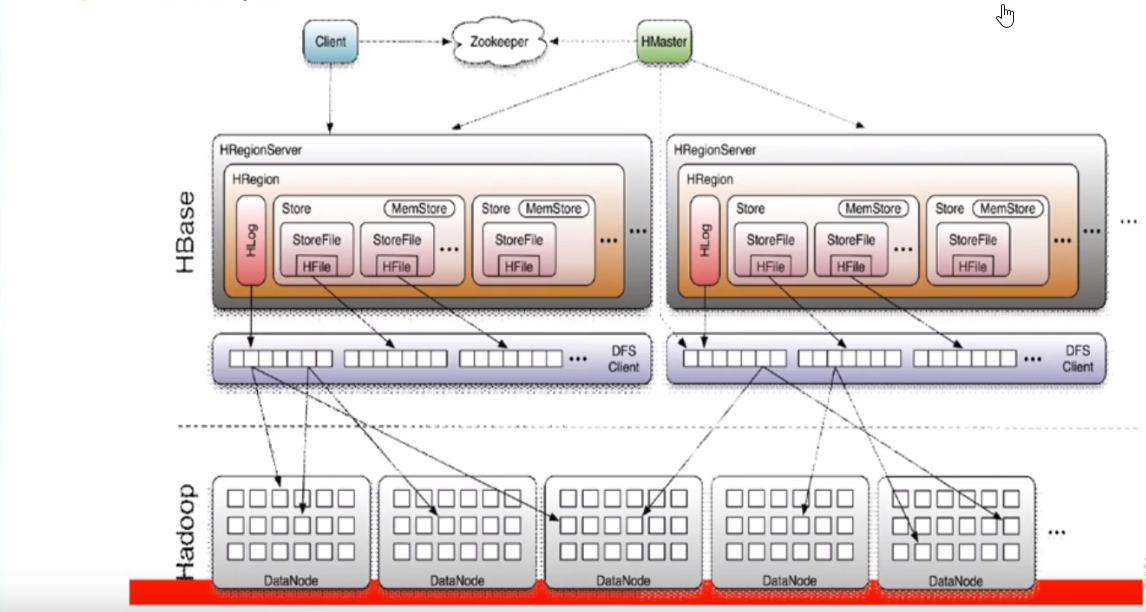
三,hbase 架构
![]()
client:
1,包含访问 HBASE 的接口并维护 cache(memsttore 主要是写)读写,来加快 HBASE访问
Zookeeper
1,保证集群只用一个master
2,存储所有 Region 的寻址入口
3,实时监控 Region server 的上下文信息,实时通知 Master
4,存储 HBASE 的 schema 和 table 元数据
Master:
1,为 Region 分配 region(文件水平切分)
2,负责 region server 的负载均衡
3,发现失效的 region,并分配新的 region(存储在 Zookeeper的元数据和 hfile)
4,管理用户对 table的增删操作
Region server
1, 维护 region,处理对这些 region 的 io 请求
2, 负责切分正在运行过程中变大的 region
3,表存储在 region server 之中
region:
1,HBASE 会把表划分成多个 region,每个 region会保存表里某段的连续数据
2,每个表开始只有一个 region,随着数据不断插入,region增大道一定值会裂变成新的 region
3,一个表会保存多个 region之中,也就是多个 region server 之中把同一列族里面的数据存储同一目录下
memstore 与 storefile
1,一个 region 有多个 storefile组成, 一个store 对应一个列族,数据是保存到 storefile之中
2,store 包括 内存中的 memstore和磁盘中的 storefile,写操作时候先写入 memstore ,当 memstore数据达到某个值, hregionserver 会启动 flashcache 进程写入 storefile,每次写入形成一个单独的 storefile
3,当 storefile文件数量增长到一定的值后,系统会进行合并(minor,major compaction),在合并过程之中进行版本合并与删除,形成更大的 storefile
4, 当一个 region所有的 storefile 的大小和数量超过一定的值后,会把当前的 region 分割成两个,并有 hmaster 分配到相应的 region server服务器之中实现负载均衡
5,服务端检索数据,先在 memstore找,然后 storefile

 浙公网安备 33010602011771号
浙公网安备 33010602011771号