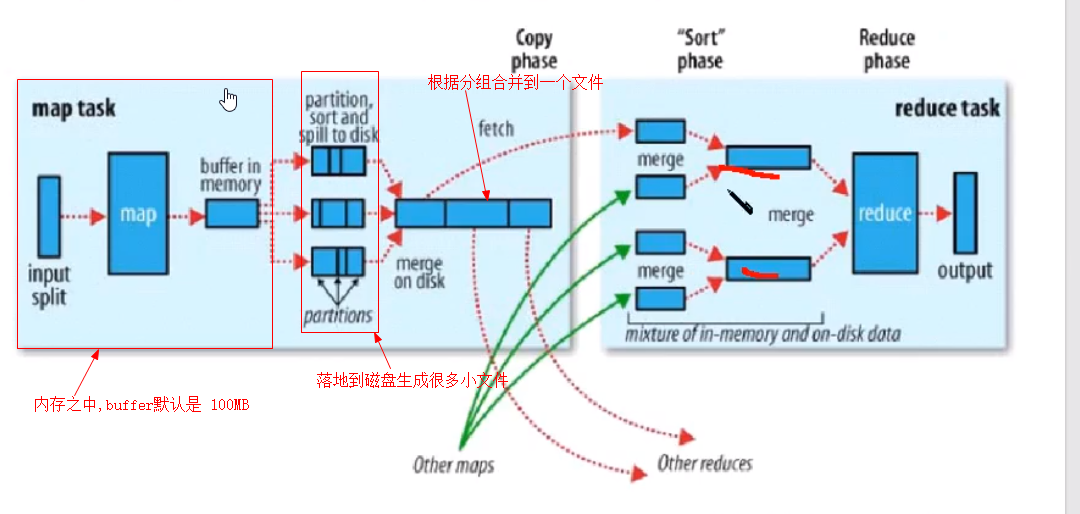
一,map 阶段:
1,切片是由输入格式化类来实现的,默认切片大小等于block size
2,一个切片(逻辑概念,一个map处理数据的大小)对应一个map, 所有的 map 执行完之后才执行 reduce
3,默认的情况下 一个 block对应一个map程序,也可以使用窗口机制(切片) 使得一个 block(很多的 cpu 密集型) 很多 map
4,每个切片以 记录为单位传递给 map,默认是一行是一条记录, map 的输出是以 k,v,p(哪个分区(k hash 取模 )) 值进行输出的
二,reduce 过程:
1,一个reduce task 也称之为分区 Partitioner
2,reduce 数量最好根据 map 分组的数量
三,map 与 reduce 传递:
1,map 到 reduce 过程称之为 shuffer
2,map以相同的 key 为一组, 调用一次 reduce程序,程序内迭代这组数据进行计算
3,reduce 依赖 map 排序,归并map 排序. map 排序之后不会再有排序
四,分组逻辑:
使用key的hashcode % reduce个数,从map阶段开始就将数据放到分区文件中。该分区文件,在hadoop集群中叫做溢出文件,多个分区的数据都会保存在该文件中