一,namenode 介绍说明:
1,namenode 保存的是文件元数据(namenode进程维护者虚拟的目录树)
2,namenode 接受来自 datanode 的block 列表提交
3,namenode 完全基于内存存储(新建元数据等),namenode 是通过快照与log信息来实现恢复的
4,namenode 保存 metadata 信息包括:
1),文件大小时间
2),block列表:偏移量, 位置信息
3),block 副本的位置(datanode上报)
4),文件 owership 与 permissions
5,namenode 的持久化:
1),namenode 的 metadata 信息会在启动时候加载到内存
2),metadata 存储到磁盘文件名为 fsimage
3),block 位置信息不会保存到 fsimage
4),edits 只是记录对 metadata 的操作日志
二,datanode 介绍说明:
1,datanode 本地磁盘目录存储数据(借助 linux 目录来存取数据(block)
2,datanode 也存储了 block 块的元数据信息文件(MD5(根据 block计算的)保证数据的可靠性(与重新计算的MD5进行比较))
3,启动 datanode 会向 namenode 汇报 block 信息会在启动时候加载到内存
4,通过向 namenode 发送心跳保持其联系(3s),超时时间10min(表示已经死掉),copy其上的block到其他的 datanode(保证副本数一致)
三,namenode 与 datanode 交互过程:
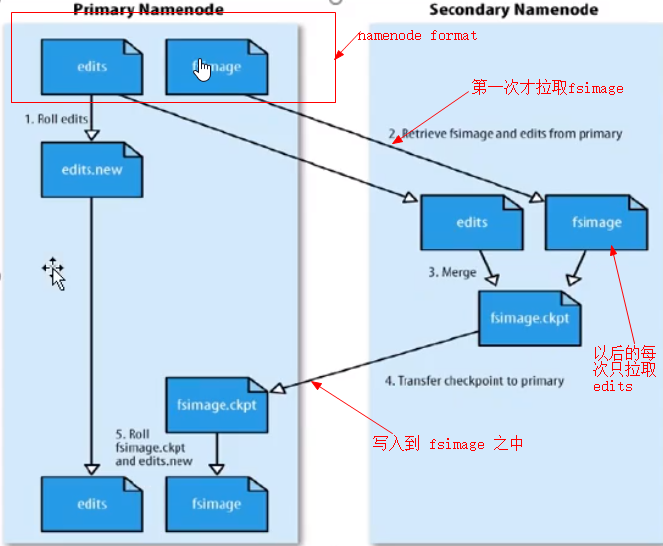
1,在 namenode 格式化时候,fsimage 产生,此时的 edits也是空
2,当 hadoop 运行的过程之中会一直定期的合并成新的 fsimage 与 edits,此过程是SecondaryNameNode实现
3,namenode 启动 首先加载 fsimage,并执行编辑日志 edits的各项操作(也就是恢复关机前的状态)
4,datanode 保存的是 block 数据,namenode 保存的是文件元数据
四,SecondaryNameNode 这主要工作:
1,帮助 namenode 合并 edits到 fsimage之中
2,配置文件设置的时间间隔 fs.checkpoint.period 默认 3600秒
3,根据配置文件 edits log 大小 fs.checkpoint.size 规定 edits大小,默认 64MB
![]()
五,datanode block:
1,block 可以设置副本数,副本数不要超过节点数量(警告),如果已经上传的文件block 可以更改数量,大小不能改变(也就是不能修改)
2,block代表的是偏移量(byte),block 第一个字节是面向源文件的下标.一个副本代表这一次复制(128M数据,两个副本,实际存储128M*2)
3,block副本的放置策略:
1),第一个副本: 放置到上传的 datanode,如果集群外提交,则随机挑选一台磁盘不太满,cpu不太忙的节点
2),第二个副本: 放置在第一个副本不同的机架节点上
3),第三个副本: 放置于第二个副本相同的机架
六,hdfs 文件权限
1,具有 r w x(对于文件夹来说,是否可读,对于文件忽略) 权限
2,某个用户(linux 用户)创建了文件,那么文件的 owner 就是此用户
3,在一个新的 host 之中,创建linux用户x,那么就可一访问 hdfs(包含x用户),因此要为 hdfs 配置权限,需要指定特定的主机可以访问
七,安全模式:
在重启 namenode 之中, datanode 会向 namenode汇报 block位置信息,此过程 namenode的文件系统只是可读的,一段时间后,数据块达到最小副本数时,被认为是安全的,在一定比例的数据库确定为'安全'后,安全模式结束

 浙公网安备 33010602011771号
浙公网安备 33010602011771号