impala 介绍:
1,impala 提供对 hdfs, hbase 数据的高性能,低延迟的交互式 sql查询功能
2,impala 是完全基于hive 的内存计算(中间计算不落地磁盘),spark 中间可以落地
3,impala 完全依赖于 hive, 一次性将 hive 中所有的元数据加载到内存之中
4,c++ 编写,LLVM 统一编译运行(executor 进程)
5,Data Local(数据本地化),一次性加载所有数据(元数据)
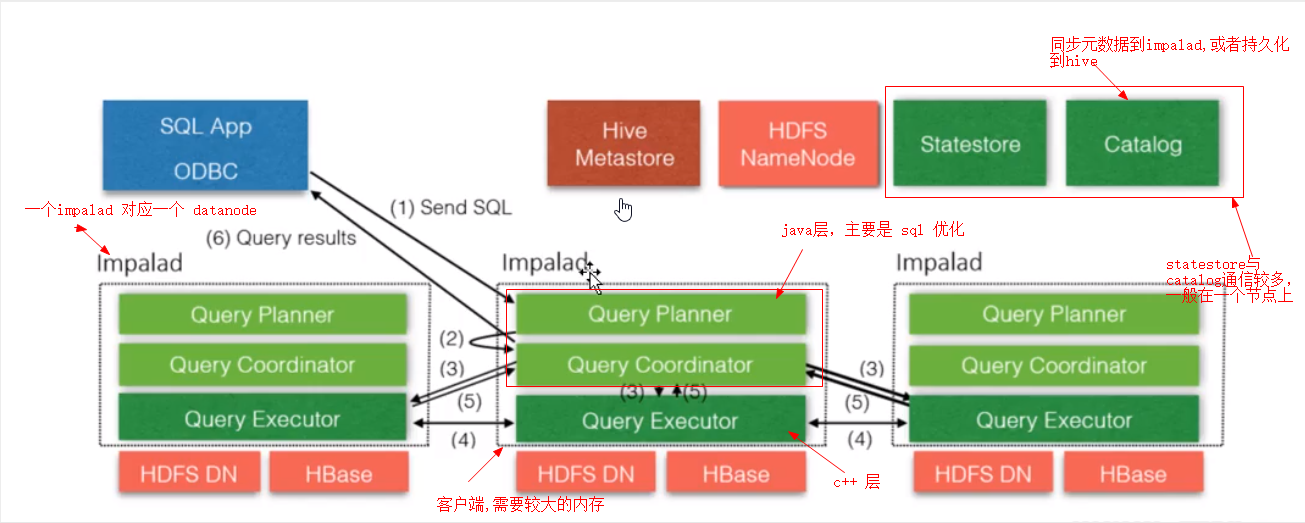
impala 组件:
1,Caralog 接受 statestore的所有请求,分发表的元数据到 impalad, Caralog 用来同步元数据,hive创建表,然后使用 statestore进行广播给impalad(手动).如果 impala创建表,反向更新到hive仓库
2,statestore 负责收集分布在集群各个 impalad进程的资源信息与各节点的健康状态,同步节点信息以及 query的调度,statestore 分布式协调组件, impalad与 Caralog 通信, impalad与 impalad 通信
3,impalad 接受 client,jdbc 等请求,query 执行并返回个中心协调节点,子节点的守护进程,负责向 statestore通信