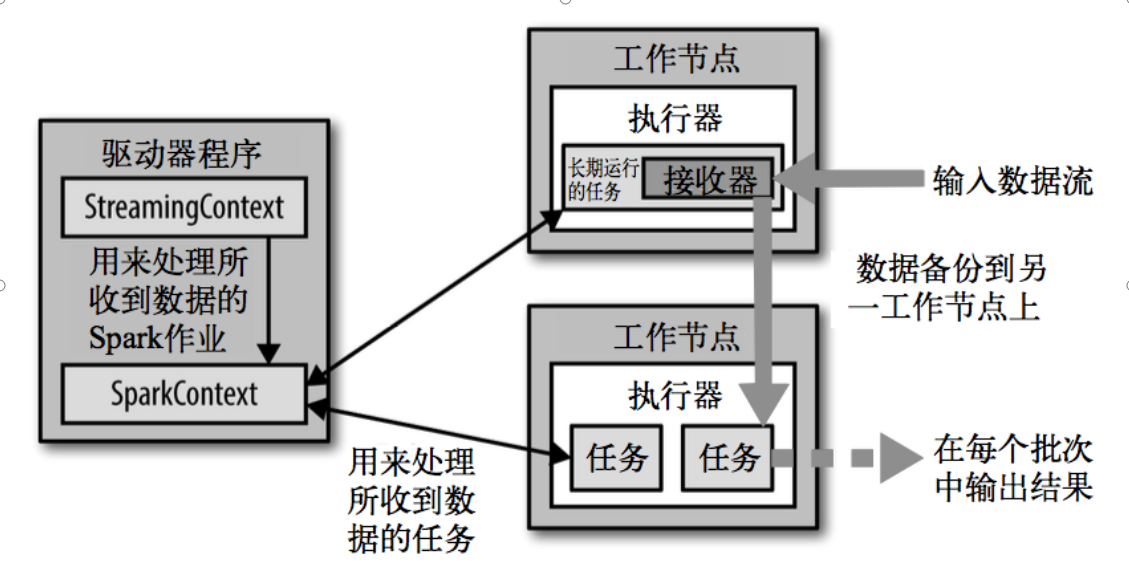
Spark Streaming 架构:
1,Spark Streaming为每个输入源启动对应的接收器。接收器以任务的形式运行在应用的执行器进程中,从输入源收集数据并保存为 RDD。
2,收集到输入数据后会把数据复制到另一个执行器进程来保障容错性(默 认行为)。数据保存在执行器进程的内存中,和缓存 RDD 的方式一样。
3,驱动器程序中的 StreamingContext 会周期性地运行 Spark 作业来处理这些数据,把数据与之前时间区间中的 RDD 进行整合。
4,每个接收器都以 Spark 执行器程序中一个长期运行的任务的形式运行,因此会占据分配给应用的 CPU 核心。
5,我们还需要有可用的 CPU 核心来处理数据。这意味着如果要运行多个接收器,就必须至少有和接收器数目相同的核心数,还要加上用来完成计算所需要的核心数(最少一个)。
![]()
自定义 接收器
package Day3
import java.io.{BufferedReader, InputStreamReader}
import java.net.Socket
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.receiver.Receiver
class Streaming_(host: String, port:Int) extends Receiver[String](StorageLevel.MEMORY_ONLY){
// 接收器启动的时候调用
override def onStart(): Unit = {
// 接收器是线程来实现的
new Thread("receiver"){
override def run(): Unit = {
print("---------------------")
// 接受数据提交给 框架
receive()
}
}.start()
}
def receive(): Unit ={
var sockt:Socket = null
var input:String = null
try{
// 使用 Socket 监听端口
sockt = new Socket(host,port)
// 生成输入流
val reader = new BufferedReader(new InputStreamReader(sockt.getInputStream))
// // 数据传递给 executor
// store(input)
while (!isStopped()&& (input=reader.readLine())!=null){
store(input)
input=reader.readLine()
}
restart("restart")
}catch {
case e:java.net.ConnectException => restart("restart")
case t:Throwable => restart("restart")
}
}
// 接收器关闭调用
override def onStop(): Unit = {
}
}
使用无状态接收器(没有使用自定义接收器)
package Day3
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object Wc {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("wc")
val ssc = new StreamingContext(conf,Seconds(5))
//接受的数据方式,返回的是一行一行的数据, 接受 master:9999 端口
val lineDstream = ssc.socketTextStream("master",9999)
val wordsDstream = lineDstream.flatMap(_.split(" "))
val k2vDstream = wordsDstream.map((_,1))
val results = k2vDstream.reduceByKey(_+_)
results.print()
// 开启 Stream 启动消息采集和处理
ssc.start()
/*
-------------------------------------------
Time: 1561649120000 ms
-------------------------------------------
(da,1)
(DA,1)
(ad,2)
(AD,3)
*/
ssc.awaitTermination()
}}
使用有状态接收器,实际使用了 checkpoint 保存了上次 状态
package Day3
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object Wc {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName("wc")
val ssc = new StreamingContext(conf,Seconds(5))
ssc.checkpoint("./check")
//接受的数据方式,返回的是一行一行的数据, 接受 master:9999 端口
// val lineDstream = ssc.socketTextStream("master",9999)
// 使用自定义的接收器
val lineDstream = ssc.receiverStream(new Streaming_("master",9999))
val wordsDstream = lineDstream.flatMap(_.split(" "))
val k2vDstream = wordsDstream.map((_,1))
val updateFuc = (v:Seq[Int],state:Option[Int])=>{
val preStatus = state.getOrElse(0)
Some(preStatus+v.sum)
}
val results = k2vDstream.updateStateByKey(updateFuc)
results.print()
// 开启 Stream 启动消息采集和处理
ssc.start()
/*
-------------------------------------------
Time: 1561799425000 ms
-------------------------------------------
(4,1)
(ss,1)
(55,1)
(2,1)
(,3)
(s,8)
(234,1)
(3,3)
(q,3)
(12,1)
...
*/
ssc.awaitTermination()
}}
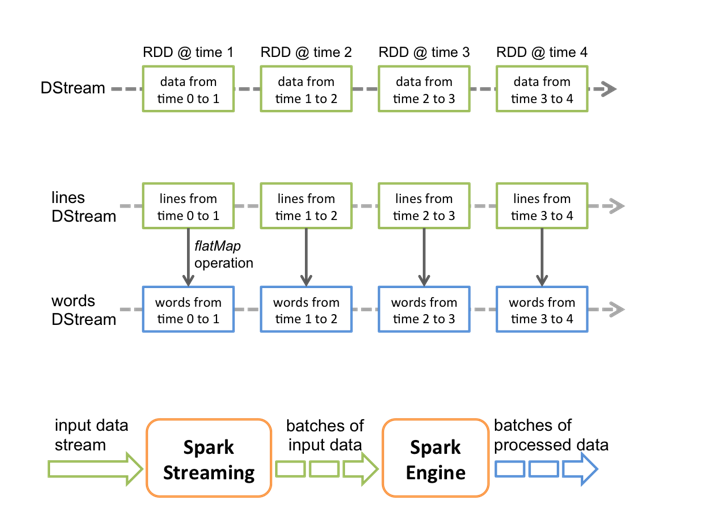
/*
SparkStreaming是准实时的处理框架(微批处理),按照时间段进行收集数据
以上代码运行说明
* */
以上代码运行说明
![]()
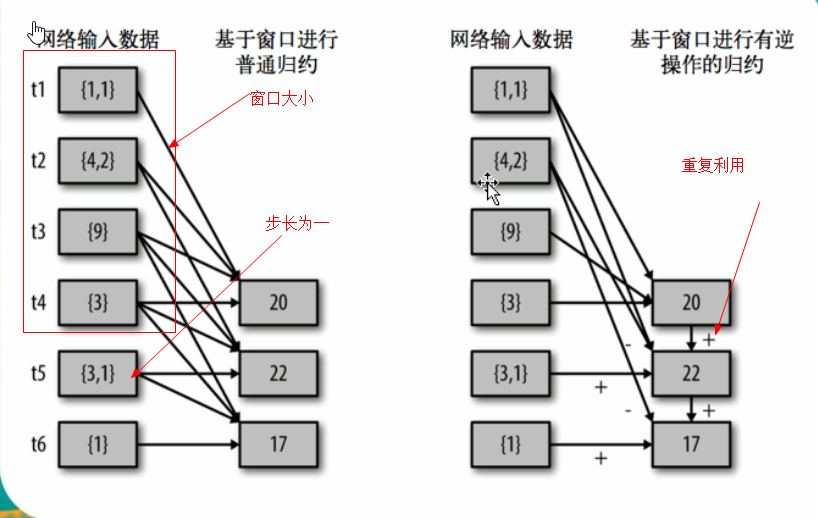
使用 Window Operations 来获取 Streaming运行状态
package Day3
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object Wc {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName("wc")
val ssc = new StreamingContext(conf,Seconds(5))
ssc.checkpoint("./check")
//接受的数据方式,返回的是一行一行的数据, 接受 master:9999 端口
// val lineDstream = ssc.socketTextStream("master",9999)
// 使用自定义的接收器
val lineDstream = ssc.receiverStream(new Streaming_("master",9999))
val wordsDstream = lineDstream.flatMap(_.split(" "))
val k2vDstream = wordsDstream.map((_,1))
// val updateFuc = (v:Seq[Int],state:Option[Int])=>{
// val preStatus = state.getOrElse(0)
// Some(preStatus+v.sum)
// }
// val results = k2vDstream.updateStateByKey(updateFuc)
// 使用窗口函数 (reduce 函数,窗口大小,步长)
// 每次重新计算,重复的部分删掉
// val results = k2vDstream.reduceByKeyAndWindow((x:Int,y:Int)=>x+y,Seconds(15),Seconds(10))
// 使用窗口函数 (reduce 函数,减去多余的(前五秒的),窗口大小,步长)
// 这种方式更加优化,针对重复次数来计算
val results = k2vDstream.reduceByKeyAndWindow((x:Int,y:Int)=>x+y,(a:Int,b:Int)=>a-b,Seconds(15),Seconds(10))
results.print()
// 开启 Stream 启动消息采集和处理
ssc.start()
/*
-------------------------------------------
Time: 1561866450000 ms
-------------------------------------------
(2,8)
(,1)
(22,1)
(1,3)
*/
ssc.awaitTermination()
}}
以上代码运行说明
![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号