hadoop 集群部署与故障转移其一(hdfs HA与yarn HA)
hadoop 集群部署与故障转移:
高可用:
1, 主要是指 hdfs HA(高可用) 与 yarn 的 HA
2, 保证 namenode 与 ResouceManager 不在一个节点(主句)之上,
hdfs 的 HA 是通过 多个 namenode 来实现的:
1,namenode 由元数据(Fslmage) 与 Edits(日志) 组成,Edits 会记录进行元数据的更新,因此 hdfs 的高可用,所以 可以通过 Edits聚合合并成新的 namenode
2,如果保证了多个namenode 之间的 Edits同步,也就可以保证高可用
3,使用 JournalNode(每个datanode节点都有) 保证 namenode 数据的完整性,存储的是 Edits日志信息
4,使用 Zookeeper 可以实现自动故障转移, Zookeeper可以存储namenode的活动状态,zookeeper 维护目录树, 首先在目录树上创建成功节点的namenode为active
hdfs-site.xml 配置


<configuration> <!--其他用户使用hdfs 操作文件,是否进行验证!--> <property> <name>dfs.permissions</name> <value>false</value> </property> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.nameservices</name> <value>nameservice</value> </property> <property> <name>dfs.ha.namenodes.nameservice</name> <value>nn1,nn2</value> </property> <property> <name>dfs.namenode.rpc-address.nameservice.nn1</name> <value>sr129:8020</value> </property> <property> <name>dfs.namenode.rpc-address.nameservice.nn2</name> <value>sr128:8020</value> </property> <property> <name>dfs.namenode.http-address.nameservice.nn1</name> <value>sr129:50070</value> </property> <property> <name>dfs.namenode.http-address.nameservice.nn2</name> <value>sr128:50070</value> </property> <!--配置 Edits 存储路径--> <property> <name>dfs.journalnode.edits.dir</name> <value>/opt/modules/hadoop-2.7.0/data/jn</value> </property> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://sr128:8485;sr129:8485;sr130:8485/nameservice</value> </property> <!--故障转移类--> <property> <name>dfs.client.failover.proxy.provider.nameservice</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!--隔离机制--> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/sxu/.ssh/id_rsa</value> </property> </configuration>
core-site.xml 配置(地址更改 fs.defaultFS)
<configuration> <!-- 指定HADOOP所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://nameservice</value> </property> <!--hadoop 的默认用户--> <property> <name>hadoop.http.staticuser.user</name> <value>master</value> </property> <!--datanode.data.dir 存储文件目录, namenode.name.dir 元数据,namenode.edits.dir 日志目录 三者都依赖于此目录--> <property> <name>hadoop.tmp.dir</name> <value>/opt/modules/hadoop-2.7.0/data/tmp</value> </property> </configuration>
linux 操作
# 每个节点开启 journalnode(此时生成元数据信息) sbin/hadoop-daemon.sh start journalnode # 开启后需要重新 namenode 格式化一下,一台格式化 # 同步元数据信息(另一个 namenode节点),相当于 copy另一台的 元数据 sbin/hdfs namenode -bootstrapStandby # 将其中一个节点设置为 active 状态 ./hdfs haadmin -transitionToStandby nn1 # 强制将节点 nn1 转换为 active 状态 ./hdfs haadmin -transitionToActive --forcemanual nn1 # 将 nn1 转换成 standly 状态 ./hdfs haadmin -transitionToStandby nn1
配置完成之后就会有 JournalNode 进程(伴随着 start-all.sh 与 stop-all.sh),每次启动都需要将一个 namenode设置为 active状态(可以使用 Zookeeper自动配置)
HA 高可用测试(两个namenode 一个为 active状态,一个为standby状态):
#杀死其中一个 namenode 节点 kill -9 9470 #将standby 状态的 namenode启用 ./hdfs haadmin -transitionToActive --forceactive nn1
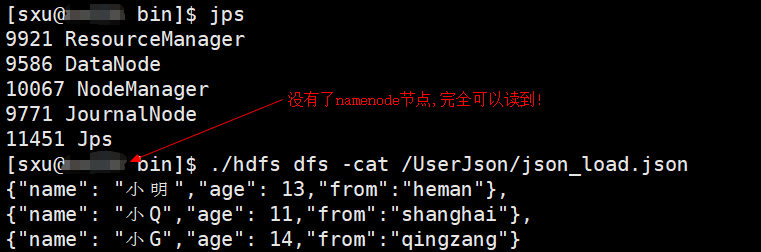
使用 Zookeeper 控制节点转移
1,配置 Zookeeper, hdfs-site.xml 新增(分发到每个节点)
<!--是否开启故障转移 , nameservice 指的是配置的nameservices名称--> <property> <name>dfs.ha.automatic-failover.enabled.nameservice</name> <value>true</value> </property> <!--指定故障转移的集群 2181是客户端访问zookeeper主机的端口 --> <property> <name>ha.zookeeper.quorum</name> <value>sr128:2181,sr129:2181,sr130:2181</value> </property>
使用命令
# 每个节点开启 Zookeeper bin/zkServer.sh start # 第一次配置初始化 HA 在 Zookeeper 之中的状态 bin/hdfs zkfc -formatZK # 开启 hdfs sbin/start-dfs.sh # namenode 节点 开启 zkfc(多了故障转移DFSZKFailoverController进程) sbin/hadoop-daemon.sh start zkfc #开启 yarn sbin/start-yarn.sh

常见错误(需要保证namenode节点之间可以ssh互联):
# configured methodjava.lang.RuntimeException: Unable to fence NameNode at # 需要下载 psmisc 进行 fence yum install psmisc
YARN-HA 架构:
1,Zookeeper 主要是做分布式协调服务的
2,active RM 将资源状态存放到 Zookeeper 之中
3,active RM down掉 会实时的和 Zookeeper进行心跳交流 ,Standby会自动转换 active
4,不需要额外启动进程,只是作为一个线程
4,使用 Zookeeper 作为 resourcemanager,注释掉原来的 resourcemanager
修改 yarn-site.xml 文件
<?xml version="1.0"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <configuration> <!-- Site specific YARN configuration properties --> <!-- 不需要指定 resourcemanager,使用 Zookeeper 进行选举 <property> <name>yarn.resourcemanager.hostname</name> <value>sr128</value> </property> --> <!-- reducer获取数据的方式,一种辅助 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!--开启日志聚集--> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!--日志存放的时间(s)--> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>100000</value> </property> <!--是否开启 yarn HA--> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <!--逻辑名称--> <property> <name>yarn.resourcemanager.cluster-id</name> <value>RS</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>sr128</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>sr129</value> </property> <!--和ZK的集成--> <property> <name>yarn.resourcemanager.zk-address</name> <value>sr128:2181,sr129:2181,sr130:2181</value> </property> <!--是否进行数据恢复--> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <!--数据恢复的位置--> <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property> </configuration>
常见操作:
#namenode节点开启 resourcemanager(手动开启) 在一个namenode节点可以使用 yarn-daemons.sh 全部启动 ./yarn-daemon.sh start resourcemanager # datanode 节点开启 nodemanager ./yarn-daemon.sh start nodemanager


 浙公网安备 33010602011771号
浙公网安备 33010602011771号