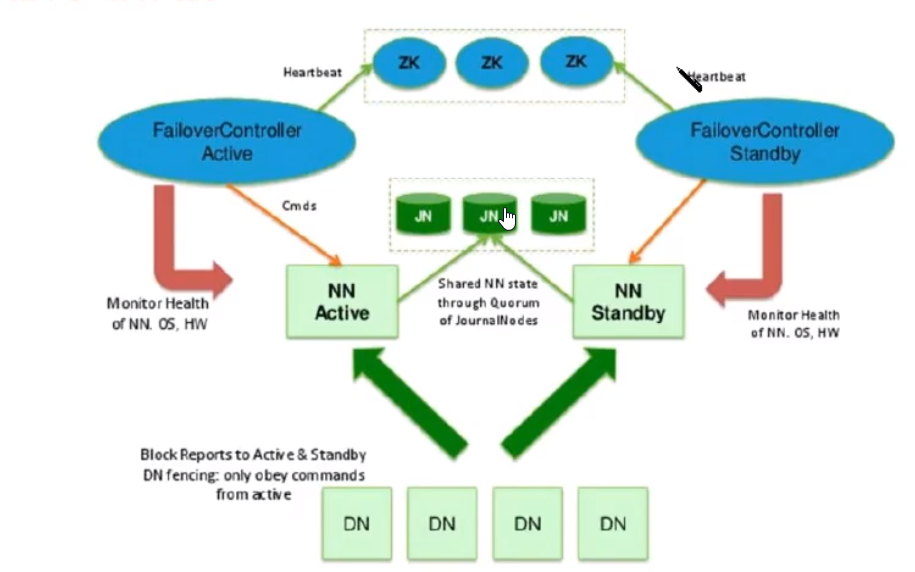
zookper 运行机制(以 Hadoop HA 为例):
1),zookeeper 使用目录树维护集群信息, 首先在目录树上创建成功节点的namenode为active
2),zeekeeper 主节点为每个从节点准备一个 message quene,通过 message quene 来实现事件的触发
3), Hadoop HA 是由 ZKFC 进程与 zookeeper 进行通信的
4), 当 namenode 挂掉, 首先 ZKFC 通知 zookeeper , 并删除节点
5), 以上步骤是以事件为单位的, 每一个事件都有相应函数
6), zookeeper 与 ZKFC 会有心跳机制, 长时间不相应默认为 ZKFC 失效
7), 事件发生时的注册函数 需要代码实现
zeekeeper server leader 选举原则:
1,server leader 重新选举依赖于 serverid 服务器编号,编号最大的选举为 server leader
2,如果 zeekeeper 集群一台台启动, 第三台为 leader(保证尽快可用), 同时启动是 serverid 最大的为 leader
3, zxid(版本号,代表的是事务(更新)id),版本最新(更新数据是最新的数据那么就是最新版本)的为 leader ,有限高于 serverid
server 状态:
1,LOOKING: 当前 Server不知道 leader,正在搜寻
2,LEANDING: 当前服务器为 leader
3,FOLLOWING: leader 已经选举,当前 Server 与之同步
zeekeeper 分工:
1,leader 负责投片的发起与决议,更新系统状态
2,leader:
1),follower(跟随者) 接收客户端连接,将读写请求转发给leader,参与投票
2),observer 接收客户端连接,将读写请求转发给leader,不参与投票,只同步leader状态,observer是为了扩展系统提高读取速度
![]()
zookeeper 安装:版本选择 cdh 版本(带有源码)
zookeeper进行配置(我是将zoo-sample.cfg改为zoo.cfg),
1,我是三台机器(server1,server2,server3):
# The number of milliseconds of each tick
# 服务器之间心跳握手时间,每隔2000ms就会一次握手
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
# 在服务端进行配置,最长能够忍受心跳间隔(tickTime)个数
# 超过配置,那么就认为这个客户端连接失败, 2000(ms)*10=20s
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
#Leader 与Follower之间发送消息时间长度为 2000(ms)*5=10s
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
# zeekep数据存储目录
dataDir=/opt/modules/zookeeper-3.4.5-cdh5.4.10/tmp/zookeeper
# the port at which the clients will connect
clientPort=2181
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
# 关于选举:如果Leader死掉,其他的Follower会选出一个作为 Leader(自动)
# 服务器与客户端通信端口号:选举时通信端口
server.1=server1:2888:3888
server.2=server2:2888:3888
server.3=server3:2888:3888
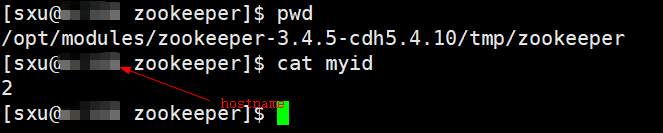
2,在指定的dataDir目录执行创建myid文件,写上对应的名称,按照配置文件, server1写入 1,server2写入2,server3写入3
![]()
3,启动zookeeper
1),关于 zookeeper 启动,原则是允许一台损坏,如果你的集群是三台机器,那么只启动一台zkCli.sh是启动不了的,它认为你损坏了两台
./zkServer.sh start
# 开启客户端
./zkCli.sh
# 查看 状态
./zkServer.sh status
# 停止 服务
./zkServer.sh stop
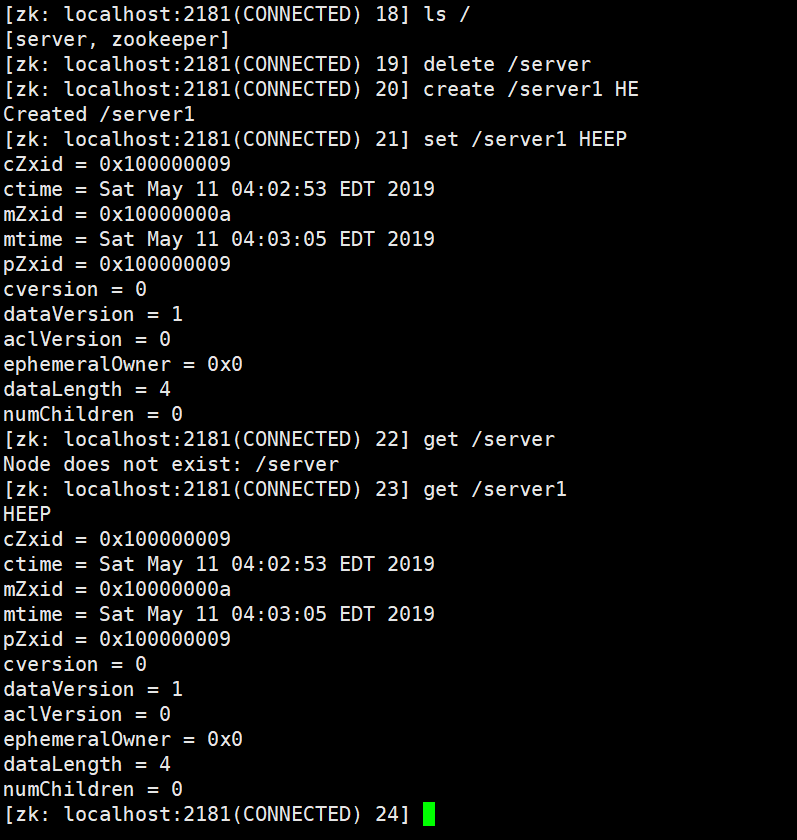
zeekep 常见操作:
# 查看主目录
ls /
# 创建目录 server(主目录下) 定义值为:HE
create /server HE
#根据目录得到值
get /server
#删除 目录 /server
delete /server
#更改 /server 的值
set /server HEP
![]()
kafka 集群配置:
1,选择版本是 kafka_2.11-0.8.2.1.tar
2,kafka 企业都是进行二次开发的, zookeeper记录 kafka节点的操作(分发与接收信息)logs
conf/server.properties 配置(具体节点需要具体修改)
# 唯一标识(每个节点不一)
broker.id=0
# 配置 hostname
host.name=server1
# 配置 log 目录
log.dirs=/opt/modules/kafka_2.11-0.8.2.1/kafka-logs
# 节点信息,连接 zookeeper
zookeeper.connect=server1:2181,server2:2181,server3:2181
conf/producer.properties 配置
# 指定节点列表
metadata.broker.list=server1:9092,server2:9092,server3:9092
kafka的启动
# 使用 screen 后台运行, 使用ctrl a + d 退出
screen -S kafka
bin/kafka-server-start.sh config/server.properties

 浙公网安备 33010602011771号
浙公网安备 33010602011771号