变量传参:
1,在 spark 编写的程序之中是没有全局变量的,是因为在 driver设置的全局变量,在 execute 可以使用,但是不会返回给driver,除非使用累加器
2,累加器只能在 driver端进行使用,因为它是来自于 sc(只存在于 driver)
package day01
import org.apache.spark.{Accumulator, SparkConf, SparkContext}
object Add_num {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("ADD_NUM")
val sc = new SparkContext(conf)
val rdd = sc.textFile("./1.txt")
val rdd2 = sc.textFile("./1.txt")
var num = 0
var accumulator:Accumulator[Int] =sc.accumulator(0)
val rdd_1 =rdd.map(line=>{
num += 1
line
})
rdd_1.collect()
println(num) // num = 0
val rdd2_1 = rdd2.map(line=>{
accumulator.add(1)
println(accumulator)// 在 execute 获取不需要使用 value
line
})
rdd2_1.collect()
println(accumulator.value) // 5 accumulator累加器全局统筹变量
}}
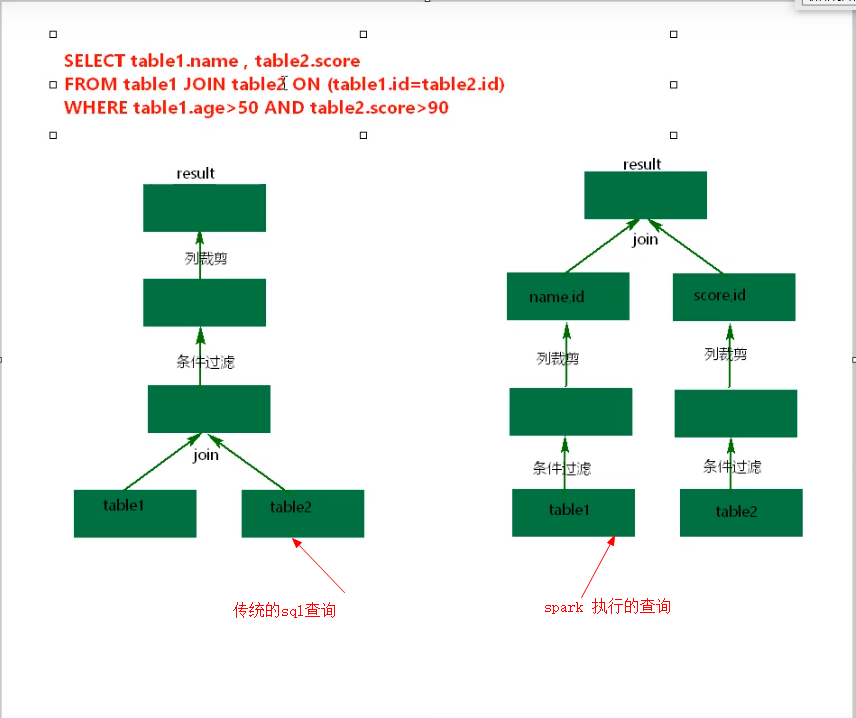
spark Dataframe:
1, Dataframe 是一个分布式数据容器,有数据与数据的结构信息组成(schema)
2, Dataframe API 提供一套高层的关系操作,比函数式的 RDD API更加友好
3, Dataframe 底层是 Row RDD, 这也是为什么 Dataframe可以与 RDD相互转换的原因
spark 集群支持log 记录(主从一致)
1,spark 支持事件日志写入某个目录,并且可以日志压缩
2,日志是 application 日志,只不过存储在了 hdsf 之中
# 开启 log ,并且配置 log 路径
spark.eventLog.enabled true
spark.eventLog.dir hdfs://master:9000/spark/logs
# 配置历史服务器路径(spark 重启也可以看到历史记录)
spark.history.fs.logDirectory hdfs://master:9000/spark/logs
# 使用此参数指定log压缩(snappy 压缩格式)
spark.eventLog.compress true
可以开启一个端口来查看历史服务(spark-defaults.conf),需要指定配置的历史记录所对应的hdfs 位置
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=7777 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://master:9000/spark/logs"
启动历史服务器(进程 HistoryServer ), 只有查看历史的作用,对设定的历史路径(hdfs)进行展示
./sbin/start-history-server.sh
spark 集群构建(主从一致)
1,修改Spark配置文件spark-env.sh
#指定 master 地址与 ip 和 JAVA_HOME
SPARK_MASTER_PORT=7077
SPARK_MASTER_IP=sr128
export JAVA_HOME=/usr/local/java/jdk-11.0.2
2,slaves文件中加入所有Work的地址


