本次使用 hadoop-2.7.0+spark-2.1.1-bin-hadoop2.7+zeppelin-0.8.1-bin-all
使用步骤:
1,配置 zeppelin-env.sh
export JAVA_HOME=/home/hadoop/jdk-11.0.2
export SPARK_HOME=/home/hadoop/spark-2.1.1-bin-hadoop2.7
export HADOOP_HOME=/home/hadoop/hadoop-2.7.0
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export ZEPPELIN_HOME_INTP_JAVA_OPTS="-XX:PermSize=800M -XX:MaxPermSize=1024M"
2,配置端口号
<property>
<name>zeppelin.server.port</name>
<value>8089</value>
<description>Server port.</description>
</property>
3,启动zeppelin
bin/zeppelin-daemon.sh start
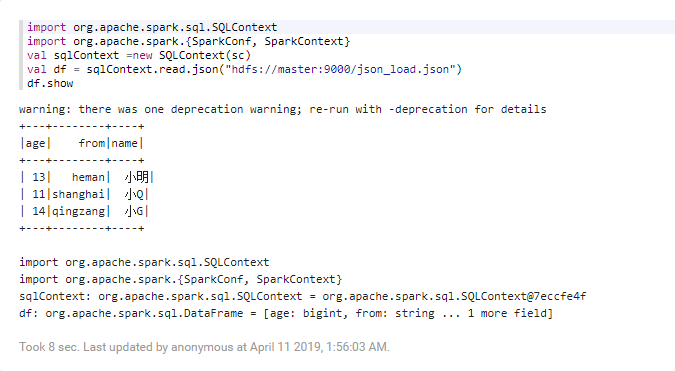
5,使用ui 界面 使用 saprk Interpreter
6,使用 spark 实例(也就是spark-shell)
1),在spark 的表现形式是 applaction