hive 常见数据结构:
1,struct 大约 c语言之中的结构体,都可以使用'.'来进行访问元素的内容
2,map 键值对
3,array 数组
创建文件
xiaoming,lili_bingbing,xiao xiao:18_xiaoqiang song :19 tong luo wan
针对以上数据创建表:根据行来进行创建 ,指定每一行的数据类型与分隔符
create table test(
name string,
friends array<string>,
address struct<street:string, city:string>
) row format delimited
fields terminated by ',' /*每行以,分割*/
collection items terminated by '_'
map keys terminated by ':'
/* 查询*/
select friends[1],address.city from test;
使用 jdbc 连接 hive, 需要开启 hiveserver2
# 需要 bin/hiveserver2
./beeline -u jdbc:hive2://master:10000
# 或者 !connect jdbc:hive2://master:10000
内部表与外部表:
1,内部表数据由Hive自身管理,外部表数据由HDFS管理
2,删除内部表会直接删除元数据(metadata)及存储数据;删除外部表仅仅会删除元数据,HDFS上的文件并不会被删除;
表分区:
1,在 hive 之中表是以文件夹(最大值为block 大小)的形式展示的,以文件的角度来说,分区是表文件增加子目录,子目录存储文件
2,hive 没有索引,因此使用分区(指定文件夹)来避免全局扫描
/*数据库增加表字段类型*/
alter database sga set dbproperties("ctime"="1990-28-18");
/*查看数据库(包括隐藏字段)*/
desc database extended sga;
drop database sga cascade; /*级联删除 也会将 hdfs 之中的文件进行删除!*/
/*修改表名称 但是不支持数据库重命名*/
alter table test rename to FPGA;
/*表增减字段*/
alter table stu add columns(gg string,address struct <street:string, city:string >)
/* 执行的 mr 任务,不仅创建表结构,还会将数据加载进去 */
create table students as select * from stu;
/* 只有表结构的数据*/
create table student1 like stu;
/* 查看表详细信息 */
desc formatted student;
/*默认创建的是管理表(内部表),使用 external关键字创建外部表*/
create external table dept(dept int ,dname string, loc int) row format delimited fields terminated by '\t';
/* 外部表删除会将原始数据不会删除!可以重新建表*/
drop table dept
/*内部表转化成外部表(区分大小写,单双引号,不然会加属性) Table Type: EXTERNAL_TABLE */
alter table student set tblproperties('EXTERNAL'='TRUE');
/*内部表转化成外部表 Table Type: MANAGED_TABLE*/
alter table student set tblproperties('EXTERNAL'='FALSE');
/*创建分区表*/
create table stu_partition(id int,name string) partitioned by(month string) row format delimited fields terminated by '\t';
/*分区表插入数据 ,也就是指定表文件下的子文件夹 /user/hive/warehouse/stu_partition/month=19960712*/
load data local inpath '/home/hadoop/hive/bin/stu.txt' into table stu_partition partition(month=19960712);
/*按照表分区进行查询,表分区是加了一个表字段*/
select * from stu_partition where month=19960712 or month=19960711;
/*为表增加两个分区*/
alter table stu_partition add partition(month=19960721) partition(month=19960722);
/*为表删除一个分区,多个使用 ',' */
alter table stu_partition drop partition(month=19960721),partition(month=19960722);
hive 序列化操作 针对文件为
192.168.57.4 - - [29/Feb/2016:18:14:35 +0800] "GET /bg-upper.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:35 +0800] "GET /bg-nav.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:35 +0800] "GET /asf-logo.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:35 +0800] "GET /bg-button.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:3
192.168.57.4 -
创建 sql 语句
CREATE TABLE logtbl1 (
host STRING,
identity STRING,
t_user STRING,
time STRING,
request STRING,
referer STRING,
agent STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex" = "([^ ]*) ([^ ]*) ([^ ]*) \\[(.*)\\] \"(.*)\" (-|[0-9]*) (-|[0-9]*)"
)STORED AS TEXTFILE;
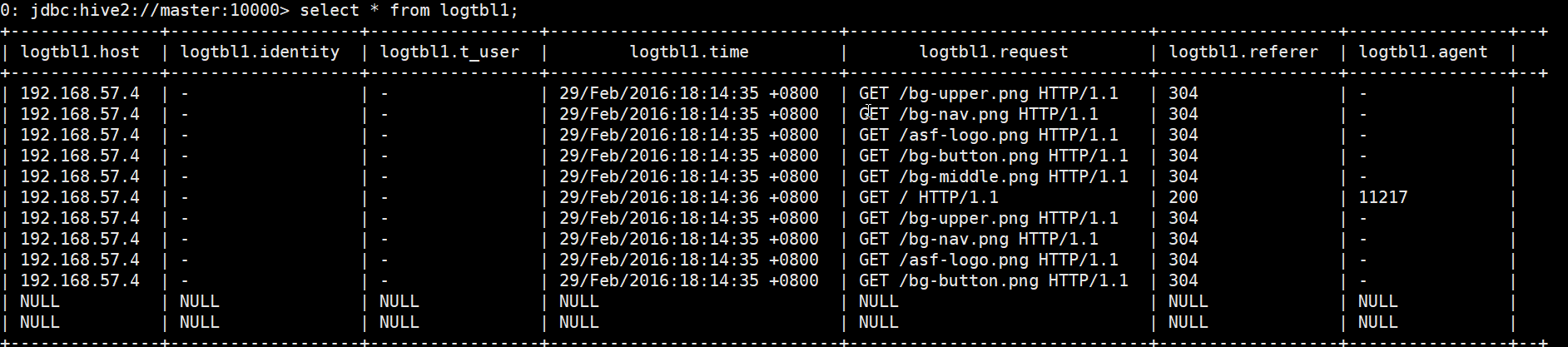
查询结果(hive 读时检查数据格式,如果不正确,那么久会显示 null)
![]()
hive 动态分区:
# 修改权限 开启动态分区
set hive.exec.dynamic.partiton=true
#修改默认状态 默认strict。至少有一个静态分区
set hive.exec.dynamic.partiton.mode=nostrict
首先创建原始表, 然后 load 数据, 使用另外表进行数据分区
create table tb_p0(
id int,
name string,
likes array<string>,
age int ,
sex string,
address map<string ,string>
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY ','
MAP KEYS TERMINATED BY ':'
LINES TERMINATED BY '\n';
create table tb_p1(
id int,
name string,
likes array<string>,
address map<string ,string>
)
partitioned by (age int ,sex string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY ','
MAP KEYS TERMINATED BY ':'
LINES TERMINATED BY '\n'
/*已经存在的表格并且要有数据 */
from tb_p0
insert overwrite table tb_p2 partiton (age,sex)
select * distribute by age,sex

 浙公网安备 33010602011771号
浙公网安备 33010602011771号