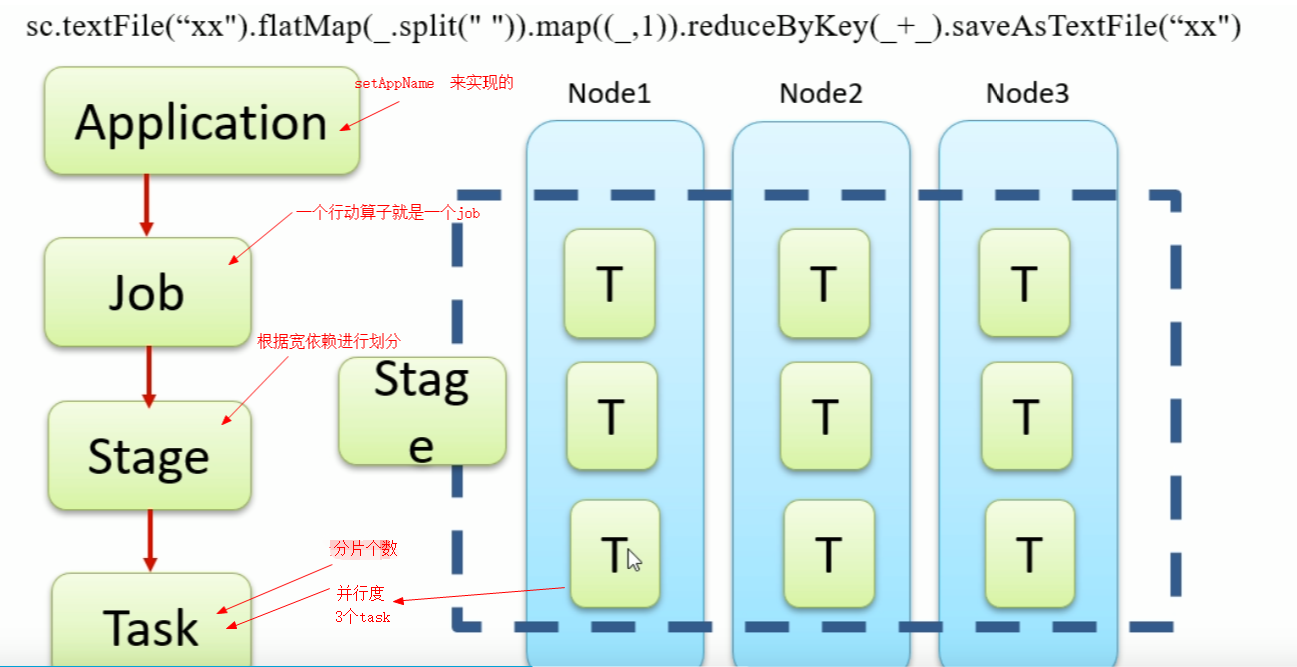
RDD 依赖:
1,RDD 宽依赖(会有shuffle过程):父EDD与子RDD partition之间关系是一对多(groupByKey)
2,RDD 窄依赖:父EDD与子RDD partition之间关系是一对一(map,union等)或者多对一(多个分区看成逻辑上的 partition,合并成一个分区),多个父RDD也就有了shuffer过程
![]()
![]()
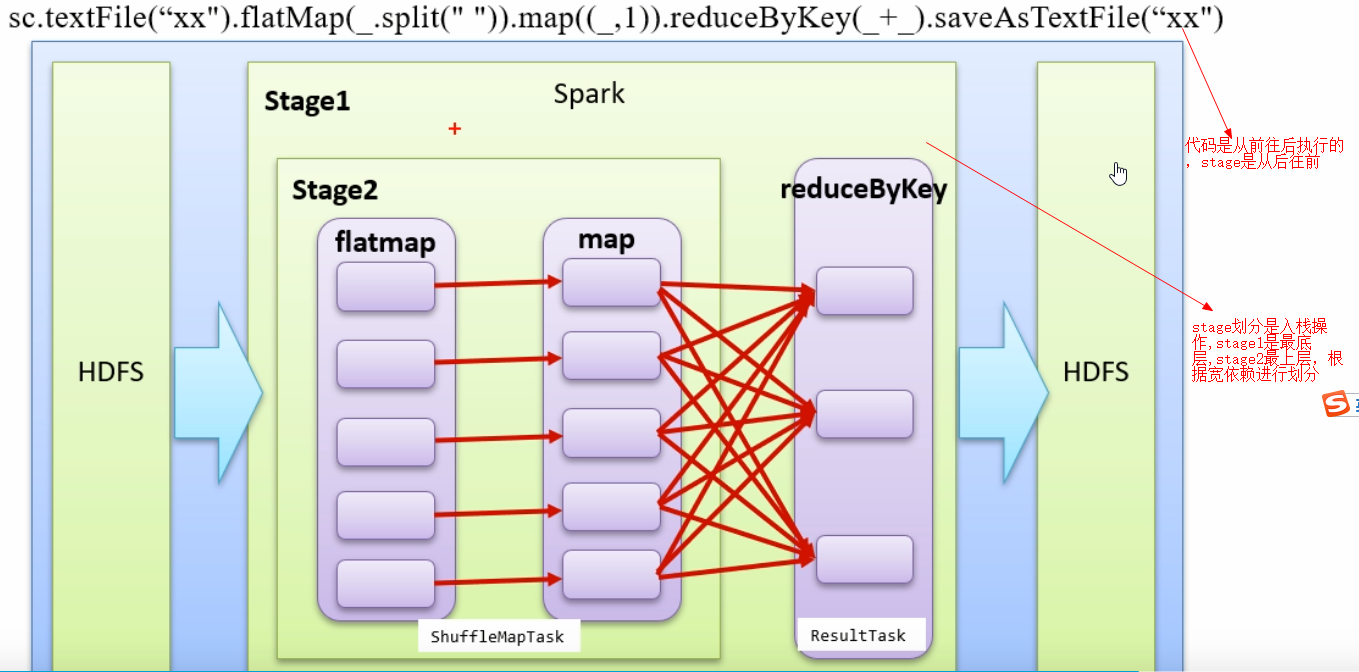
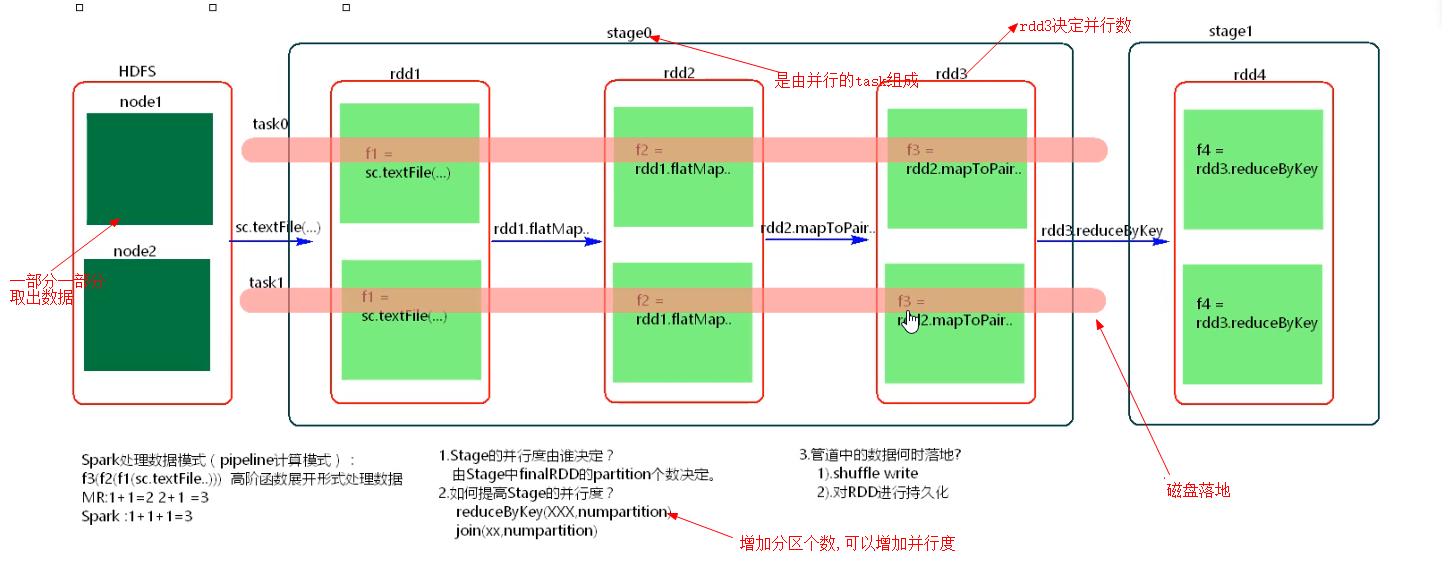
spark 计算模式:
1,partition: 并不存储数据,存储的是程序逻辑.
2,pipeline 计算模式
![]()
代码分析
package day02
import org.apache.spark.{SparkConf, SparkContext}
object Pipline {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("test")
val sc = new SparkContext(conf)
val rdd1 = sc.makeRDD(Array("Python","Java","Scala"))
val rdd2 = rdd1.map{name=>{
println("---------map"+name)
name+"~"
}}
val rdd3 = rdd2.filter(name=>{
println("*********filter"+name)
true
})
rdd3.collect()
sc.stop()
/*
---------mapPython
*********filterPython~
---------mapJava
*********filterJava~
---------mapScala
*********filterScala~
* */ // 此处可以看出是 pipeline的计算模式,一部分一部分计算
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号