hive说明:
1,Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能
2,hive 的效率取决于 mapreduce或者spark
3,hive将 sql语句翻译成MapReduce程序,然后YARN->HDFS
4,hive 将表结构存储于额外的数据库,例如mysql,也自带了derty数据库,启动hive之前需要格式化derty(新建metastore_db文件)
5,metastore_db里面存储了derby的元数据(存放着数据文件的位置与数据文文件的列名,每个列(行,复杂数据类型)之间是什么符号进行区分的等等.)
6,2,hive只适合用来做批量数据统计分析
hive命令
#会在当前目录下简历metastore_db的数据库
#遇到问题,把metastore_db删掉,重新执行命令
#次执行hive时应该还在同一目录,默认到当前目录下寻找metastore,找不到创建!
schematool -initSchema -dbType derby
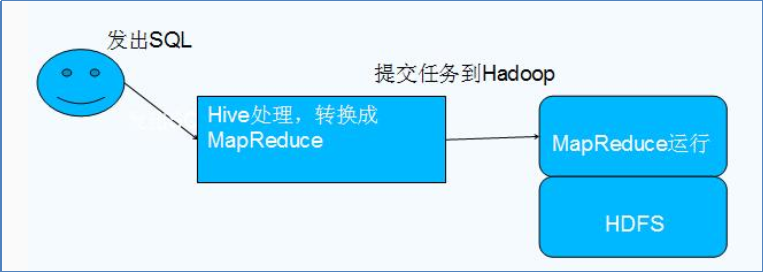
Hive与Hadoop的关系
1,Hive利用HDFS存储数据,利用MapReduce查询数据
![]()
Hive数据模型:
1,db:在hdfs中表现为${hive.metastore.warehouse.dir}目录下一个文件夹
2,table:在hdfs中表现所属db目录下一个文件夹
3,external table:与table类似,不过其数据存放位置可以在任意指定路径
4,partition:在hdfs中表现为table目录下的子目录,用户通过指定一个或多个partition key,决定数据存放方式,进而优化数据的查询
5,bucket:在hdfs中表现为同一个表目录下根据hash散列之后的多个文件,‘桶’
hive启动方式:
# 后台启动,写入日志与 err信息
nohup bin/hiveserver2 1>/var/log/hiveserver.log 2>/var/log/hiveserver.err &
hive连接方式:
#使用 beeline客户端连接
#启动 beeline时就连接(hive-site.xml 配置了用户名密码)
bin/beeline -u jdbc:hive2://mini1:10000
hive语句实例
# 创建表 doc
create table doc(line string);
# 将 hdfs 根目录下 wcinput 文件关联到 doc表之中,行对列
load data inpath '/wcinput' overwrite into table doc;
# 表之中的数据按照' '切割
select split(line, ' ') from doc;
#将切割后的数据,一个单词一行作为列存到另一张表之中
select explode(split(line, ' ')) as world from doc;
create table word_counts as select word, count(1) as count from (select explode(split(line, ' ')) as word from doc) w group by word order by word;
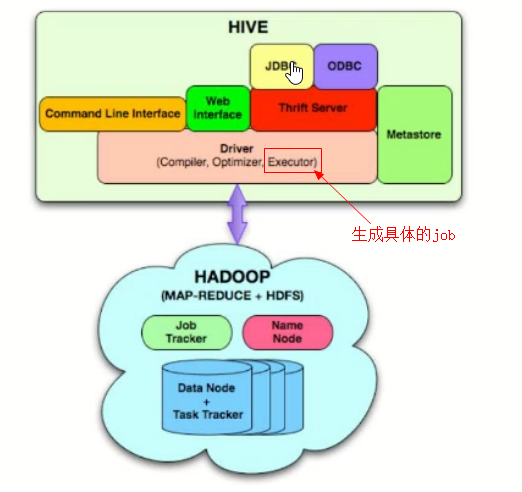
hive运行架构
![]()
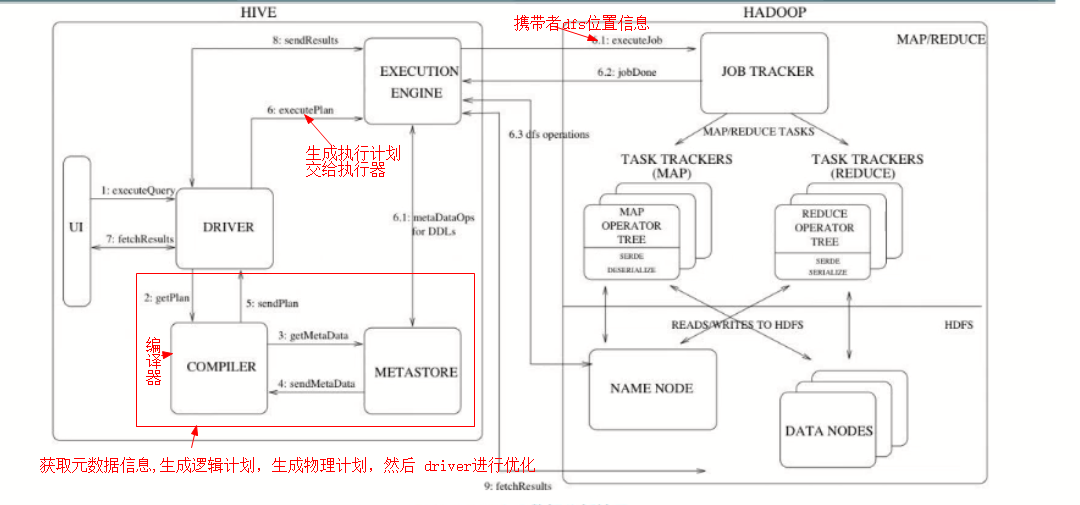
hive hadoop交互过程
![]()
驱动( Driver )
编译器( hive 的核心)
1,语法解析器( ParseDriver )
将查询字符串转换成解析树表达式
2,语法分析器( SemanticAnalyzer )
将解析树转换成基于语句块的内部查询表达式。
3,逻辑计划生成器( logical plan generator )
将内部查询表达式转换为逻辑计划,这些计划由逻辑操作树组成。
操作符是 hive 的最小处理单元 , 每个操作符处理代表一道 HDFS 操作或 MR 作业
4,查询计划生成器( query plan generator )
将逻辑计划转化成物理计划( MR Task )
优化器
优化器是一个演化组件。当前,它的规则是:列修剪,谓词下压。
执行器
编译器将操作树切分为一个 Task 链( DAG ),执行器会顺序执行其中所有 Task ;如
果 Task 链( DAG )不存在依赖关系时,可采用并发执行的方式进行 Job 的执行

 浙公网安备 33010602011771号
浙公网安备 33010602011771号