spark简介:
1,spark 做为数据分析的一种平台,没有数据存储,强调的是基于内存的(相当吃内存)数据分析,内存不够也会磁盘进行计算!
2,可以运行很多的资源管理平台之上,比如 yarn
spark 的启动:
1,通过spark-shell 进行启动(Standalone模式)
#整个集群的 cpu 核数,单个节点的的内存
# 指定 master 相当于提交到了集群之中!提交到本地不需要指定!
bin/spark-shell --master spark://node-1.cn:7077 --total-executor-cores 30 --executor-memory 5g
2,基于 yarn-cluster的提交模式(可以参考我的另一篇spark-on-yarn)
3,基于 yarn-client的提交模式
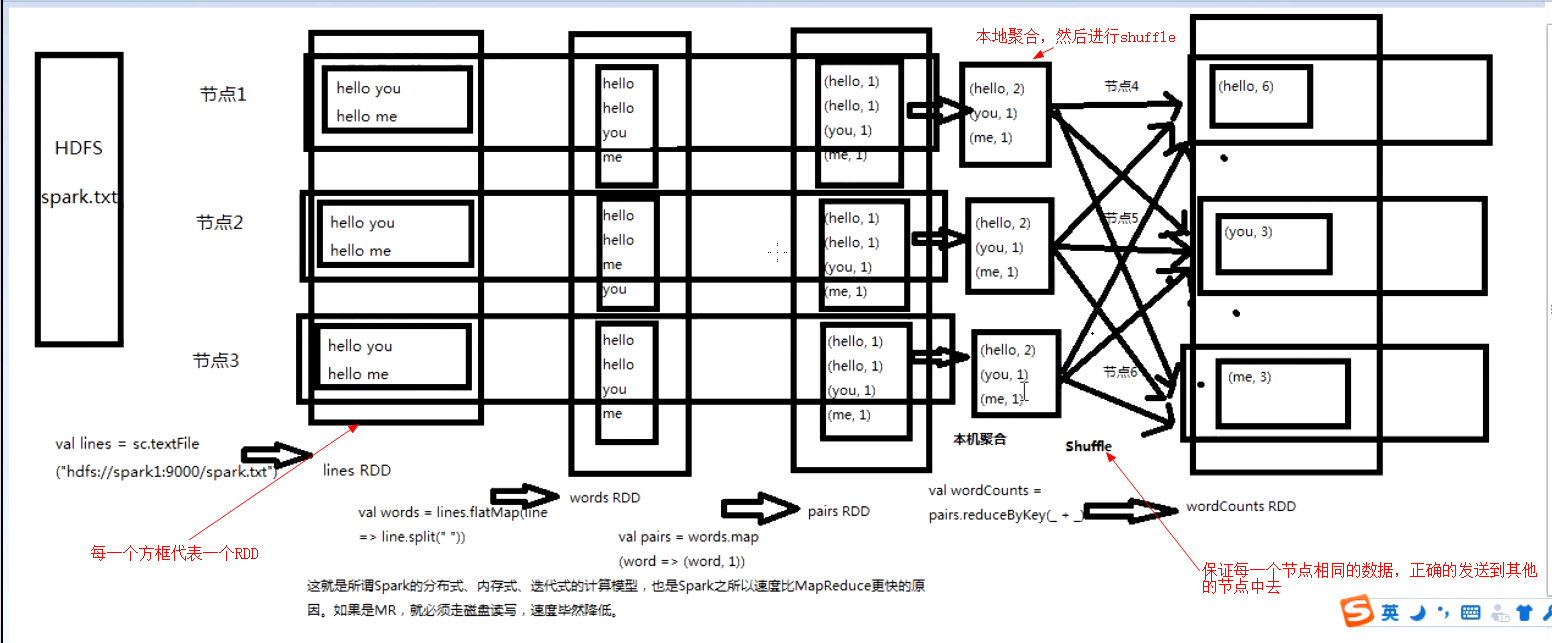
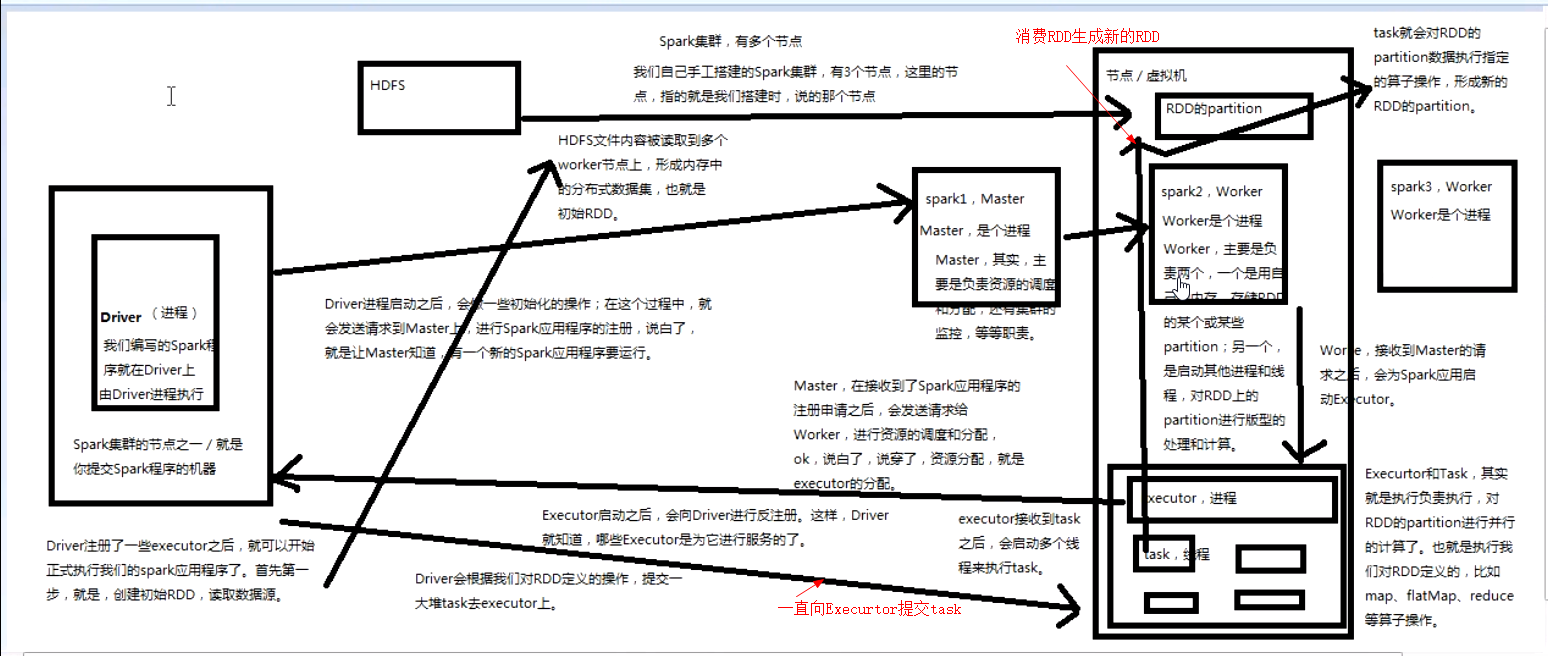
spark程序运行原理
![]()
spark组件简述(有各种进程,组件完成计算与分布式):
1,Master:管理资源的主节点(进程)
2,Cluster Manager: 集群之中获取资源的外部服务,(例如standalone,Yarn)
3,Worker Node(standalone):资源管理的从节点(进程)或者说管理本机资源的进程
4,Applation: 基于spark的用户程序,包含了driver程序和运行在集群上的executor程序
5,Executor:是在一个worker 进程所管理的节点之上为某一个 Applation启动一个进程,该进程负责运行任务,并且负责将数据存储在内存或者磁盘之上,每一个应用对应着一个 Executor
6,Task: 被送到某个 executor上的工作单元,里面封装着处理程序的逻辑,core(虚拟的cpu core)配置项控制一个 executor 中task的并发数。--executor-cores 2 意味着每个 executor 中最多同时可以有2个 task 运行。Task被执行的并发度 = Executor数目 * 每个Executor核数
7,job:包含很多任务(Task)的并行计算,可以看做和action对应
8,Stage:一组并行的task组成,一个job会拆分成很多任务(根据RDD的依赖进行切割),每组任务称之为Stage,(就像MR之中的 map task与reduce task)(可以参考另一篇博客)
9,Driver(进程),执行我们的Application 首先创建SparkContext(一个对象)(构造了 DAGScheduler 和TaskScheduler)
1),TaskScheduler(通过与它对应的进程连接Mater,向Master注册Application)
2),DAGScheduler 为每一个job创建一个stage(action动作产生),每一个stage会创建一个 Taskset
![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号