HDFS 体系架构
1,HDFS 是一个主/从(Master/Slave)体系架构,由于分布式存储的性质,集群拥有两类节点 NameNode 和 DataNode。两者是通过rpc通信的
2,NameNode(名字节点):系统中通常只有一个,中心服务器的角色,管理存储和检索多个 DataNode 的实际数据所需的所有元数据。
3,DataNode(数据节点):系统中通常有多个,是文件系统中真正存储数据的地方,在
4,NameNode 统一调度下进行数据块的创建、删除和复制。
HDFS 读写过程
1,读过程
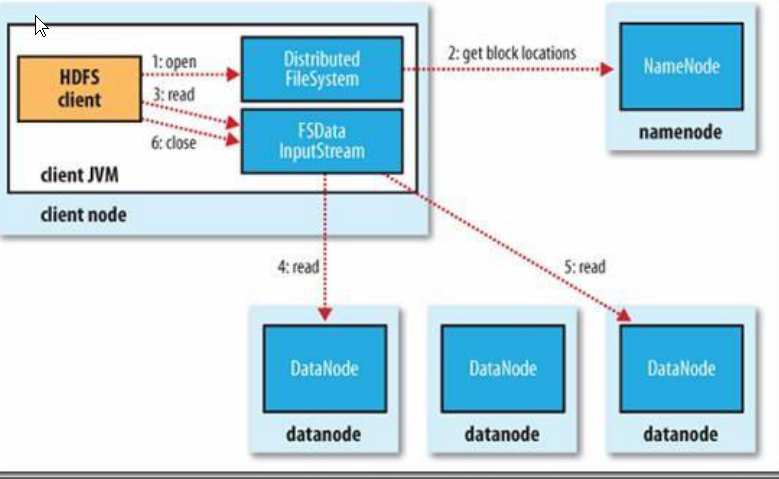
首先 Client 通过 File System 的 Open 函数打开文件,Distributed File System 用 RPC调用 NameNode 节点,得到文件的数据块信息。对于每一个数据块,NameNode 节点返回保存数据块的数据节点的地址。Distributed File System 返回 FSDataInputStream 给客户端,用来读取数据。客户端调用 stream 的 read()函数开始读取数据。DFSInputStream连接保存此文件第一个数据块的最近的数据节点。DataNode 从数据节点读到客户端(client),当此数据块读取完毕时,DFSInputStream 关闭和此数据节点的连接,然后连接此文件下一个数据块的最近的数据节点。当客户端读取完毕数据的时候,调用FSDataInputStream 的 close 函数。在读取数据的过程中,如果客户端在与数据节点通信出现错误,则尝试连接包含此数据块的下一个数据节点。失败的数据节点将被记录,以后不再连接。
2,写过程
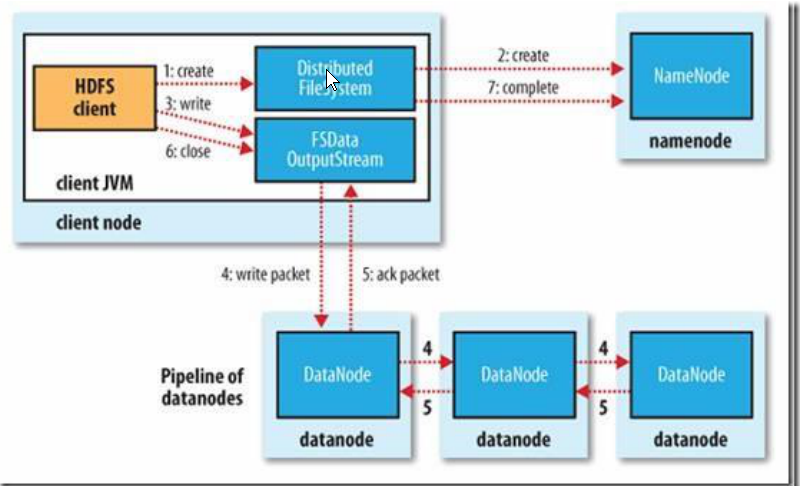
客户端调用 create()来创建文件,Distributed File System 用 RPC 调用 NameNode节点,在文件系统的命名空间中创建一个新的文件。NameNode 节点首先确定文件原来不存在,并且客户端有创建文件的权限,然后创建新文件。Distributed File System 返回 DFSOutputStream,客户端用于写数据。客户端开始写入数据,DFSOutputStream 将数据分成块,写入 Data Queue。Data Queue 由 DataStreamer 读取,并通知 NameNode 节点分配数据节点,用来存储数据块(每块默认复制 3块)。分配的数据节点放在一个 Pipeline 里。Data Streamer 将数据块写入 Pipeline 中的第一个数据节点。第一个数据节点将数据块发送给第二个数据节点。第二个数据节点将数据发送给第三个数据节点。DFSOutputStream 为发出去的数据块保存了 Ack Queue,等待 Pipeline 中的数据节点告知数据已经写入成功。HDFS shell(一个client 连接端) 的基本操作命令
1,打印文件列表
hdfs dfs -ls hdfs:/ # 标准写法 hdfs: 明确说明是 HDFS 系统路径
'''以下简写'''
hdfs dfs -ls / # 打印HDFS 系统下的根目录
hdfs dfs -ls -r /package/test/ #打印指定文件目录 -r(递归)
2,上传文件、目录. -f 才会覆盖,有可能会 File exists
hdfs dfs -put /root/test.txt hdfs:/ #上传本地 test.txt 文件到 HDFS 根目录
hdfs dfs -put test.txt /test2.txt #上传并重命名文件。
hdfs dfs -put test1.txt test2.txt hdfs:/ #一次上传多个文件到 HDFS 路径。
#上传文件夹:
hdfs dfs -put mypkg /newpkg #上传并重命名了文件夹。
# -f 覆盖上传
hdfs dfs -put -f /root/test.txt / #如果 HDFS 目录中有同名文件会被覆盖
#上传文件并重命名:-copyFromLocal(重命名) -f(覆盖)
hdfs dfs -copyFromLocal /test.txt hdfs:/test2.txt
#覆盖上传:
hdfs dfs -copyFromLocal -f test.txt /test.txt
3,下载文件、目录
'''拷贝到本地'''
#拷贝文件到本地目录:
hdfs dfs -get hdfs:/test.txt /root
#拷贝文件并重命名,可以简写:
hdfs dfs -get /test.txt /root/test.txt
#从本地到 HDFS,同 put
hdfs dfs -cp /test.txt hdfs:/test2.txt
# 从 HDFS 到 HDFS
hdfs dfs -cp hdfs:/test.txt hdfs:/test2.txt
hdfs dfs -cp /test.txt /test2.txt
4,移动与删除文件
hdfs dfs -mv hdfs:/test.txt hdfs:/dir/test.txt
hdfs dfs -mv /test/slaves /testdir # 把/test/slaves 复制到 /testdir
#删除指定文件
hdfs dfs -rm /a.txt
#删除全部 txt 文件
hdfs dfs -rm /*.txt
#递归删除全部文件和目录
hdfs dfs -rm -R /dir/
5,读取与创建文件
hdfs dfs -cat /test.txt #以字节码的形式读取
hdfs dfs -tail /test.t #
hdfs dfs - touchz /newfile.txt #创建文件
hdfs dfs -mkdir /newdir /newdir2 #可以同时创建多个
hdfs dfs -mkdir -p /newpkg/newpkg2/newpkg3 #同时创建父级目录
# ./hdfs dfs -mkdir -p hdfs://sr128:9000/shared/spark-logs
6,获取逻辑空间文件、目录大小
hdfs dfs - du / #显示 HDFS 根目录中各文件和文件夹大小
hdfs dfs -du -h / #以最大单位显示 HDFS 根目录中各文件和文件夹
hdfs dfs -du -s / #仅显示 HDFS 根目录大小。即各文件和文件夹大小之和
hadoop 集群之间的文件拷贝
1,hadoop 自带一种并行复制的程序,可以并行的从hadoop文件系统之中复制大量数据
2,diskcp 是作为一个 MapReduce 来进行实现的,只有 map 没有reduce,默认20个map使用
#Distcp 两个集群之间互相拷贝,并行执行的 map reduce 任务
# 如果 bar 文件存在,就会复制到bar文件之内,可以使用 -overwrite 进行覆盖
./hadoop distcp hdfs://master1:9000/H/K/ hdfs://master2:9000/H/K
#不同版本之间的拷贝 前者目标主机(namenode ui端口) 后者目的主机(hdfs rpc端口)
hadoop distcp hftp:/master1:50070/foo/bar hdfs:/master2:8020/foo/bar
job 工具可以检查当前 job的状态
./hadoop job -list
./hadoop job -kill <job_id>
./hadoop job -kill-task <attempt_id>
查看 hdfs 集群 运行状态
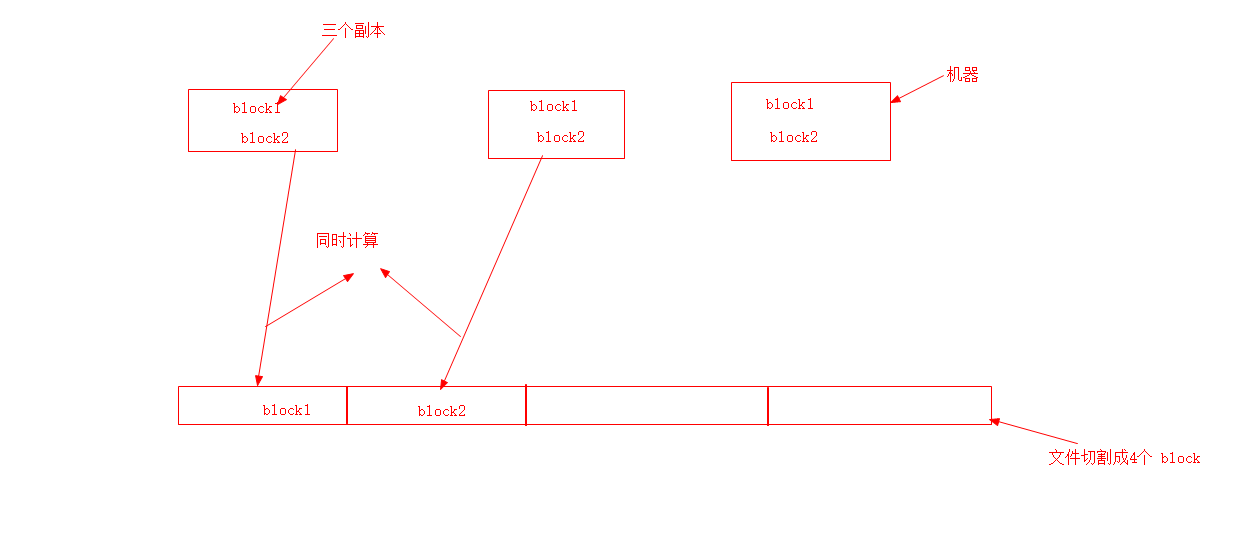
计算向数据移动实例
首先创建
./hdfs dfs -D dfs.blocksize=1048576 -put logs.txt /user/logs.txt
我们可以使用 getFileBlockLocations(来自java 代码) 获取文件块信息, 得到块在哪个节点,然后实现计算向数据移动
Path i = new Path("/user/logs.txt")
fileStatus ifile = fs.getFileBlockLocations(ifile,0,ifle.getLen())
// 使用增强for循环
for (BlockLocation b: blak){
System.out.println(b)
/*
0,1048576,node1,node2
1048576,543234,node2,node3
* */
}
