Apache Atlas 2.1.0编译部署手册
环境准备
组件版本
| 组件 | 部署版本 | 源码版本 |
|---|---|---|
| os | CentOS 7.6.1810 | -- |
| java | 1.8.0_252 | -- |
| zookeeper | 3.4.14 | 3.4.6 |
| kafka | 2.11-2.0.0 | 2.11-2.0.0 |
| hadoop | 3.1.1 | 3.1.1 |
| hbase | 2.0.2 | 2.0.2 |
| solr | 7.5.0 | 7.5.0 |
| hive | 3.1.0 | 3.1.0 |
| atlas | 2.1.0 | 2.1.0 |
角色分配
| 组件 | n1 192.168.222.11 |
n2 192.168.222.12 |
n3 192.168.222.13 |
|---|---|---|---|
| JDK | √ | √ | √ |
| zookeeper | √ | √ | √ |
| kafka | √ | √ | √ |
| NameNode | √ | -- | -- |
| SecondaryNameNode | -- | -- | √ |
| MR JobHistory Server | -- | -- | √ |
| DataNode | √ | √ | √ |
| ResourceManager | -- | √ | -- |
| NodeManager | √ | √ | √ |
| hbase | √ | √ | √(Master) |
| solr | √ | √ | √ |
| hive | √ | -- | -- |
| MySQL | √ | -- | -- |
| atlas | √ | -- | -- |
配置域名解析
在各节点 /etc/hosts 文件中新增如下内容
192.168.222.11 n1
192.168.222.12 n2
192.168.222.13 n3
配置Maven
修改 conf/settings.xml 配置文件如下内容
<!-- 修改Maven包存放路径 -->
<localRepository>/home/atlas/maven_packages</localRepository>
<!-- 修改镜像 -->
<mirror>
<id>mirrorId</id>
<mirrorOf>repositoryId</mirrorOf>
<name>Human Readable Name for this Mirror.</name>
<url>http://my.repository.com/repo/path</url>
</mirror>
-->
<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<url>https://maven.aliyun.com/repository/public</url>
<mirrorOf>central</mirrorOf>
</mirror>
<mirror>
<id>Central</id>
<mirrorOf>central</mirrorOf>
<name>Central Maven</name>
<url>https://repo1.maven.org/maven2</url>
</mirror>
环境变量
export MAVEN_OPTS="-Xms4g -Xmx4g"
export MAVEN_HOME=/home/atlas/maven-3.6.3
export PATH=$MAVEN_HOME/bin:$PATH
配置SSH免密
- 在各节点执行
ssh-keygen -t rsa,输入三次回车完成配置 - 将n2、n3节点的/root/.ssh/id_rsa.pub复制到n1节点,并重命名成对应的节点名称
scp n2:/root/.ssh/id_rsa.pub /root/n2 scp n3:/root/.ssh/id_rsa.pub /root/n3 - 在n1节点上,将所有节点的 id_rsa.pub 内容写入至n1节点的 /root/.ssh/authorized_keys 文件中
cat /root/.ssh/id_rsa.pub > /root/.ssh/authorized_keys cat /root/n2 >> /root/.ssh/authorized_keys cat /root/n3 >> /root/.ssh/authorized_keys - 在n1节点使用ssh登陆各节点(包含本机),填充 known_hosts 文件
- 将n1节点上的 authorized_keys 和 known_hosts 复制到其余各节点的 /root/.ssh/ 目录中
在每个节点测试免密码登陆是否生效scp /root/.ssh/authorized_keys n2:/root/.ssh scp /root/.ssh/authorized_keys n3:/root/.ssh scp /root/.ssh/known_hosts n2:/root/.ssh scp /root/.ssh/known_hosts n3:/root/.ssh
配置时间同步
- 是执行 rpm -qa | grep chrony 检查是否已经安装chrony;若没有,执行 yum -y install chrony 安装
- vim /etc/chrony.conf 修改如下
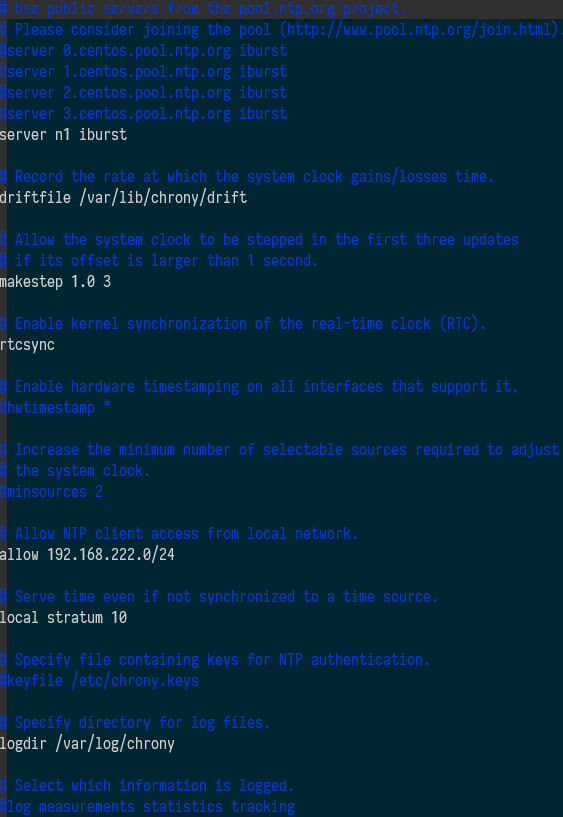
- 同步各节点的 chrony.conf 配置
- 启动chrony服务并设为开机启动
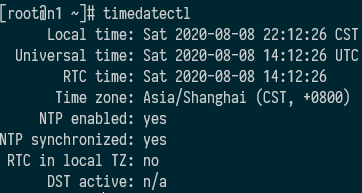
systemctl enable chronyd.service systemctl start chronyd.service systemctl status chronyd.service - 检查是否已经同步:timedatectl(NTP synchronized)
Java环境变量
export JAVA_HOME=/home/atlas/jdk8
export JRE_HOME=$JAVA_HOME/jre
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH:$HOME/.local/bin:$HOME/bin
export CLASSPATH=$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib:$CLASSPAT
配置本地yum源
- 在n1节点创建 /etc/yum.repos.d/base.repo 文件,并增加如下内容源到repo文件中
[Local_ISO] name=Loacal ISO baseurl=file:///mnt gpgcheck=0 enabled=1 - 在n1节点执行
mount /dev/sr0 /mnt挂载系统光盘到/mnt目录 - 上传 createrepo-0.9.9-28.el7.noarch.rpm 文件到n1节点的 /root/files/ 中,并执行
yum -y localinstall /root/files/createrepo-0.9.9-28.el7.noarch.rpm,所需要的两个依赖包可以在系统光盘中找到 - 在c1节点创建/root/rpms路径,将需要的rpm包都上传到该路径下
- 向 /etc/yum.repos.d/base.repo 文件添加如下内容
[Local_RPM] name=Loacal RPM baseurl=http://cm:10040/rpms gpgcheck=0 enabled=1 - 在n1节点 /root 目录中执行
python -m SimpleHTTPServer 10040
编译打包Atlas
编译Atlas
mvn clean -DskipTests install -e
npm-6.13.7.tgz无法下载
自行下载 npm-6.13.7.tgz 后放入 /home/atlas/maven_packages/com/github/eirslett/npm/6.13.7/ 目录,并重命名为 npm-6.13.7.tar.gz
提示信息:Downloading http://registry.npmjs.org/npm/-/npm-6.13.7.tgz to /home/atlas/maven_packages/com/github/eirslett/npm/6.13.7/npm-6.13.7.tar.gz
node-sass无法安装
在用户home目录下创建.npmrc,在该文件内写入国内镜像源
registry=https://registry.npm.taobao.org/
sass_binary_site=https://npm.taobao.org/mirrors/node-sass
chromedriver_cdnurl=https://npm.taobao.org/mirrors/chromedriver
phantomjs_cdnurl=https://npm.taobao.org/mirrors/phantomjs
electron_mirror=https://npm.taobao.org/mirrors/electron
更多原因参见这里
打包Atlas
# 不使用内置hbase和solr
mvn clean -DskipTests package -Pdist
# 使用内置hbase和solr
mvn clean -DskipTests package -Pdist,embedded-hbase-solr
打包完成后产生如下文件
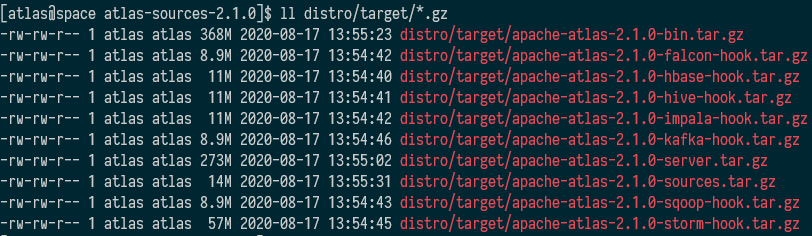
上传编译好的文件
上传 apache-atlas-2.1.0-server.tar.gz 文件
tar -zxf apache-atlas-2.1.0-server.tar.gz
mv apache-atlas-2.1.0/ atlas-2.1.0/
cd atlas-2.1.0/
安装必要组件
安装Zookeeper-3.4.14
- 上传 zookeeper-3.4.14.tar.gz 并解压缩
- 创建 zookeeper-3.4.14/zkData 目录
- 在 zookeeper-3.4.14/zkData 目录中创建myid文件
- 将 zookeeper-3.4.14 目录分发到各节点
- 修改各节点 zookeeper-3.4.14/zkData/myid 的整数值,即节点编号,各节点唯一。
- 进入 zookeeper-3.4.14/conf 目录,将zoo_sample.cfg重命名为zoo.cfg
- 修改 zoo.cfg 的如下参数
server.A=B:C:DdataDir=/root/zookeeper-3.4.14/zkData server.1=n1:2888:3888 server.2=n2:2888:3888 server.3=n3:2888:3888- A: 数字,表示第几号服务器。集群模式下配置一个文件myid,该文件在dataDir目录下,这个文件里面有一个数据就是A的值。Zookeeper启动时读取此文件,拿到里面的数据与zoo.cfg里面的配置信息比较从而判断到底是哪个server。
- B: 是这个服务器的IP地址或域名
- C: 是这个服务器与集群中的Leader服务器交换信息的端口
- D: 执行选举时服务器间通信端口
- 同步各节点的 zookeeper-3.4.14/conf/zoo.cfg 配置
- 启停与状态查看,在各节点执行
- 启动:zookeeper-3.4.14/bin/zkServer.sh start
- 停止:zookeeper-3.4.14/bin/zkServer.sh stop
- 状态:zookeeper-3.4.14/bin/zkServer.sh status
安装kafka_2.11-2.0.0
- 在
.bash_profile中增加如下变量export KAFKA_HOME=/root/kafka_2.11-2.0.0 export PATH=$PATH:${KAFKA_HOME}/bin - 创建 kafka_2.11-2.0.0/kfData 目录,用于存放kafka数据
- 打开
config/server.properties,主要修改参数如下所示broker.id=1 delete.topic.enable=true listeners=PLAINTEXT://:9092 log.dirs=/root/kafka_2.11-2.0.0/kfData zookeeper.connect=n1:2181,n2:2181,n3:2181- broker.id:每个broker配置唯一的整数值
- advertised.listeners:若只在内部使用kafka,则配置listeners即可。若需要内外网分开控制,则配置该参数
- delete.topic.enable:允许删除topic
- log.dirs:kafka数据存放目录
- 将 config/server.properties 文件分发到各 broker,并修改 broker.id 的数值
- 在各节点执行
./bin/kafka-server-start.sh -daemon ./config/ server.properties启动kafka。
安装hadoop-3.1.1
-
配置系统环境变量
在.bash_profile中配置如下内容export HADOOP_HOME=/root/hadoop-3.1.1 export PATH=$PATH:${HADOOP_HOME}/bin -
核心配置文件
在 hadoop-3.1.1/etc/hadoop/core-site.xml 文件中修改如下配置<!-- 指定HDFS中NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://n1:9000</value> </property> <!-- 指定Hadoop运行时产生文件的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/root/hadoop-3.1.1/data/tmp</value> </property> <property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property> -
HDFS配置文件
在 hadoop-3.1.1/etc/hadoop/hadoop-evn.sh 修改如下配置export JAVA_HOME=/root/jdk8 export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root在 hadoop-3.1.1/etc/hadoop/hdfs-site.xml 修改如下配置
<property> <name>dfs.replication</name> <value>3</value> </property> <!-- 指定Hadoop SecondaryNameNode --> <property> <name>dfs.namenode.secondary.http-address</name> <value>n3:50090</value> </property> <!-- NameNode本地存放namespace和transaction日志路径 --> <property> <name>dfs.namenode.name.dir</name> <value>/root/hadoop-3.1.1/data/namenode</value> </property> <!-- 32MB --> <property> <name>dfs.blocksize</name> <value>33554432</value> </property> <!-- DataNode本地存放路径 --> <property> <name>dfs.datanode.data.dir</name> <value>/root/hadoop-3.1.1/data/datanode</value> </property> -
YARN配置文件
在 hadoop-3.1.1/etc/hadoop/yarn-site.xml 修改如下配置<!-- Reducer获取数据的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定Yarn的ResourceManager地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>n2</value> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> -
MapReduce配置文件
在 hadoop-3.1.1/etc/hadoop/mapred-site.xml 修改如下配置<!-- 指定MR运行在Yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=/root/hadoop-3.1.1</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=/root/hadoop-3.1.1</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=/root/hadoop-3.1.1</value> </property> <!--jobhistory地址--> <property> <name>mapreduce.jobhistory.address</name> <value>shucang-26:10020</value> <description>MapReduce JobHistory Server IPC host:port</description> </property> <!--通过浏览器访问jobhistory的地址--> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>shucang-26:19888</value> <description>MapReduce JobHistory Server Web UI host:port</description> </property> <!--MapReduce作业运行完之后放到哪里--> <property> <name>mapreduce.jobhistory.done-dir</name> <value>/job/history/done</value> </property> <!--正在运行中的放到哪--> <property> <name>mapreduce.jobhistory.intermediate-done-dir</name> <value>/job/history/done_intermediate</value> </property> <!--每个Job Counter的数量--> <property> <name>mapreduce.job.counters.limit</name> <value>500</value> </property> <!--每个Map任务内存上限--> <property> <name>mapreduce.map.memory.mb</name> <value>2048</value> </property> <!--每个Job Counter的数量,建议为mapreduce.map.memory.mb的80%--> <property> <name>mapreduce.map.java.opts</name> <value>-Xmx1638m</value> </property> <!--每个Reduce任务内存上限--> <property> <name>mapreduce.reduce.memory.mb</name> <value>2048</value> </property> <!--每个Job Counter的数量,建议为mapreduce.reduce.memory.mb的80%--> <property> <name>mapreduce.reduce.java.opts</name> <value>-Xmx1638m</value> </property> -
workers配置文件
在hadoop-3.0.0/etc/hadoop/workers添加数据节点。该文件中添加的内容结尾不允许有空格,文件中不允许有空行。n1 n2 n3 -
将Hadoop分发到各节点
-
首次启动进群需执行格式化
hadoop-3.1.1/bin/hdfs namenode -format -
在 n1 上执行
/root/hadoop-3.1.1/sbin/start-dfs.sh启动HDFS -
在 n2 上执行
/root/hadoop-3.1.1/sbin/start-yarn.sh启动Yarn -
在 n3 上执行
/root/hadoop-3.1.1/bin/mapred --daemon start historyserver启动MR Job History Server -
执行如下命令测试HDFS和MapReduce
hadoop fs -mkdir -p /tmp/input hadoop fs -put $HADOOP_HOME/README.txt /tmp/input export hadoop_version=`hadoop version | head -n 1 | awk '{print $2}'` hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-$hadoop_version.jar wordcount /tmp/input /tmp/output
安装hbase-2.0.2
- 配置系统变量
在.bash_profile中配置下面的环境变量export HBASE_HOME=/root/hbase-2.0.2 export PATH=$PATH:${HBASE_HOME}/bin - hbase-env.sh 修改内容
export JAVA_HOME=/root/jdk8 # Configure PermSize. Only needed in JDK7. You can safely remove it for JDK8+ # export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m" # export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m" export HBASE_MANAGES_ZK=false - hbase-site.xml 修改内容
<property> <name>hbase.rootdir</name> <value>hdfs://n1:9000/hbase</value> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <!-- 0.98后的新变动,之前版本没有.port,默认端口是60000 --> <!-- 16000是默认值不配也可以,WEBUI端口是16010 --> <property> <name>hbase.master.port</name> <value>16000</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>n1,n2,n3</value> </property> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/root/zookeeper-3.4.14/zkData</value> </property> <property> <name>hbase.unsafe.stream.capability.enforce</name> <value>false</value> </property> - regionservers 修改内容
n1 n2 n3 - 将hbase分发到各节点
- 在各节点,软连接hadoop配置文件到hbase
ln -s /root/hadoop-3.1.1/etc/hadoop/core-site.xml /root/hbase-2.0.2/conf/core-site.xml ln -s /root/hadoop-3.1.1/etc/hadoop/hdfs-site.xml /root/hbase-2.0.2/conf/hdfs-site.xml
安装Solr-7.5.0
- 执行 tar -zxf solr-7.5.0.tgz
- 进入solr目录,修改 bin/solr.in.sh 如下参数
ZK_HOST="n1:2181,n2:2181,n3:2181" # 不同的节点配置不同的SOLR_HOST SOLR_HOST="n1" - 将 /opt/solr 目录分发到其他节点,并修改SOLR_HOST的值
- 在各节点 /etc/security/limits.conf 文件中,添加如下内容,重启后生效
root hard nofile 65000 root soft nofile 65000 root hard nproc 65000 root soft nproc 65000 - 在个节点执行 bin/solr start启动solr
/opt/solr/bin/solr start
MySQL-5.7.30
- 执行 rpm -qa | grep mariadb 检查是否安装了 mariadb。若存在则执行 rpm -e --nodeps xxx 进行删除
- 将 mysql-5.7.26-1.el7.x86_64.rpm-bundle.tar 上传至n1节点的 /root/rmps 目录中,并解压
- 执行
createrepo -d /root/rpms/ && yum clean all - 执行
yum -y install mysql-community-server mysql-community-client - 修改 /etc/my.cnf
[mysqld] # Remove leading # and set to the amount of RAM for the most important data # cache in MySQL. Start at 70% of total RAM for dedicated server, else 10%. # innodb_buffer_pool_size = 128M # # Remove leading # to turn on a very important data integrity option: logging # changes to the binary log between backups. log_bin=/var/lib/mysql/mysql_binary_log # # Remove leading # to set options mainly useful for reporting servers. # The server defaults are faster for transactions and fast SELECTs. # Adjust sizes as needed, experiment to find the optimal values. # join_buffer_size = 128M # sort_buffer_size = 2M # read_rnd_buffer_size = 2M datadir=/var/lib/mysql socket=/var/lib/mysql/mysql.sock transaction-isolation = READ-COMMITTED # Disabling symbolic-links is recommended to prevent assorted security risks symbolic-links=0 #In later versions of MySQL, if you enable the binary log and do not set ##a server_id, MySQL will not start. The server_id must be unique within ##the replicating group. server_id=1 key_buffer_size = 32M max_allowed_packet = 32M thread_stack = 256K thread_cache_size = 64 query_cache_limit = 8M query_cache_size = 64M query_cache_type = 1 max_connections = 250 log-error=/var/log/mysqld.log pid-file=/var/run/mysqld/mysqld.pid character-set-server=utf8 binlog_format = mixed read_buffer_size = 2M read_rnd_buffer_size = 16M sort_buffer_size = 8M join_buffer_size = 8M # InnoDB settings innodb_file_per_table = 1 innodb_flush_log_at_trx_commit = 2 innodb_log_buffer_size = 64M innodb_buffer_pool_size = 4G innodb_thread_concurrency = 8 innodb_flush_method = O_DIRECT innodb_log_file_size = 512M [mysqld_safe] log-error=/var/log/mysqld.log pid-file=/var/run/mysqld/mysqld.pid sql_mode=STRICT_ALL_TABLES [client] default-character-set=utf8 - 设置 MySQL 开机启动
systemctl enable mysqld.service systemctl start mysqld.service systemctl status mysqld.service - 执行
grep password /var/log/mysqld.log获得初始密码 - 执行
mysql_secure_installation对MySQL做基础配置
登录MySQL,执行show variables like "%char%"; 检查字符集是否为utf8Securing the MySQL server deployment. Enter password for user root: 输入初始密码 The existing password for the user account root has expired. Please set a new password. New password: 输入新密码Root123! Re-enter new password: Root123! The 'validate_password' plugin is installed on the server. The subsequent steps will run with the existing configuration of the plugin. Using existing password for root. Estimated strength of the password: 100 Change the password for root ? ((Press y|Y for Yes, any other key for No) : n Do you wish to continue with the password provided?(Press y|Y for Yes, any other key for No) : y By default, a MySQL installation has an anonymous user, allowing anyone to log into MySQL without having to have a user account created for them. This is intended only for testing, and to make the installation go a bit smoother. You should remove them before moving into a production environment. Remove anonymous users? (Press y|Y for Yes, any other key for No) : y Success. Normally, root should only be allowed to connect from 'localhost'. This ensures that someone cannot guess at the root password from the network. Disallow root login remotely? (Press y|Y for Yes, any other key for No) : y Success. By default, MySQL comes with a database named 'test' that anyone can access. This is also intended only for testing, and should be removed before moving into a production environment. Remove test database and access to it? (Press y|Y for Yes, any other key for No) : y - Dropping test database... Success. - Removing privileges on test database... Success. Reloading the privilege tables will ensure that all changes made so far will take effect immediately. Reload privilege tables now? (Press y|Y for Yes, any other key for No) : y Success. All done!
安装Hive-3.1.0
-
配置系统变量
在.bash_profile中配置下面的环境变量export HIVE_HOME=/root/apache-hive-3.1.0-bin export PATH=$PATH:${HIVE_HOME}/bin -
配置Hive环境变量
在 apache-hive-3.1.0-bin/conf/hive-env.sh 文件中修改如下内容HADOOP_HOME=${HADOOP_HOME} export HADOOP_HEAPSIZE=2048 export HIVE_CONF_DIR=${HIVE_HOME}/conf -
在MySQL创建库及用户
CREATE DATABASE hive DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci; GRANT ALL ON hive.* TO 'hive'@'%' IDENTIFIED BY 'Hive123!'; flush privileges; -
将 mysql-connector-java-5.1.47-bin.jar 拷贝至 apache-hive-3.1.0-bin/lib/ 目录中
-
在 apache-hive-3.1.0-bin/conf/hive-site.xml 文件中修改如下内容
<property> <name>system:java.io.tmpdir</name> <value>/tmp/tmpdir</value> </property> <property> <name>system:user.name</name> <value>hive</value> </property> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://n1:3306/hive?createDatabaseIfNotExist=true&useUnicode=true&characterEncoding=UTF-8&useSSL=false</value> <description> JDBC connect string for a JDBC metastore. To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL. For example, jdbc:postgresql://myhost/db?ssl=true for postgres database. </description> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>hive</value> <description>Username to use against metastore database</description> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>Hive123!</value> <description>password to use against metastore database</description> </property> <property> <name>hive.server2.authentication</name> <value>NONE</value> <description> Expects one of [nosasl, none, ldap, kerberos, pam, custom]. Client authentication types. NONE: no authentication check LDAP: LDAP/AD based authentication KERBEROS: Kerberos/GSSAPI authentication CUSTOM: Custom authentication provider (Use with property hive.server2.custom.authentication.class) PAM: Pluggable authentication module NOSASL: Raw transport </description> </property> <!--这里配置的用户要求对inode="/tmp/hive" 有执行权限--> <property> <name>hive.server2.thrift.client.user</name> <value>root</value> <description>Username to use against thrift client</description> </property> <property> <name>hive.server2.thrift.client.password</name> <value>Root23!</value> <description>Password to use against thrift client</description> </property> <property> <name>hive.metastore.db.type</name> <value>mysql</value> <description> Expects one of [derby, oracle, mysql, mssql, postgres]. Type of database used by the metastore. Information schema & JDBCStorageHandler depend on it. </description> </property> -
执行 schematool -initSchema -dbType mysql 初始化MySQL
-
在MySQL的Hive库中执行如下语句,避免Hive表、列、分区、索引等的中文注释乱码问题
alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8; alter table TABLE_PARAMS modify column PARAM_VALUE mediumtext character set utf8; alter table PARTITION_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8; alter table PARTITION_KEYS modify column PKEY_COMMENT varchar(4000) character set utf8; alter table INDEX_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8; -
执行 mkdir -p hive-3.1.0/logs
-
执行 cp hive-log4j2.properties.template hive-log4j2.properties ,并修改如下属性
property.hive.log.dir = /root/hive-3.1.0/logs -
执行
nohup hiveserver2 1>/dev/null 2>&1 & echo $! > /app/hive-3.1.0/logs/hiveserver2.pid启动Hiveserver2 -
执行
beeline -u jdbc:hive2://shucang-24:10000/default -n root -p Root123!启动Beeline
配置Atlas
Atlas配置Solr
- 在 atlas-application.properties 中修改如下配置
atlas.graph.index.search.backend=solr atlas.graph.index.search.solr.mode=cloud # ZK quorum setup for solr as comma separated value. atlas.graph.index.search.solr.zookeeper-url=n1:2181,n2:2181,n3:2181 atlas.graph.index.search.solr.wait-searcher=true - 将 atlas 的
conf/solr目录复制到各 solr server 节点的/root/solr-7.5.0目录下,名重命名为atlas_solr/ - 在 solr server 节点,创建collection
./solr create -c vertex_index -d /root/solr-7.5.0/atlas_solr -shards 1 -replicationFactor 3 -force ./solr create -c edge_index -d /root/solr-7.5.0/atlas_solr -shards 1 -replicationFactor 3 -force ./solr create -c fulltext_index -d /root/solr-7.5.0/atlas_solr -shards 1 -replicationFactor 3 -force - 如需删除 collection,请使用下面的语句,贴入浏览器地址栏即可
http://n1:8983/solr/admin/collections?action=DELETE&name=vertex_index http://n1:8983/solr/admin/collections?action=DELETE&name=edge_index http://n1:8983/solr/admin/collections?action=DELETE&name=fulltext_index
Atlas配置Hbase
-
在 atlas-2.1.0/conf/atlas-application.properties 中修改如下配置
atlas.graph.storage.backend=hbase2 atlas.graph.storage.hbase.table=atlas atlas.graph.storage.hostname=n1:2181,n2:2181,n3:2181 -
在 atlas-env.sh 中修改如下配置
export HBASE_CONF_DIR=/root/hbase-2.0.2/conf -
将hbase配置文件复制到Atlas的 conf/hbase中
cp /root/hbase-2.0.2/conf/* /root /atlas-2.1.0/conf/hbase/ -
删除 core-site.xml 和 hdfs-site.xml 文件,重新生成软连接
ln -s /root/hadoop-3.1.1/etc/hadoop/core-site.xml /root/atlas-2.1.0/conf/hbase/core-site.xml ln -s /root/hadoop-3.1.1/etc/hadoop/hdfs-site.xml /root/atlas-2.1.0/conf/hbase/hdfs-site.xml
Altas配置Kafka
-
在 atlas-application.properties 中修改如下配置
atlas.notification.embedded=false atlas.kafka.data=/root/atlas-2.1.0/data/kafka atlas.kafka.zookeeper.connect=n1:2181,n2:2181,n3:2181 atlas.kafka.bootstrap.servers=n1:9092,n2:9092,n3:9092 atlas.kafka.zookeeper.session.timeout.ms=4000 atlas.kafka.zookeeper.connection.timeout.ms=2000 atlas.kafka.enable.auto.commit=true -
创建topic
kafka-topics.sh --zookeeper n1:2181,n2:2181,n3:2181 --create --topic ATLAS_HOOK --partitions 1 --replication-factor 3 kafka-topics.sh --zookeeper n1:2181,n2:2181,n3:2181 --create --topic ATLAS_ENTITIES --partitions 1 --replication-factor 3topic的名称可在 atlas-2.1.0/bin/atlas_config.py 中的 get_topics_to_create 方法找到,kafka设置脚本为 atlas-2.1.0/bin/atlas_kafka_setup.py
配置LDAP
-
在 atlas-application.properties 中增加/修改如下配置
atlas.authentication.method.ldap=true atlas.authentication.method.ldap.type=ldap atlas.authentication.method.ldap.url=ldap://xx.xx.xx.xx:389 atlas.authentication.method.ldap.userDNpattern=uid={0},ou=employee,dc=xx,dc=xxxx,dc=com atlas.authentication.method.ldap.groupSearchFilter=(member=uid={0},ou=employee,dc=xx,dc=xxxx,dc=com) atlas.authentication.method.ldap.groupRoleAttribute=cn atlas.authentication.method.ldap.base.dn=dc=xx,dc=xxxx,dc=com atlas.authentication.method.ldap.bind.dn=ou=employee,dc=xx,dc=xxxx,dc=com -
LDAP配置解释,参见这里
Atlas其他配置
-
在 atlas-application.properties 中修改如下配置
atlas.rest.address=http://n1:21000 atlas.server.run.setup.on.start=false atlas.audit.hbase.tablename=apache_atlas_entity_audit atlas.audit.hbase.zookeeper.quorum=n1:2181,n2:2181,n3:2181 -
将 atlas-log4j.xml 中如下内容取消注释
<appender name="perf_appender" class="org.apache.log4j.DailyRollingFileAppender"> <param name="file" value="${atlas.log.dir}/atlas_perf.log" /> <param name="datePattern" value="'.'yyyy-MM-dd" /> <param name="append" value="true" /> <layout class="org.apache.log4j.PatternLayout"> <param name="ConversionPattern" value="%d|%t|%m%n" /> </layout> </appender> <logger name="org.apache.atlas.perf" additivity="false"> <level value="debug" /> <appender-ref ref="perf_appender" /> </logger>
启动Atlas
- 按如下顺序启动各组件
顺序 节点 组件 1 n1 zookeeper 2 n1 kafka 3 n1 hdfs 4 n2 yarn 5 n3 jobhistoryserver 6 n3 hbase 7 n1 solr 8 n1 msyql 9 n1 hive 10 n1 atlas - 执行 bin/atlas_start.py
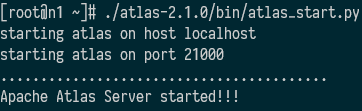
- 浏览器访问http://n1:21000
配置Hive Hook
-
在 hive-site.xml 中修改如下配置项
<property> <name>hive.exec.post.hooks</name> <value>org.apache.atlas.hive.hook.HiveHook</value> </property> -
解压 apache-atlas-2.1.0-hive-hook.tar.gz,并进入 apache-atlas-hive-hook-2.1.0 目录
-
将 apache-atlas-hive-hook-2.1.0/hook/hive 中的全部内容复制到 atlas-2.1.0/hook/hive 中
-
在 hive-env.sh 中修改如下内容
export HIVE_AUX_JARS_PATH=/root/atlas-2.1.0/hook/hive -
在 atlas-application.properties 增加如下配置
atlas.hook.hive.synchronous=false atlas.hook.hive.numRetries=3 atlas.hook.hive.queueSize=10000 atlas.cluster.name=primary atlas.kafka.zookeeper.connect=n1:2181,n2:2181,n3:2181 atlas.kafka.zookeeper.connection.timeout.ms=30000 atlas.kafka.zookeeper.session.timeout.ms=60000 atlas.kafka.zookeeper.sync.time.ms=20 -
将 atlas-application.properties 复制到hive的conf目录中
-
执行
./hook-bin/import-hive.sh将hive元数据导入atlas,用户名密码为登录atlas的用户名和密码./hook-bin/import-hive.sh -d hive_testdb …… Enter username for atlas :- admin Enter password for atlas :- …… Hive Meta Data imported successfully!!! -
进入/刷新atlas页面,在左侧的search中可看见hive已经有相关数据
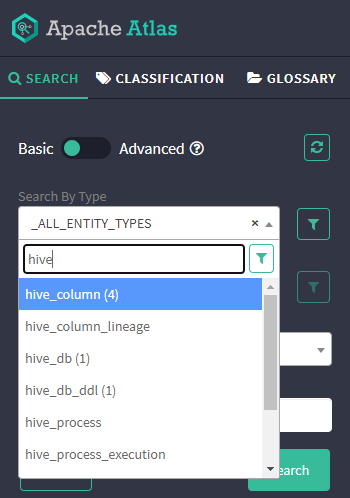
-
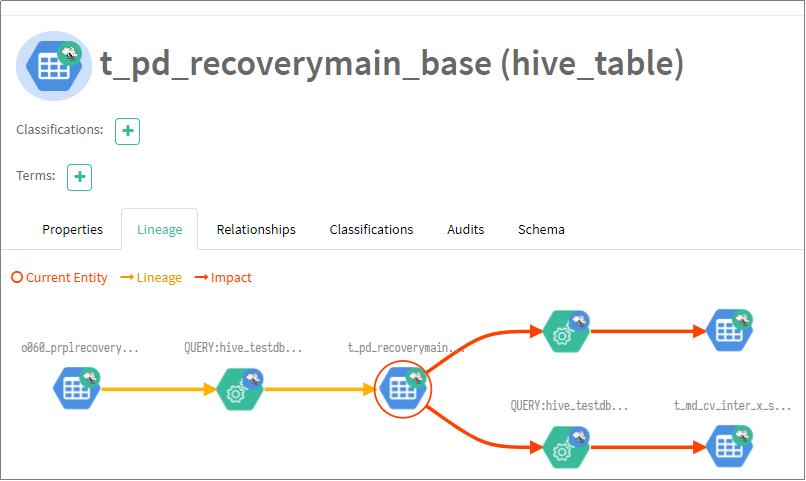
选择 hive_db(1) 点击search,结果如下图所示
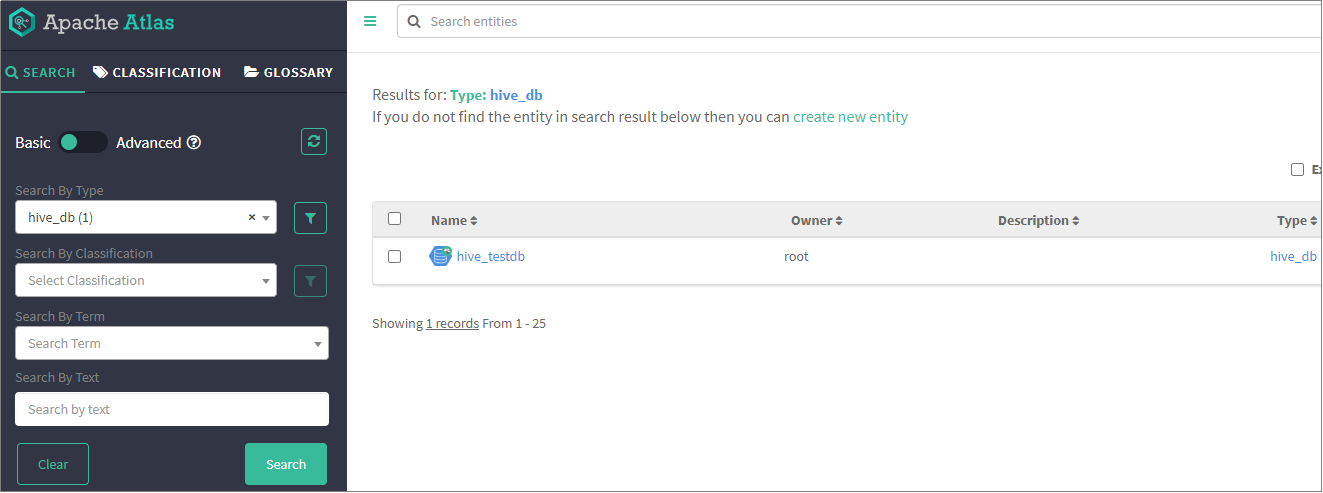
-
查看表血缘