

ComputeShader基础用法系列之四
这次接着上一篇ComputeShader基础用法系列之三来继续说。上一节说到了要通过Compute Shader进行GPU Culling。
为什么需要GPU Culling呢?使用GPU Culling能带来什么好处?
传统意义上的culling是通过相机的Cull进行的,Camera.Cull所带来的性能问题随着场景的复杂程度提高而会越来越严重。那么我们能否将Cull放到GPU来做呢,利用GPU的高并行处理机制达到转移CPU压力。
答案当然是可以的,但是像CameraCulling一样,GPU Culling同样需要包围盒数据,这就意味着需要传入数据到GPU内存。所以我们能推出以下的方法:
1.将包围盒数据通过ComputeBuffer传入GPU
2.在ComputeShader中进行Culling操作
3. 通过DrawIndirect的方式将物体绘制出来。
这里为什么要用DrawIndirect的呢?DrawIndirect是什么呢?我们来看一下:
这个方法前两个步骤都没有问题,但是第三个步骤回读CPU是个大问题,我们知道CPU和GPU之间的传输带宽在手机上是非常有限的,如果大量GPU数据回读CPU,手机上必然是难以承受的。而且还有个问题在于这样做只是确定可以把视锥外的物体Renderer禁用,但是视锥内的这些物体还是要再走一遍相机裁减,这样的话两遍裁减两边都占用性能,体验简直不要太差。 通过在PC上profiler我们可以看到直接回读cpu culling结果的问题:

Camera Culling也在执行,Gpu Culling也在执行,而且注意等待GPU返回数据这一步,相当的耗时。
关于回读CPU的代码我就不往外面粘贴了,没什么参考意义,只是用来看看回读究竟多耗性能。那么接下来我们的主角:DrawIndirect就登场了。
Graphics.DrawMeshInstancedIndirect 这个方法主要是把在显存里面的数据直接Draw到渲染管线中,而不是传统的从CPU发送数据,通过这个接口,我们就可以直接把GPU Culling的结果放到渲染管线中执行,而无需回读CPU,也可以绕过CameraCulling机制。
我们首先来看官方对于这个API的讲解:https://docs.unity3d.com/ScriptReference/Graphics.DrawMeshInstancedIndirect.html
大家可以把代码直接copy到Unity工程查看一下效果。满屏幕的小方块:
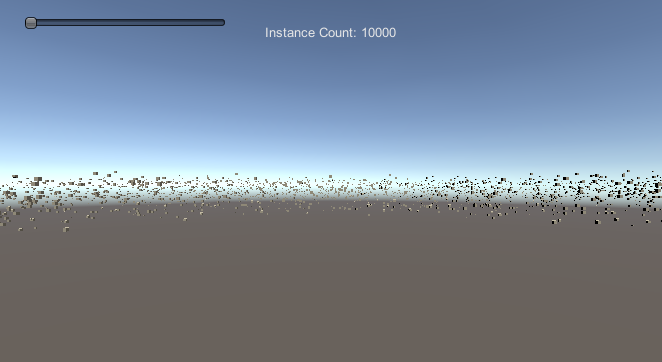
官方这个例子只是告诉我们这个API如何使用,但是并没有做Culling操作。这就会导致很多不需要Draw的信息被放入了管线中处理。
跟着官方的例子,学会使用这个接口后,就直接上代码:
代码时基于官方提供的例子进行了一点点修改:
using System.Collections; using System.Collections.Generic; using UnityEngine; public class DrawIndirectCulled : MonoBehaviour { public struct ObjInfo { public Vector3 boundMin; public Vector3 boundMax; public Matrix4x4 localToWorldMatrix; public Matrix4x4 worldToLocalMatrix; } public struct MatrixInfo { public Matrix4x4 localToWorldMatrix; public Matrix4x4 worldToLocalMatrix; } public int instanceCount = 100000; public Mesh instanceMesh; public Material instanceMaterial; public int subMeshIndex = 0; public ComputeShader compute; private int cachedInstanceCount = -1; private int cachedSubMeshIndex = -1; private ComputeBuffer positionBuffer; private ComputeBuffer argsBuffer; private ComputeBuffer cullResult; List<ObjInfo> infos = new List<ObjInfo>(); private uint[] args = new uint[5] { 0, 0, 0, 0, 0 }; private int kernel; private int visibleCount; void Start() { kernel = compute.FindKernel("CSMain"); argsBuffer = new ComputeBuffer(1, args.Length * sizeof(uint), ComputeBufferType.IndirectArguments); cullResult = new ComputeBuffer(instanceCount, sizeof(float)*32, ComputeBufferType.Append); UpdateBuffers(); } void Update() { // Update starting position buffer if (cachedInstanceCount != instanceCount || cachedSubMeshIndex != subMeshIndex) UpdateBuffers(); var camera = Camera.main; var vpMatrix = GL.GetGPUProjectionMatrix(camera.projectionMatrix,false) * camera.worldToCameraMatrix; compute.SetMatrix("vpMatrix", vpMatrix); positionBuffer.SetData(infos); compute.SetBuffer(kernel, "input", positionBuffer); cullResult.SetCounterValue(0); compute.SetBuffer(kernel, "cullresult", cullResult); compute.SetInt("instanceCount", instanceCount); compute.SetInt("visibleCount", 0); compute.Dispatch(kernel, instanceCount / 64, 1, 1); instanceMaterial.SetBuffer("positionBuffer", cullResult); // Indirect args if (instanceMesh != null) { args[0] = (uint)instanceMesh.GetIndexCount(subMeshIndex); args[1] = (uint)instanceCount; args[2] = (uint)instanceMesh.GetIndexStart(subMeshIndex); args[3] = (uint)instanceMesh.GetBaseVertex(subMeshIndex); } else { args[0] = args[1] = args[2] = args[3] = 0; } argsBuffer.SetData(args); // Pad input if (Input.GetAxisRaw("Horizontal") != 0.0f) instanceCount = (int)Mathf.Clamp(instanceCount + Input.GetAxis("Horizontal") * 40000, 1.0f, 5000000.0f); // Render Graphics.DrawMeshInstancedIndirect(instanceMesh, subMeshIndex, instanceMaterial, new Bounds(Vector3.zero, new Vector3(100.0f, 100.0f, 100.0f)), argsBuffer); } void OnGUI() { GUI.Label(new Rect(265, 25, 200, 30), "Instance Count: " + instanceCount.ToString()); instanceCount = (int)GUI.HorizontalSlider(new Rect(25, 20, 200, 30), (float)instanceCount, 1.0f, 5000000.0f); } void UpdateBuffers() { // Ensure submesh index is in range if (instanceMesh != null) subMeshIndex = Mathf.Clamp(subMeshIndex, 0, instanceMesh.subMeshCount - 1); // Positions if (positionBuffer != null) positionBuffer.Release(); positionBuffer = new ComputeBuffer(instanceCount, 152); infos.Clear(); Vector4[] positions = new Vector4[instanceCount]; for (int i = 0; i < instanceCount; i++) { ObjInfo info = default; float angle = Random.Range(0.0f, Mathf.PI * 2.0f); float distance = Random.Range(20.0f, 100.0f); float height = Random.Range(-2.0f, 2.0f); float size = Random.Range(0.05f, 0.25f); var position = new Vector3(Mathf.Sin(angle) * distance, height, Mathf.Cos(angle) * distance); info.boundMin = position - new Vector3(0.5f, 0.5f, 0.5f); info.boundMax = position + new Vector3(0.5f, 0.5f, 0.5f); info.localToWorldMatrix = Matrix4x4.TRS(position, Quaternion.identity, Vector3.one); info.worldToLocalMatrix = Matrix4x4.Inverse(info.localToWorldMatrix); infos.Add(info); } cachedInstanceCount = instanceCount; cachedSubMeshIndex = subMeshIndex; } void OnDestroy() { if (positionBuffer != null) positionBuffer.Release(); positionBuffer = null; if (argsBuffer != null) argsBuffer.Release(); argsBuffer = null; if (cullResult != null) cullResult.Release(); cullResult = null; } }
compute shader代码如下:
// Each #kernel tells which function to compile; you can have many kernels #pragma kernel CSMain struct ObjInfo { float3 boundMin; float3 boundMax; float4x4 localToWorldMatrix; float4x4 worldToLocalMatrix; }; struct MatrixInfo { float4x4 localToWorldMatrix; float4x4 worldToLocalMatrix; }; uint instanceCount; // Create a RenderTexture with enableRandomWrite flag and set it // with cs.SetTexture float4x4 vpMatrix; StructuredBuffer<ObjInfo> input; AppendStructuredBuffer<MatrixInfo> cullresult; [numthreads(64,1,1)] void CSMain (uint3 id : SV_DispatchThreadID) { if(instanceCount<=id.x) return; ObjInfo info = input[id.x]; float3 boundMax = info.boundMax; float3 boundMin = info.boundMin; float4 boundVerts[8]; float4x4 mvpMatrix = mul(vpMatrix,info.localToWorldMatrix); boundVerts[0] = mul(mvpMatrix, float4(boundMin, 1)); boundVerts[1] = mul(mvpMatrix, float4(boundMax, 1)); boundVerts[2] = mul(mvpMatrix, float4(boundMax.x, boundMax.y, boundMin.z, 1)); boundVerts[3] = mul(mvpMatrix, float4(boundMax.x, boundMin.y, boundMax.z, 1)); boundVerts[4] = mul(mvpMatrix, float4(boundMin.x, boundMax.y, boundMax.z, 1)); boundVerts[5] = mul(mvpMatrix, float4(boundMin.x, boundMax.y, boundMin.z, 1)); boundVerts[6] = mul(mvpMatrix, float4(boundMax.x, boundMin.y, boundMin.z, 1)); boundVerts[7] = mul(mvpMatrix, float4(boundMin.x, boundMin.y, boundMax.z, 1)); bool isInside = false; for (int i = 0; i < 8; i++) { float4 boundVert = boundVerts[i]; bool inside = boundVert.x <= boundVert.w && boundVert.x >= -boundVert.w && boundVert.y <= boundVert.w && boundVert.y >= -boundVert.w && boundVert.z <= boundVert.w && boundVert.z >= -boundVert.w; isInside = isInside || inside; } if (isInside) { MatrixInfo matrixInfo; matrixInfo.localToWorldMatrix = info.localToWorldMatrix; matrixInfo.worldToLocalMatrix = info.worldToLocalMatrix; cullresult.Append(matrixInfo); } }
我们会看到从脚本里面传入compute shader的包围盒信息的八个顶点都进行了转换到投影空间裁剪的操作。裁剪完成将结果buffer传入shader中,shader代码如下(为了方便,直接用了内置管线的表面着色器):
Shader "Unlit/IndirectShader" { Properties { _MainTex ("Albedo (RGB)", 2D) = "white" {} _Glossiness ("Smoothness", Range(0,1)) = 0.5 _Metallic ("Metallic", Range(0,1)) = 0.0 } SubShader { Tags { "RenderType"="Opaque" } LOD 200 CGPROGRAM // Physically based Standard lighting model #pragma surface surf Standard addshadow fullforwardshadows #pragma multi_compile_instancing #pragma instancing_options procedural:setup sampler2D _MainTex; struct Input { float2 uv_MainTex; }; #ifdef UNITY_PROCEDURAL_INSTANCING_ENABLED struct MatrixInfo { float4x4 localToWorldMatrix; float4x4 worldToLocalMatrix; }; StructuredBuffer<MatrixInfo> positionBuffer; #endif void rotate2D(inout float2 v, float r) { float s, c; sincos(r, s, c); v = float2(v.x * c - v.y * s, v.x * s + v.y * c); } void setup() { #ifdef UNITY_PROCEDURAL_INSTANCING_ENABLED MatrixInfo data = positionBuffer[unity_InstanceID]; unity_ObjectToWorld = data.localToWorldMatrix; unity_WorldToObject = data.worldToLocalMatrix; #endif } half _Glossiness; half _Metallic; void surf (Input IN, inout SurfaceOutputStandard o) { fixed4 c = tex2D (_MainTex, IN.uv_MainTex); o.Albedo = c.rgb; o.Metallic = _Metallic; o.Smoothness = _Glossiness; o.Alpha = c.a; } ENDCG } }
效果如下:

准确的视锥culling。。。
这样,Gpu culling就完成了。核心就是理解DrawIndirect这个接口和GpuInstance,这个比较基础,这里就不说了(不会用接口看官方文档的介绍,GPU Instance的原理可以自行百度,或者找个时间再写一篇扫个盲),代码没什么难度,但是跑一下发现一个问题:

可以看到set compute buffer的执行效率如此之低。因为set compute buffer实际上是cpu 向 gpu传输数据,带宽问题就会导致这个效率问题。因此我们可以把set compute buffer这一步骤移到当数量改变时再去set,但是这种程度的卡顿在游戏中实际使用时无法接受的。所以目前draw indirect和gpu culling更适合于位置旋转缩放不变的一些物体,并且有高度的重复mesh。我们可以将所有的模型预烘焙位置信息,然后数据一次放在gpu就不动了。最常见的例子就是大批量草地的渲染,通过这种方式会得到非常好的优化。
这就完了?就这?
是的,完了,本来想把基于GPU的Hi-z写一下,但是懒,嗯!在这里简单说下原理吧:
我们刚才GPU culling做的是视锥剔除,还有遮挡剔除还没有做,而通过GPU 的 Hi-z culling是常见的遮挡剔除方案。简单来说就是通过不同采样不同mip level的深度图,根据深度图和物体进行深度对比,决定哪个物体被cull,就不会被append到result中。深度图的miplevel可以直接采样低level的mipmap,但是会比较激进,因为要保证正确的遮挡剔除,必须取多个像素中深度最大的一个像素。而默认的mipmap不是这样的。
具体hiz的实现已经有很多了,这里给一个链接:https://zhuanlan.zhihu.com/p/47615677 文章来自知乎大V:MAXWELL
揉了揉困酣的双眼,看了看时间,已经是凌晨1点20了,写的内容如果有误可能是因为太困了,欢迎指正。
