

因项目需要,结合目前参与的项目,以及个人技术能力范围,组合研发一套web可视化数据同步系统,正式名称:DataXP。
项目背景:接触过阿里云这类大数据平台,对于中大型项目以及需要与外部系统对接数据的情况下,几乎都需要数据共享/分析处理/ETL同步等功能。
避免重复造轮子,首页了解了一番目前成熟的kettle这类,存在一些问题,要不是商业,要不就是主流容器化支持不太好,没有Web管理控制台等等,总之开源上想使用一款体验好,技术主流,部署简单,功能稳定来说比较困难,通常都无法直接拿过来用,多多少少有很多不足之处需要二次开发,而且设计成型跨开发语言难以二开,而且程序组件都是分散的,这里装一个那里装一个,因此决定组合一套成熟技术,开发一个通用性的数据同步系统,引入了一些开源优秀框架,其中核心组件1.XXLJob分布式调度,用于分布式调度执行节点;2.DataX阿里云DataWorks商业版本的开源版本,因为使用过DataWorks对DataX的插件设计思路很感兴趣,支持各种异构数据源同步,专业的,详情百度了解,最后打包成docker镜像,只要你有一个docker环境和mysql数据库就可以跑起来,运行非常简单。
整体架构设计思路:
1.支持容器化Docker一键部署,快速交付;
2.嘿嘿,必须是java开发语言,熟悉的SpringBoot搭建的管理后台;
3.开发两个服务1个是admin,一个是node执行器,admin负责调度,node负责执行任务;
4.admin和node分别通过源码的方式集成XxlJob的admin和client,有少许的源码改造工作,尽量保留xxljob的原汁原味,方便后期升级;node单独集成DataX3.0一起打包,admin和node会独立打包的docker镜像。
5.非必要技术一概不要,目前快速交付需要的环境:1.docker环境;2.admin镜像;3.node镜像;4.mysql数据库。
先上图:
1.登录
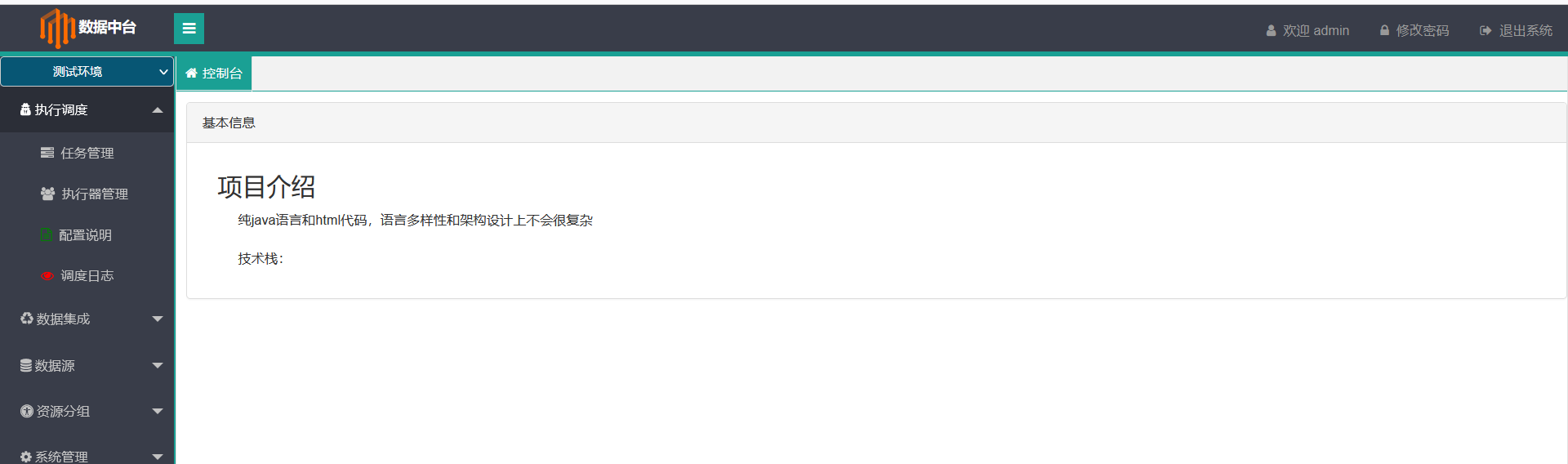
2.任务调度
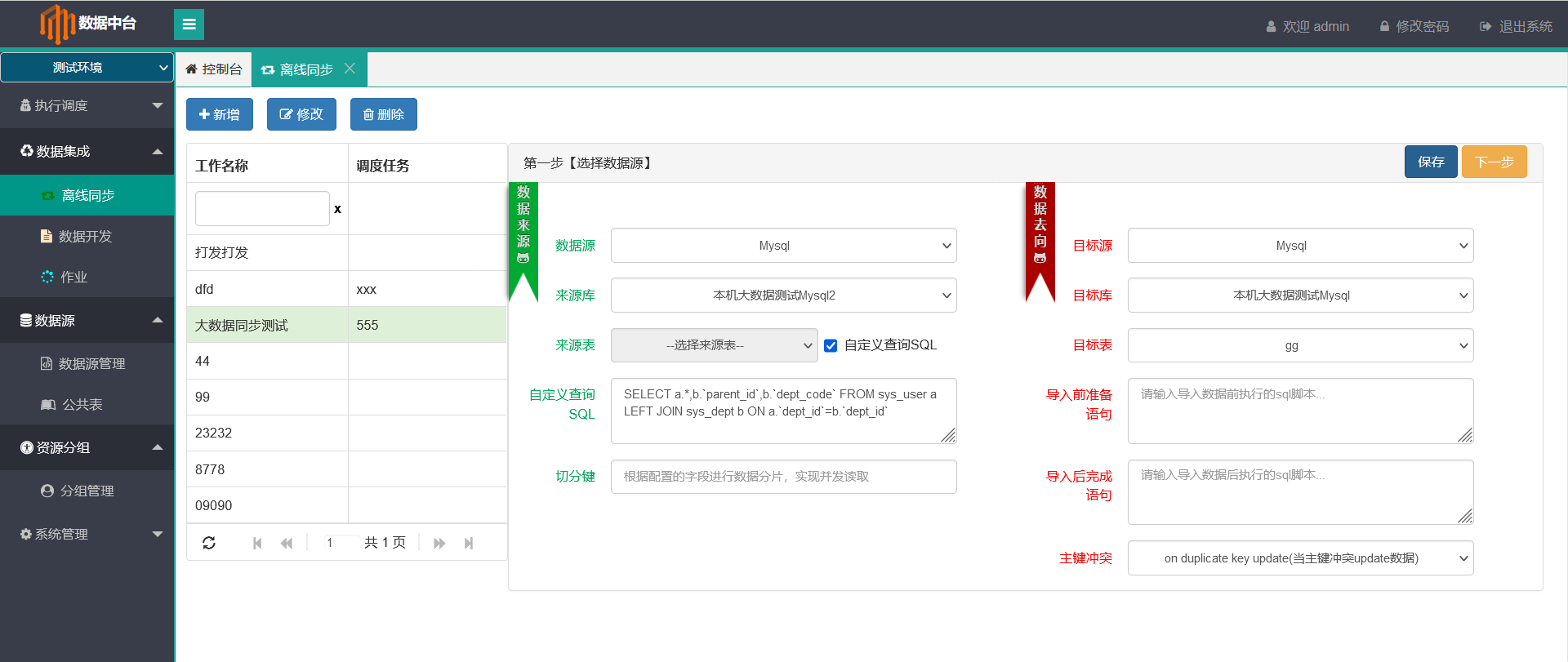
3.数据集成
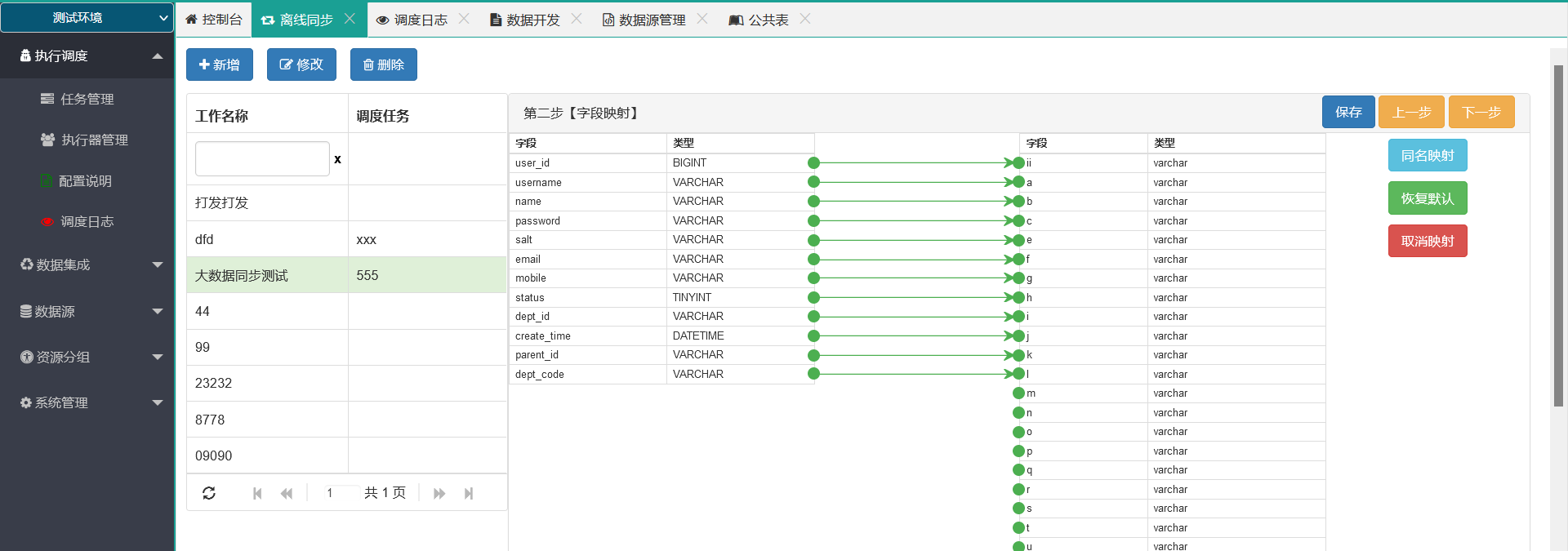
4.配置调度

5.数据开发 - 绑定了公共库的数据源变为公共表,用于中间数据处理
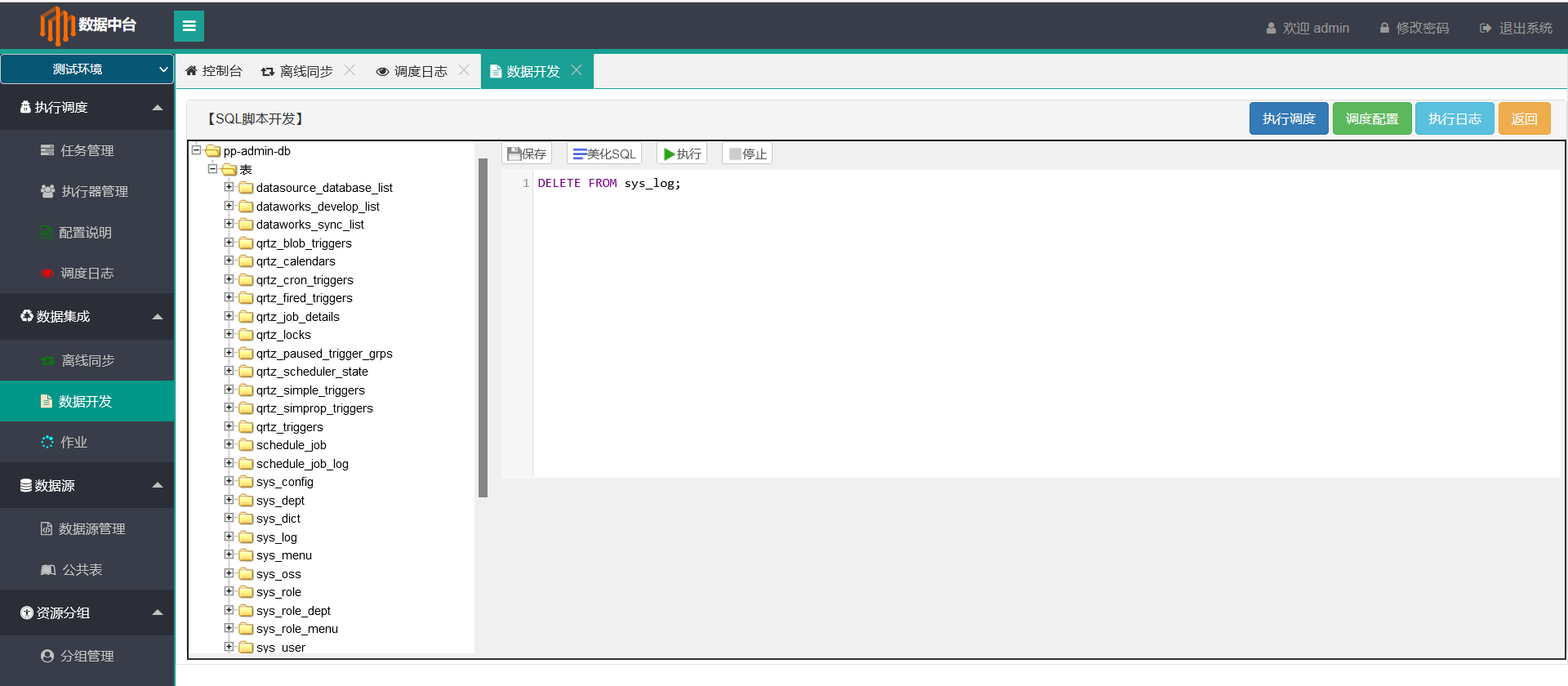
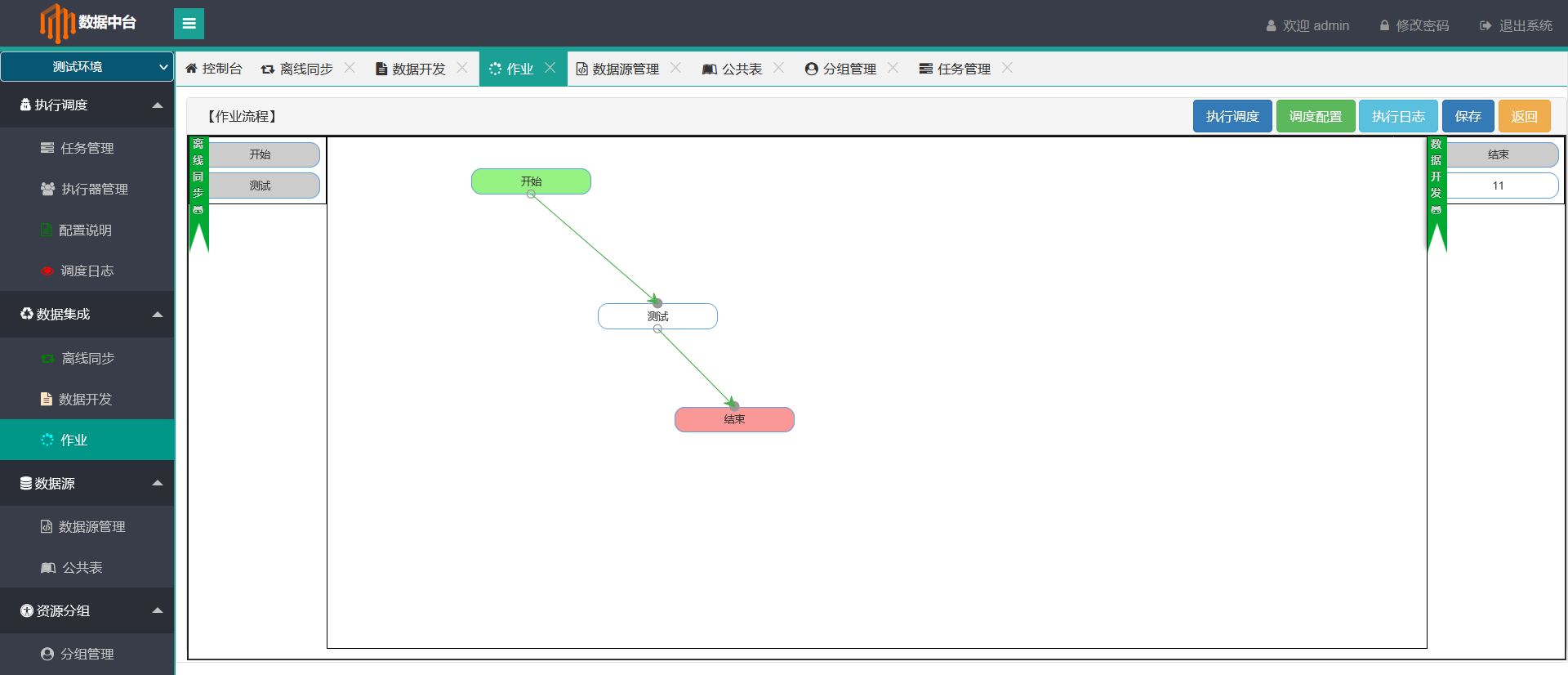
6.数据作业 - 将离线同步和数据开发串联作业
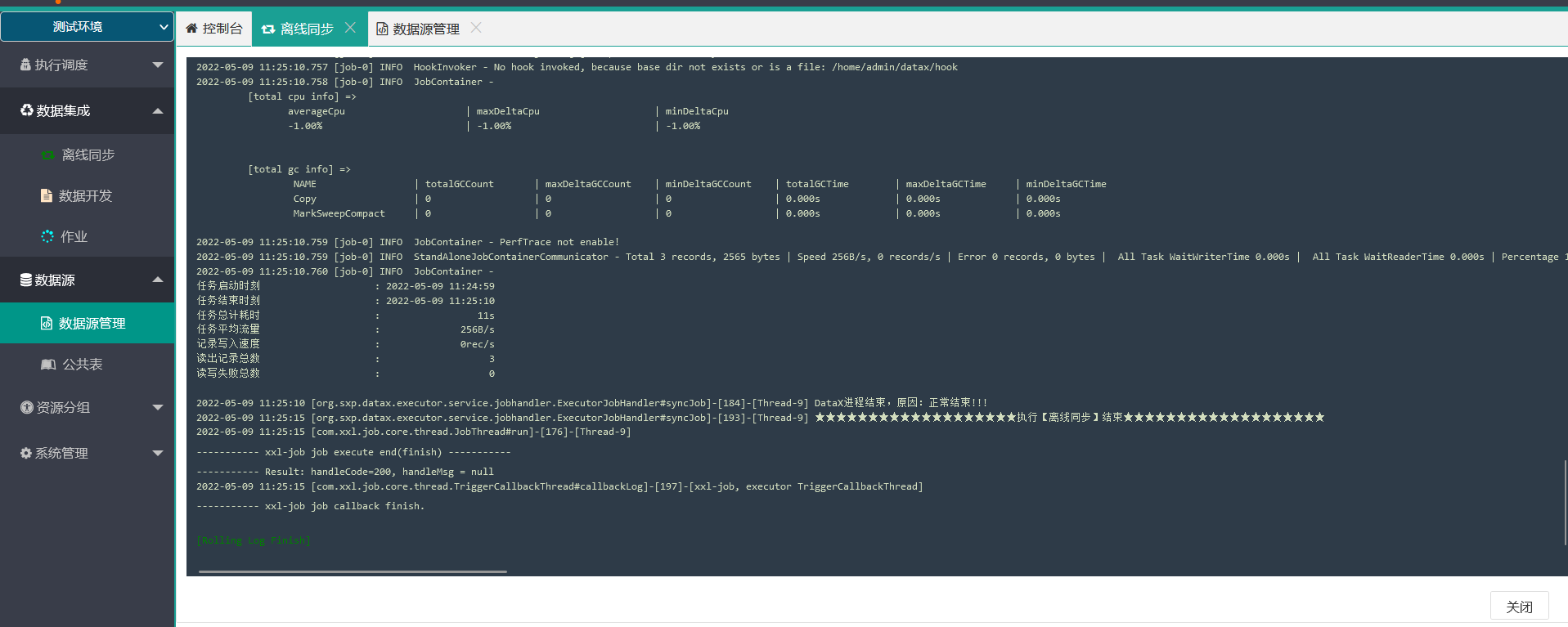
7.调度日志查看(进行中的任务可以暂停刷新-终止任务等非常方便)
8.Docker容器化部署,rancher平台托管,node节点可以分布式扩展,部署架构参考XXLJOB,节点之间是独立的,统一由admin发送调度任务

以下对功能需求介绍如下:
1.执行调度(这个不多介绍了,熟悉XXLJob的同学一看就知道,还是熟悉的味道,熟悉的配方,完美复刻(好吧有改造的成分))
2.数据集成(重点,用过阿里云DataWorks的同学能够感受到熟悉的感觉,没错参考核心的几个DataWorks操作)
2.1 离线同步 - 基础功能
主要负责异构数据源的数据同步,目前UI上只支持关系型数据库,设计上支持扩展,底层逻辑是,设计出DataX所需要的JSON,给到调度,调度发送给Node节点,Node节点丢给DataX去执行就好了,执行日志全部通过XxlJob的方式输出,UI上面为了体验友好做了改造,启动执行立刻弹出日志窗口,增加暂停/继续刷新和弹出窗终止任务等实用功能,体验上单点聚合不用切换到别的地方去。
2.2 数据开发 - 基础功能
这里重点借助公共库表的设计,参考DataWorks思路,通常离线同步只是两个跨数据源的库表同步,如果需要一个中间过渡的公共库做临时表的数据处理,那么数据开发就是做这个事情的,可以做一些update/delete等数据清洗,集成了一个SQL编辑器,后台提供接口支持,开发好的sql脚本给到调度,调度发送给Node,Node节点直接执行发送给公共数据库,因为是更新SQL,没有借助DataX,直接发送到源库执行,也可以全程借助DataX,不多说,公共库只支持Mysql。
2.3 作业 - 高级功能
思路就是离线同步和数据开发看作是一个个单一任务,那么一个作业就是为了把一个个单一的串起来,因为有时候一个完整的数据同步可以涉及多个同步开发步骤,作业属于一个高级功能项.
3.数据源
3.1 数据源管理
这个好理解,就是全局数据源,有的没的加上去就能同步了。目前已支持Mysql/Oracle/Postgresql/sqlserver/达梦/hive/oceanbase/mongodb/hbase
3.2 公共表
就是公共库表给数据开发的,只支持Mysql,需要从数据源里边选择一个绑定为公共库,全局只能有一个。
4.资源分组
5.系统管理
通用的数据权限管理功能,已支持全局的数据权限过滤。
开源位置更新在:https://gitee.com/shenxingping/dataxp

