硬件结构 硬盘--
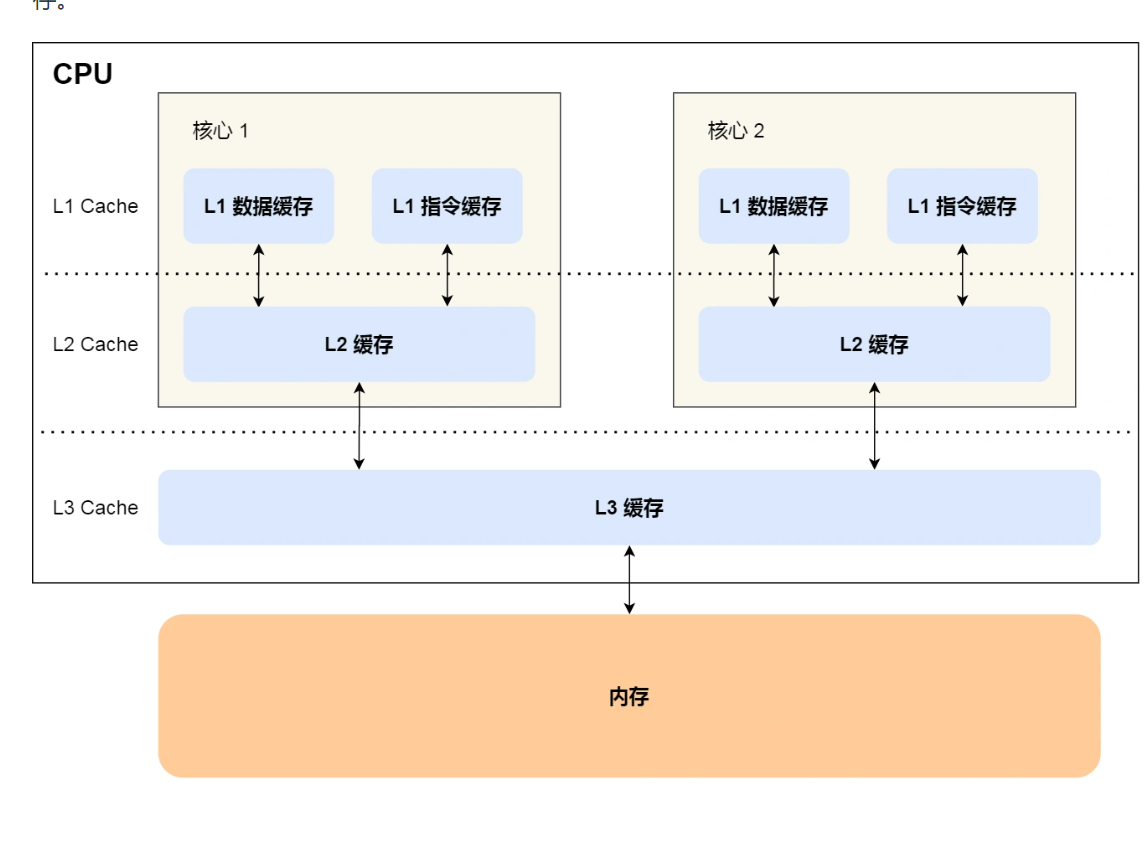
CPU 的高速缓存,通常可以分为 L1、L2、L3 这样的三层高速缓存,也称为一级缓存、二级缓存、三级缓存。
在 Linux 系统,我们可以通过这条命令,查看 CPU 里的 L1 Cache 「数据」缓存的容量大小:
$ cat /sys/devices/system/cpu/cpu0/cache/index0/size
32K
内存用的芯片和 CPU Cache 有所不同,它使用的是一种叫作 DRAM (Dynamic Random Access Memory,动态随机存取存储器) 的芯片。
相比 SRAM,DRAM 的密度更高,功耗更低,有更大的容量,而且造价比 SRAM 芯片便宜很多。
如何写出让 CPU 跑得更快的代码?
CPU 内部嵌入了 CPU Cache(高速缓存),它的存储容量很小,但是离 CPU 核心很近,所以缓存的读写速度是极快的,那么如果 CPU 运算时,直接从 CPU Cache 读取数据,而不是从内存的话,运算速度就会很快。
但是,大多数人不知道 CPU Cache 的运行机制,以至于不知道如何才能够写出能够配合 CPU Cache 工作机制的代码,一旦你掌握了它,你写代码的时候,就有新的优化思路了。
CPU Cache 是由很多个 Cache Line 组成的。
Cache Line 是由各种标志(Tag)+ 数据块(Data Block)
如何写出让 CPU 跑得更快的代码?
访问的数据在 CPU Cache 中的话,意味着缓存命中,缓存命中率越高的话,代码的性能就会越好,CPU 也就跑的越快。
经过测试,形式一 array[i][j] 执行时间比形式二 array[j][i] 快好几倍。

之所以有这么大的差距,是因为二维数组 array 所占用的内存是连续的,比如长度 N 的值是 2 的话,那么内存中的数组元素的布局顺序是这样的:

那访问 array[0][0] 元素时,CPU 具体会一次从内存中加载多少元素到 CPU Cache 呢?这个问题,在前面我们也提到过,这跟 CPU Cache Line 有关,它表示 CPU Cache 一次性能加载数据的大小,可以在 Linux 里通过 coherency_line_size 配置查看 它的大小,通常是 64 个字节。

分支预测器 先排序后遍历速度快
2.4 cpu缓存一致性
保持内存与 Cache 一致性最简单的方式是,把数据同时写入内存和 Cache 中,这种方法称为写直达(Write Through)。
在写回机制中,当发生写操作时,新的数据仅仅被写入 Cache Block 里,只有当修改过的 Cache Block「被替换」时才需要写到内存中,减少了数据写回内存的频率,这样便可以提高系统的性能。
修改过的cache才需要写回内存。
这时如果 A 号核心执行了 i++ 语句的时候,为了考虑性能,使用了我们前面所说的写回策略,先把值为 1 的执行结果写入到 L1/L2 Cache 中,然后把 L1/L2 Cache 中对应的 Block 标记为脏的,这个时候数据其实没有被同步到内存中的,因为写回策略,只有在 A 号核心中的这个 Cache Block 要被替换的时候,数据才会写入到内存里。
如果这时旁边的 B 号核心尝试从内存读取 i 变量的值,则读到的将会是错误的值,因为刚才 A 号核心更新 i 值还没写入到内存中,内存中的值还依然是 0。
修复!
第一点,某个 CPU 核心里的 Cache 数据更新时,必须要传播到其他核心的 Cache,这个称为写传播(Write Propagation); 传播到其他 cache
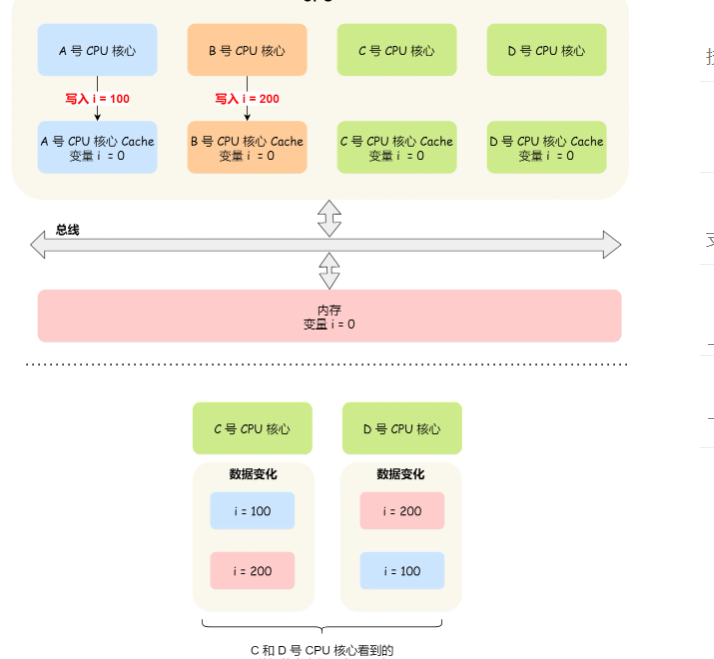
那么问题就来了,C 号核心先收到了 A 号核心更新数据的事件,再收到 B 号核心更新数据的事件,因此 C 号核心看到的变量 i 是先变成 100,后变成 200。
而如果 D 号核心收到的事件是反过来的,则 D 号核心看到的是变量 i 先变成 200,再变成 100,虽然是做到了写传播,但是各个 Cache 里面的数据还是不一致的。
所以,我们要保证 C 号核心和 D 号核心都能看到相同顺序的数据变化,比如变量 i 都是先变成 100,再变成 200,这样的过程就是事务的串行化。
为什么 0.1 + 0.2 不等于 0.3 ?
由于计算机的资源是有限的,所以是没办法用二进制精确的表示 0.1,只能用「近似值」来表示,就是在有限的精度情况下,最大化接近 0.1 的二进制数,于是就会造成精度缺失的情况。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号