mysqldump,NAVICAT转储,select * outfile在千级数据,万级,百万级数据下的表现。
千级数据
- mysqldump导出sql文件
导出是出了拒绝访问的错误;为对应目录(.sql文件要保存的目录)的对应用户添加(正在使用的用户)添加写入权限即可。
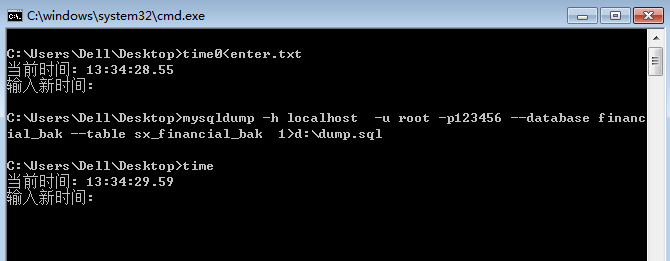
mysqldump -h localhost -u root -p123456 --database financial_bak --table sx_financial_bak >d:\dump.sql
注:-p 与密码间不能有空格,有空格时’123456’会被作为数据库名解析,并且要求输入密码。
可知--database可以省略,--table也可以省略
.sql文件会给出所导出的数据来源,包括数据连接,服务器地址,端口号,导出时间等信息。文件主体有:创建数据库判断语句-删除表-创建表(-锁表-禁用索引)-插入数据(-启用索引-解锁表)。

用时大约为1s!!其中包括两次时间函数的调用。导出的dump.sql为23k,一共包含1909条insert语句。
2.使用navicat
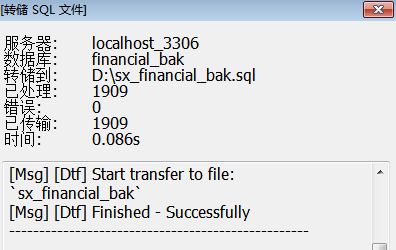
同样的表使用navicat的sql导出功能用时约为0.1s
3.使用select* outfile的方式

其中使用默认参数对所得数据划分的方式所花时间为0.0016s,使用自定义划分方式用时0.0257s,远远小于使用mysqldump,以及navicat导出sql的方式。
万级数据量
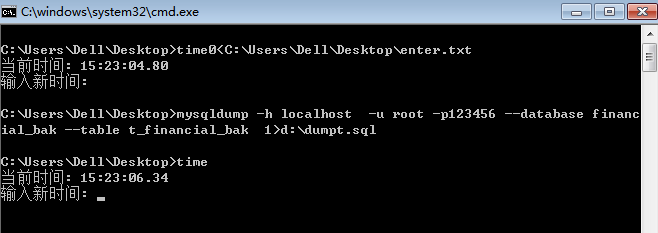
对于轻量的表来说结果是outfile的方式用时最少。对于另一个较大的表呢?t_Financial_bak有35007条数据且每条数据有较多数据项
- Mysqldump
用时为1.5s。10倍的数据量仅仅多花费了50%的时间,说明在上面的结果1s中时间函数占比较大。
- navicat转储sql的方式
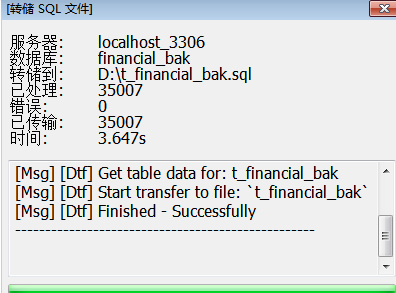
用时大幅度上涨,由0.1变为了3.6s。转储文件由0.1m增加为27m用时的上涨比数据量上涨更快。
3.Select * outfile的方式
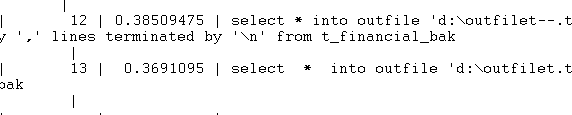
可以看到使用默认文件分割方式的outfile语句的时间为0.36,比使用自定义分割方式的0.38少了0.02s可以初步推断使用自定义分割方式要比默认方式多花0.02秒。但使用select
* outfile的方式依然比使用其他两种方式导出所花时间少一个数量级。
百万级数据
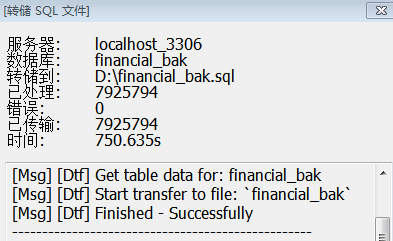
对于更大的表有7925794条数据financial的测试结果
Mysqldump
用时187.08s
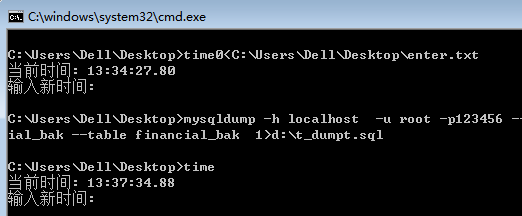
Navicat转储sql
用时750.635s
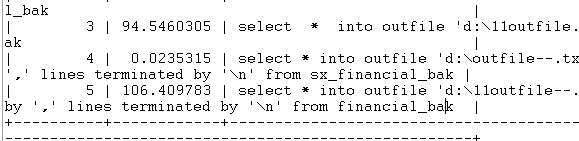
Outfile
默认分隔符花费时间94.54s
自定义分隔符花费106.41s
对于导出文件差异的分析总结。
|
导出方式 |
文件类型 |
具体内容 |
时间花费以及评议 |
|
Mysqldump |
.sql
|
创建数据库判断语句-删除表-创建表-插入数据。插入方式为一次性插入所有数据,每一行是一个元组。 |
需要编写语句,但是随着数据量增加对navicat |
|
Navicat转储sql |
整体内容与mysqldump一致,插入实现方式不同,对每一行数据都执行一个insert语句。 |
最初花费时间很少,操作容易,不需要编写语句花费额外时间。但随着数据量的增长很快,适合导出数据量较小的主要功能为对照的表。 |
|
|
outfile |
文本文件 |
导出数据为数据元组的简单分割。 |
花费时间最少,但是导出服务器数据时不方便。 |
对于三种方式的比较:
Mysqldump,navicat转储都是将表导出为sql:
优点
- 导出了表结构,恢复起来更加方便。
- 导出数据具有很强可读性,可以很方便的对个别数据进行查找,修改。
- Navicat转储只需要鼠标点击即可完成具体到表导出任务,操作非常容易(但花时间也最多!)。
- Mysqldump提供很多可选参数可以根据需求使用不同的参数,灵活多变,可以远程备份文件到本地。
缺点
- .sql文件高度结构化,不利于对数据的大规模修改处理。
- 导出大量数据时,时间比较常,导入时时间更长!
Outfile方式:
优点
- 导出速度相对快。
- 导出数据结构化程度低,可以将文件导入到不同的数据库表中。
- 导出数据为文本格式,必要时方便对数据进行格式化等修改。
- 导出时要求没有同名文件,更加安全。
缺点
- 导出时要求文件不能同名,但不提供是否覆盖的选项。(dump方式由shell提供)
- 导出数据不包括表结构,导入时要求已经有一个表可以存放数据。
三种方式导出文件的导入
Mysqldump导出文件导入source
导入35007条数据花费的时间5s(不知为何source命令后show profiles显示的是sql中每一个sql的花费时间,占时不知道使用 profiles查看source总用时的方法,以下为timestampdiff()的结果,由于mysql版本问题只能精确到秒)
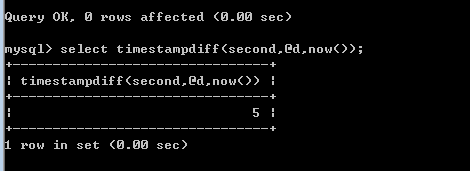
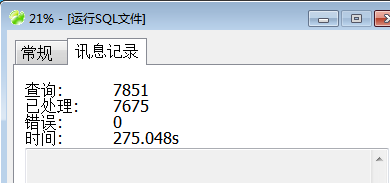
Navicat转储sql文件导入
实在没有耐心等下去了,一共导入; 7675条数据,花费时间275.05s,可见这种方式导出百万级的表时就几乎已经是不可用的了。
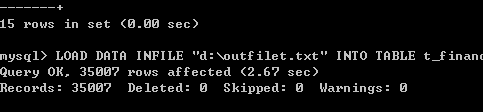
Outfile导出文件的导入infile
使用默认分割方式导出的文件,导入35007行用时2.67s
使用自定义的数据分割方式,导入35007行用时3.38s

总结:
Mysqldump 在导出导入都有不错的表现,且随着数据量的增加,导出导入每条数据所用时间在减少(与其导出.sql文件的结构有关,说明insert语句一次插入多条数据,比执行多天语句每条插入一条数据的效率高的多),而且提供较多的option,可以帮助用户实现各种需求,在服务器数据备份上由于-h参数也outfile-infile的方式更加方便。
Navicat提供的导出导入方式操作方便,但是随着数据量的很快变得几乎不可用。到导出的.sql文件结构化程度最高,易于做文本处理,对于及几百行,千行的对照表来说不失为一种简单易行的数据导出方式。
Outfile—infile 导出的文件是一个数据元组安一定规则排列的文件,导出的数据文件比同等数据量的.sql文件更小。导出导入花费的时间也更短适合用来保存备份。但是要求恢复数据时表已经存在。
附:不同环境下操作时间的测量(占时没有找到更好的方法)
windos命令行下:
使用time命令打印时间的方式来实现(中间有调用时间函数的时间,以及io时间,操作用时较少时及其不准):
编写.bat批处理文件
time<C:\Users\Dell\Desktop\enter.txt
mysql -h localhost -u root -p123456 --database financial_bak
source d:\dump.sql
time
pause
注意pause让命令行界面滞留。enter.txt是一个自建的只包含一个换行的文件(time会接受一个额外的参数修改时间,需要换行跳过)。
mysql命令行
使用profile
set profiling=1;
source d:\dump.sql;
show profiles;
mysql命令行的timestampdiff()计算时间差的方式
5.6以下版本仅支持到秒级,精度较差
set @d=now();
Source D:\\t_dump.sql;
select timestampdiff(second,@d,now());
注意由于时间算时间差要求三条命令一气呵成。最后一条命令下有一个空行!
timestampdiff OPTION
- FRAC_SECOND。表示间隔是毫秒
- SECOND。秒
- MINUTE。分钟
- HOUR。小时
- DAY。天
- WEEK。星期
- MONTH。月
- QUARTER。季度
- YEAR。年

 浙公网安备 33010602011771号
浙公网安备 33010602011771号