在R中子集化数据框的5种方法
由于微信不允许外部链接,你需要点击文章尾部左下角的 "阅读原文",才能访问文中链接。
通常,我们在使用大型数据集时,只会对其中的一小部分感兴趣,用以进行特定分析。 那么,我们应该如何对所有无关的变量和观察值进行排序并仅提取我们需要的那部分数据? 其实,在 R 中有几种被称为 “subsetting(子集化)” 的方法可以满足以上的需求,今天我们来聊一下。
在 R 中对数据框(data frame)进行子集化的最基本方法是使用方括号:
example[x, y]example 是我们想要从中提取子集的数据框;’x’ 是我们想要提取的子集的行;’y’ 是我们想要提取的子集的列。 让我们从网上提取一些数据,看看它是如何在真实的数据集上实现的。
### import education expenditure data set and assign column names
education <- read.csv("https://vincentarelbundock.github.io/Rdatasets/csv/robustbase/education.csv", stringsAsFactors = FALSE)
colnames(education) <- c("X","State","Region","Urban.Population","Per.Capita.Income","Minor.Population","Education.Expenditures")
head(education, 25)这是我导入数据并适当命名其列后数据集的第一部分(前 25 行):
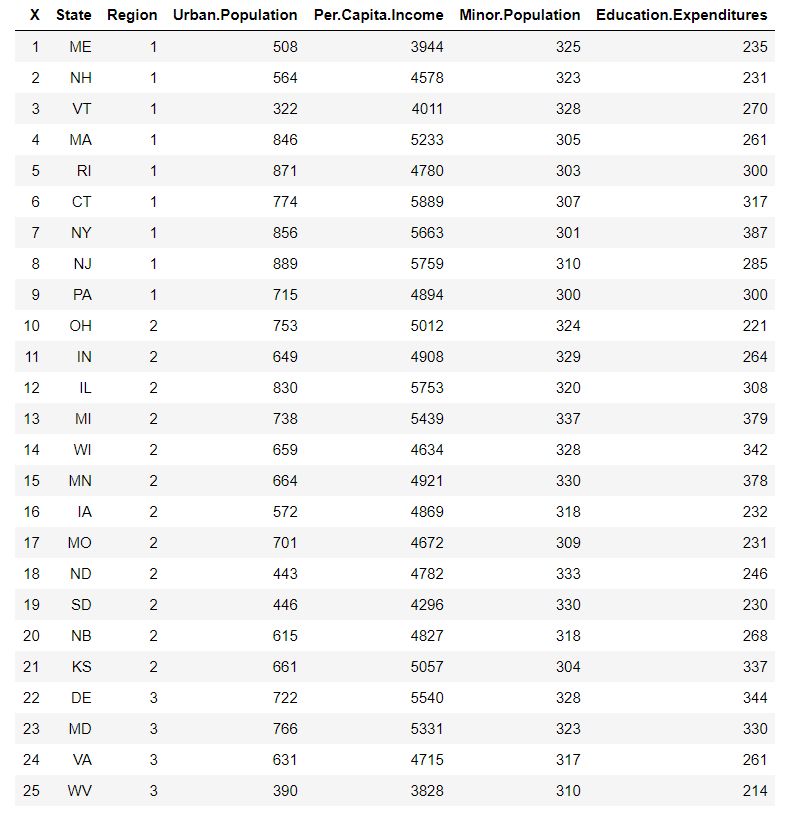
现在,让我们假设回顾一下美国中西部的学校分布,并且我们需要计算 Region 2 地区中每个州每个孩子花费了多少钱。 我们需要三个变量:State,Minor.Population 和 Education.Expenditures。 但是,我们只需要对应于 Region 2 的行的观察结果。这是在 R 中检索该数据的基本方法:
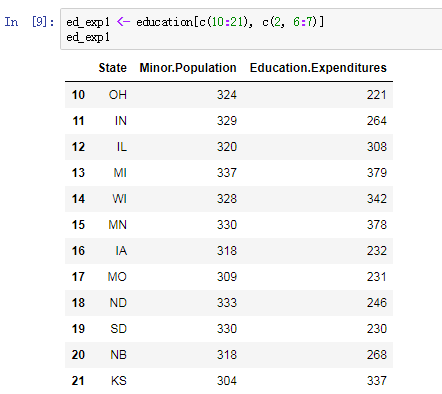
ed_exp1 <- education[c(10:21), c(2, 6:7)]为了创建新的数据框 ‘ed_exp1’,我们通过提取第 10-21 行和第 2, 6 和 7 列来对 “education(教育)” 数据框进行子集化。非常简单,对吧?
使用括号对数据框进行子集化的另一种方法是省略行和列引用(即反取)。 看看这段代码:
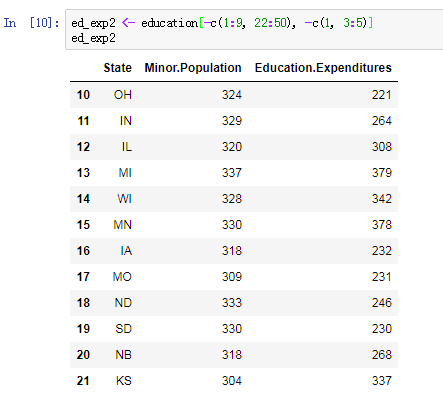
ed_exp2 <- education[-c(1:9, 22:50),-c(1, 3:5)]在这行代码里,我们不是对我们想要返回的行和列进行子集化,而是对我们不希望返回的行和列进行子集化,然后使用 “-” 符号省略它们。 如果我们现在调用 ed_exp1 和 ed_exp2,我们可以看到两个数据框都返回原始 education 数据框相同的子集。
上面这些在 R 中对小数据框进行子集的基本方法在大型数据集中会变得单调缺乏灵活性,因为我们必须知道所要提取的子集的确切列和行索引号。如果一个数据只有 7 列 50 行,找到所需的列和行会非常简单,但是如果这个数据有 70 列和 5000 行呢?在这种情况下,如何找到所需的列和行?下面是另一种在 R 中提取数据框子集的方法。
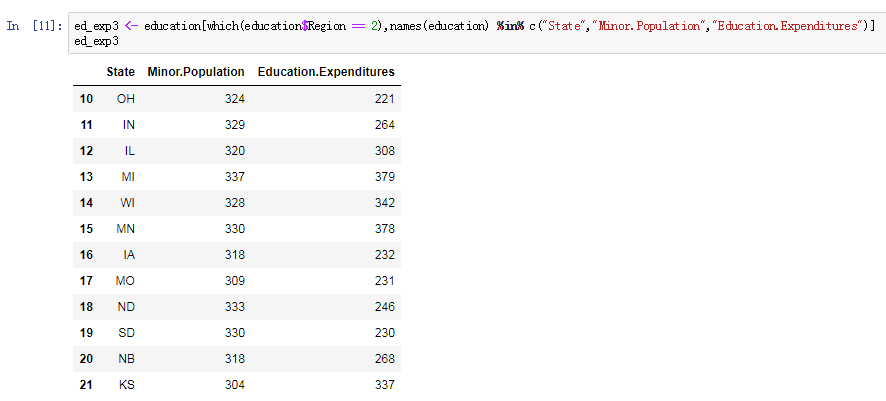
ed_exp3 <- education[which(education$Region == 2), names(education) %in% c("State", "Minor.Population", "Education.Expenditures")]我们来看看这段命令发生了什么。
首先,我们使用了跟前两个例子一样的方括号技术来提取 education 数据框的子集。但是,这一次,我们使用了 which() 函数提取我们需要的行。 此函数返回了 education 数据框中 Region 列值为 2 的索引。这为我们提供了所需的行。
然后,我们通过在 education 数据框的名称上使用 %in% 运算符来检索子集的列。
现在,有些人看着这行代码觉得它太复杂了。 必须有一种更简单的方法来做到这一点。 好吧,你会是对的。 R 中还有另一个基本功能,它允许我们在不知道行和列引用的情况下对数据框进行子集化。 使用名字来提取? 你猜对了:subset()。
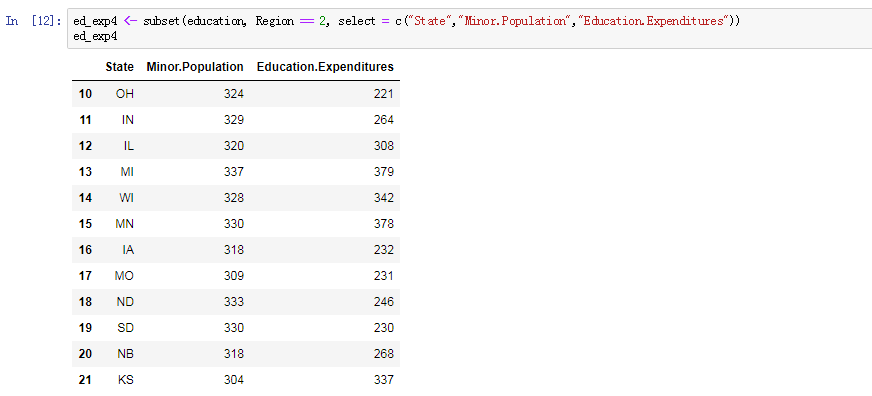
ed_exp4 <- subset(education, Region == 2, select = c("State","Minor.Population","Education.Expenditures"))subset() 函数有 3 个参数:我们想要子集化的数据框,我们希望它进行子集化处理对应的行,以及我们想要返回的列。 在我们的例子中,我们采用 “Region” 等于 2 的 education 子集,然后选择 “State”, ”Minor.Population” 和 “Education.Expenditure” 列。
当我们使用上述两种方法中的任何一种对 education 数据框进行子集化时,我们得到与前两种方法相同的结果:
除此以外,还有一种我们操作数据最有用的方法。让我们先来看看代码,然后我们将讨论它。
install.packages("dplyr")
library(dplyr)
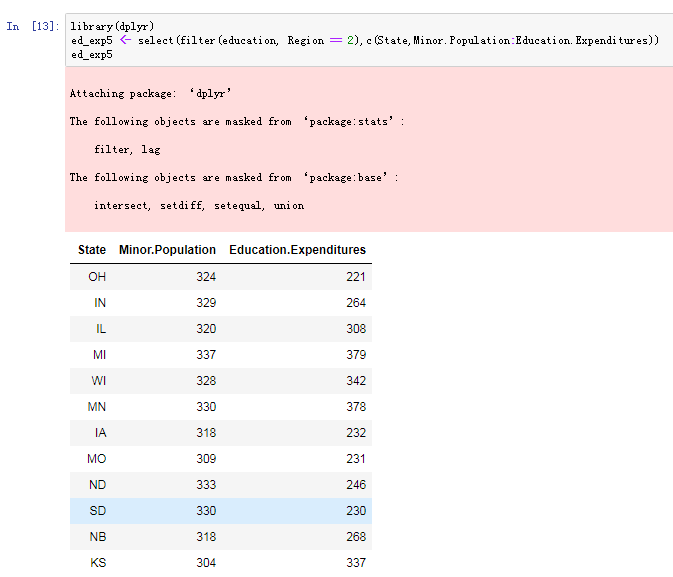
ed_exp5 <- select(filter(education, Region == 2),c(State,Minor.Population:Education.Expenditures))最后的这一种方法不是 R 基础环境的一部分。要使用它,我们必须安装并下载 dplyr 软件包。如果你要使用 R 中的数据,这肯定是一个你想要的包。 它是 R 环境中下载次数最多的软件包之一,当你开始使用它时,你很快就会明白为什么。
因此,一旦我们下载了 dplyr,我们就可以使用此包中的两个不同函数创建一个新的数据框:
filter:第一个参数是数据框; 第二个参数是我们希望它被子集化的条件。 结果是整个数据框只有我们想要的行。
select:第一个参数是数据框; 第二个参数是我们想要从中选择的列的名称。我们不必使用 names() 函数,甚至不必使用引号。 我们只是将列名列为对象就可以。
在这个例子中,我们将筛选函数(filter)包装在选择函数(select)中以返回我们的数据框。 换句话说,我们首先将 Region 为 2 的行作为子集。 然后,我们从那些行中获取了我们想要的列。 结果为我们提供了一个数据框架,其中包含我们感兴趣的 12 个州所需的数据:
最后,回顾一下,这里有 5 种方法可以在 R 中对数据框进行子集化:
使用括号,通过提取我们想要的行和列来进行子集化;
使用括号,通过省略我们不想要的行和列来进行子集化;
使用括号,使用
which()函数和%in%使用
subset()使用
dplyr包中的filter()select()函数实现数据框子集化。

本文分享自微信公众号 - 生信科技爱好者(bioitee)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。

{kind=link}