聚类分析和主成分分析
聚类分析和主成分分析
来自黄思思(浙江大学八年制医学生,生信技能树全国巡讲杭州站优秀学员)投稿
聚类分析
01
系统聚类
示例数据一:现有16种饮料的热量、咖啡因含量、钠含量和价格的数据,根据这4个变量对16饮料进行聚类。
这里展示的是离差平方和法(WARD)进行系统聚类。它基于方差分析的思想,同类样品之间的离差平方和应当较小,不同类之间的离差平方和应当较大。

> head(mydata)
热量x1 咖啡因含量x2 钠含量x3 价格x4
1 207.2 3.3 15.5 2.8
2 36.8 5.9 12.9 3.3
3 72.2 7.3 8.2 2.4
4 36.7 0.4 10.5 4.0
5 121.7 4.1 9.2 3.5
6 89.1 4.0 10.2 3.3
代码一(比较丑):
library(cluster)
# Compute with agnes (make sure you have the package cluster)
hc1 <- agnes(mydata, method = "ward")
pltree(hc1, cex = 0.6, hang = -1, main = "Dendrogram of agnes")
rect.hclust(hc1, k = 3)
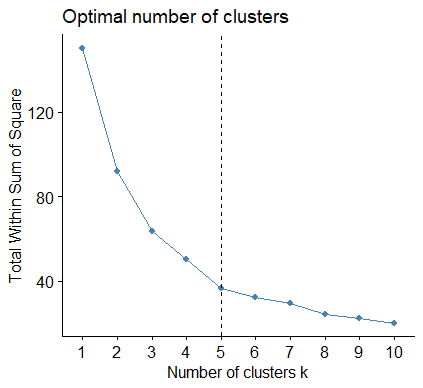
代码二:
#用欧式距离代表样本之间两两相似性
result <- dist(mydata, method = "euclidean")
result_hc <- hclust(d = result, method = "ward.D2")
fviz_dend(result_hc, k = 3,
cex = 0.5,
k_colors = c("#2E9FDF", "#E7B800", "#FC4E07"),
color_labels_by_k = TRUE,
rect = TRUE
)
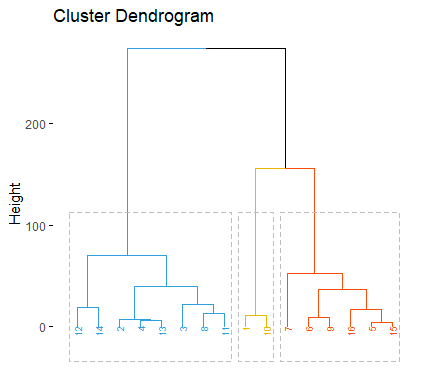
与之前代码的结果是一致的,但是图比较好看嘿嘿嘿
经 WARD 系统聚类法,我们得到了聚类结果的谱系图,从中我们可以看到饮料分为三类的结果是 {12,14,2,4,13,3,8,11},{1,10},{7,6,9,16,5,15}.
02
动态聚类

library(factoextra)
b<-scale(mydata)
set.seed(123)
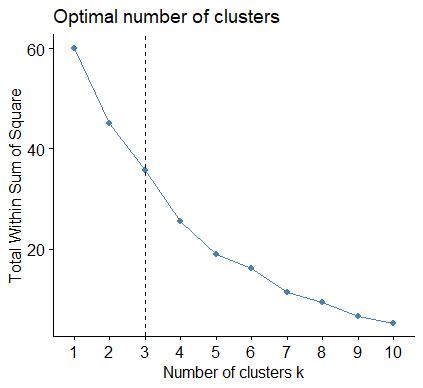
fviz_nbclust(b,kmeans,method="wss")+geom_vline(xintercept=3,linetype=2)
使用组内平方误差和确定最佳聚类个数,预判分为三类或四类,这里分为三类效果较好(可看后面的聚类图)。
res<-kmeans(b,3)
res1<-cbind(mydata,res$cluster)
fviz_cluster(res,data=mydata[,1:ncol(mydata)-1])
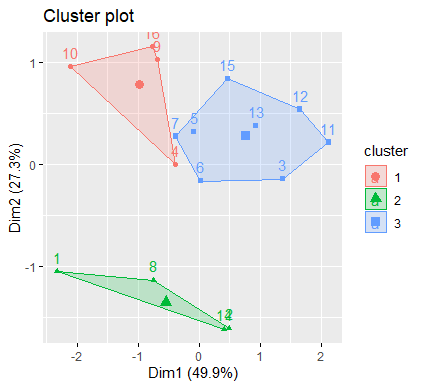
使用 K-means 动态聚类方法与 Ward 系统聚类法的聚类结果并不相同,K-means 动态聚类方法将饮料分为三类的结果是{1,8,12,14},{4,9,10,16},{3,5,6,7,11,12,13,15}
示例数据二:中国31个城市2011年的空气质量数据,根据这个数据对31个城市进行聚类分析。
> head(mydata)
可吸入颗粒物.PM10. 二氧化硫.SO2. 二氧化氮.NO2.
北京 0.11329589 0.02810959 0.05582740
天津 0.09287671 0.04203562 0.03830685
石家庄 0.09887397 0.05225205 0.04118356
太原 0.08433151 0.06391233 0.02293151
呼和浩特 0.07576164 0.05413973 0.03944110
沈阳 0.09648219 0.05859452 0.03272329
空气质量达到及好于二级的天数.天.
北京 286
天津 320
石家庄 320
太原 308
呼和浩特 347
沈阳 332
空气质量达到二级以上天数占全年比重...
北京 78.35616
天津 87.67123
石家庄 87.67123
太原 84.38356
呼和浩特 95.06849
沈阳 90.95890
这次先进行 K-means 动态聚类法。
首先我根据动态聚类法判定类别数,时出现拐点,分成五类合适。
绘制动态聚类结果
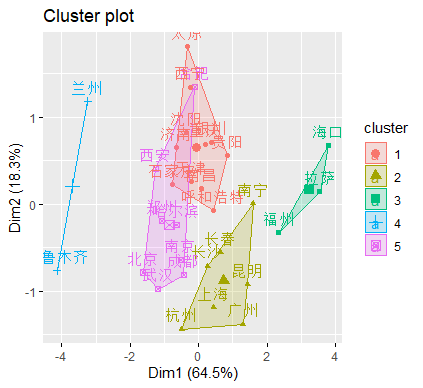
根据可吸入颗粒物(PM10)、二氧化硫(SO2)、二氧化氮(NO2)、空气质量达到及好于二级的天数(天)、空气质量达到二级以上天数占全年比重(%)这几个变量,用 K-means 动态聚类法将城市分成五类,结果如下:
> rownames(res1)[res1$`res$cluster`=="1"]
[1] "天津" "石家庄" "太原" "呼和浩特" "沈阳" "南昌"
[7] "济南" "重庆" "贵阳" "西宁" "银川"
> rownames(res1)[res1$`res$cluster`=="2"]
[1] "长春" "上海" "杭州" "长沙" "广州" "南宁" "昆明"
> rownames(res1)[res1$`res$cluster`=="3"]
[1] "福州" "海口" "拉萨"
> rownames(res1)[res1$`res$cluster`=="4"]
[1] "兰州" "乌鲁木齐"
> rownames(res1)[res1$`res$cluster`=="5"]
[1] "北京" "哈尔滨" "南京" "合肥" "郑州" "武汉" "成都"
[8] "西安"
WARD 系统聚类法
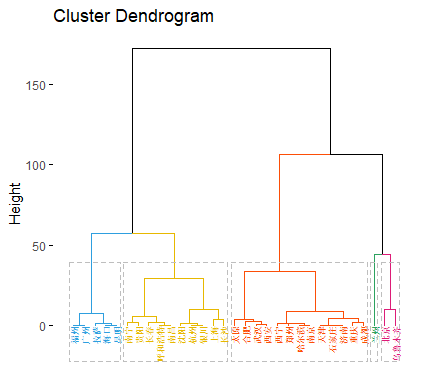
使用 WARD 系统聚类法的聚类结果为
第一类:{"福州" "广州" "拉萨" "海口" "昆明"}
第二类:{"南宁" "贵阳" "长春" "呼和浩特" "南昌" "沈阳" "杭州" "上海" "长沙"}
第三类:{"太原" "合肥" "武汉" "西安" "西宁" "郑州" "哈尔滨" "南京" "天津" "石家庄" "济南" "重庆" "成都"}
第四类:{"兰州"}
第五类:{"北京" "乌鲁木齐"}
下面我们通过热图的方法发现类并确定类的个数。
用 result 表示两两样本间的欧式距离矩阵,距离越近相关性越高。
result <- dist(mydata, method = "euclidean")
03
通过热图发现类
heatmap(as.matrix(result), labRow = F, labCol = F)
在图中可以看出颜色越深,距离越近。通过观察感觉分成五类或六类 OK,分成两类也似有道理但总觉得两类太少了点。
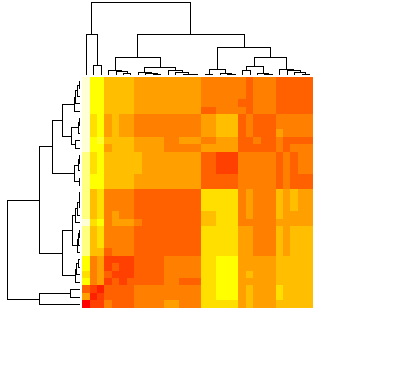
确定类的个数为五类
result_hc <- hclust(d = result, method = "ward.D2")
re <- cutree(result_hc, k = 5)
采用多维标定,用第一和第二主成分,表示原本分类。
mds = cmdscale(result, k = 2, eig = T)
X <- mds$points[, 1]
Y <- mds$points[, 2]
p = ggplot(data.frame(X, Y ), aes(X, Y ))
library(ggplot2)
p + geom_point(size = 3, alpha = 0.8, aes(colour =factor(re)))
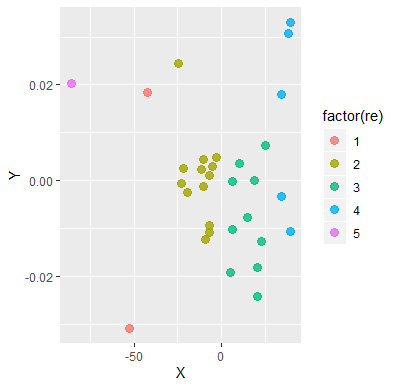
04
系统聚类法和动态聚类法的优缺点
系统聚类法:
优点:可解释性好,可以考虑先取 K 比较大的 K-means 后,合并阶段用系统聚类也许能产生更高质量的聚类。
缺点:时间复杂度高。
动态聚类法:
优点:适用于大样本的 Q 型聚类分析。大型数据一般较集中,异常值影响较弱。且算法简单高效,时间复杂度低。
缺点:依赖初始个点的选取或说依赖于初始划分,容易落入局部最优。对噪声和离群值敏感。
动态聚类法的改进方法:为了检验聚类的稳定性,可用一个新的初始分类重新检验整个聚类算法。如最终分类与原来一样,则不必再进行计算;否则,须另行考虑聚类算法。
主成分分析
由于变量个数太多,且彼此有相关性,从而数据信息重叠。
当变量较多,在高维空间研究样本分布规律较复杂
于是我们希望,用较少的综合变量代替原来较多变量,又能尽可能多地反映原来数据的信息,并且彼此之间互不相关。
叮!这就孕育了主成分分析!
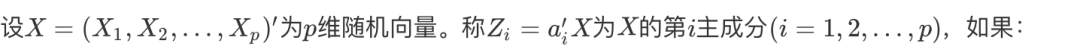
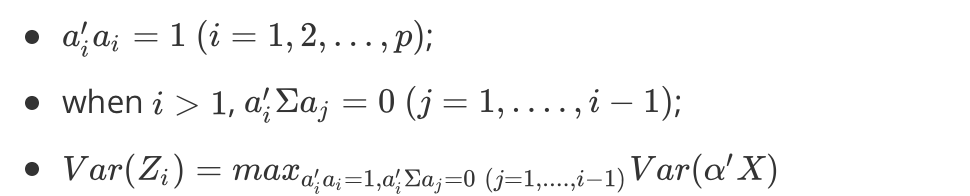
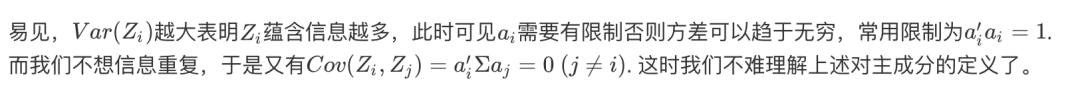

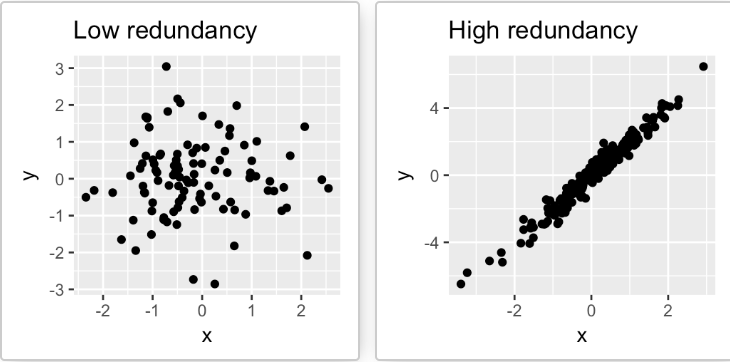
下面这张图就形象地展现了如何利用主成分分析将二维降至一维。
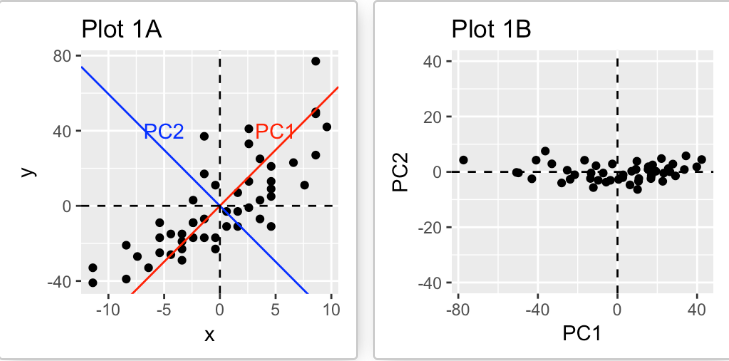
注意,当数据集中的变量高度相关时,PCA 方法特别有用。相关性表明数据中存在冗余。由于这种冗余,PCA 可用于将原始变量减少为较少数量的新变量(主成分),从而解释了原始变量中的大多数方差。
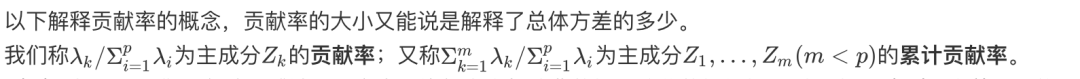
示例数据三 :我国2010年各地区城镇居民家庭平均每人全年消费数据,这些数据指标分别从食品(x1),衣着,居住,医疗,交通,通信,教育,家政和耐用消费品来描述消费。试对该数据进行主成分分析。
> head(data)
食品 衣着 居住 医疗 交通通讯 教育 家庭服务 耐用消费品
北京 5561.54 1571.74 1286.32 1563.10 2293.23 809.25 84.71 548.55
天津 5005.09 1153.66 1528.28 1220.92 1567.87 715.24 45.50 467.75
河北 3155.40 1137.22 1097.41 808.88 1062.31 386.60 28.84 305.70
山西 2974.76 1137.71 1250.87 769.79 931.33 570.79 35.38 259.05
内蒙古 3553.48 1616.56 1028.19 869.71 1191.70 568.35 30.49 307.92
辽宁 4378.14 1187.41 1270.95 913.13 1295.70 670.13 30.40 235.46
pr<-princomp(data,cor=TRUE)
screeplot(pr,type="lines")
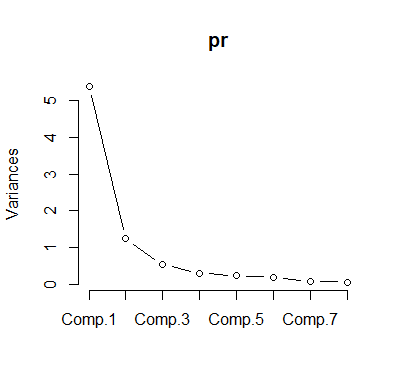
根据碎石图转折点在 2 个主成分或 3 个主成分
主成分分析结果:
> summary(pr,loadings=TRUE)
Importance of components:
Comp.1 Comp.2 Comp.3 Comp.4 Comp.5
Standard deviation 2.3213318 1.1100881 0.72943408 0.5464987 0.47643779
Proportion of Variance 0.6735727 0.1540369 0.06650926 0.0373326 0.02837412
Cumulative Proportion 0.6735727 0.8276096 0.89411886 0.9314515 0.95982558
Comp.6 Comp.7 Comp.8
Standard deviation 0.4351019 0.28334611 0.227588880
Proportion of Variance 0.0236642 0.01003563 0.006474587
Cumulative Proportion 0.9834898 0.99352541 1.000000000
Loadings:
Comp.1 Comp.2 Comp.3 Comp.4 Comp.5 Comp.6 Comp.7 Comp.8
食品 0.358 0.396 0.158 0.288 0.503 0.282 0.522
衣着 0.257 -0.536 0.703 -0.130 -0.336 0.135
居住 0.374 -0.412 -0.570 -0.112 -0.512 0.224 0.198
医疗 0.275 -0.599 -0.336 0.600 0.148 -0.248
交通通讯 0.393 0.292 0.137 0.120 0.166 -0.233 0.114 -0.795
教育 0.386 0.195 -0.466 -0.178 0.729 0.168
家庭服务 0.396 0.264 -0.211 -0.837 0.152
耐用消费品 0.361 -0.205 -0.373 0.599 -0.503 0.114 0.251
可以发现当选用前三个主成分时,已经解释了接近90%的方差,所以我认为选取三个主成分进行降维是合理的。
01
FactorMineR
下面我们用 FactoMineR 包来对同样的数据作 PCA,它的展示效果更好。
计算变量的主成分
res.pca <- PCA(data, graph = FALSE)
eig.val <- get_eigenvalue(res.pca)
观察特征值,它代表了每个主成分的方差
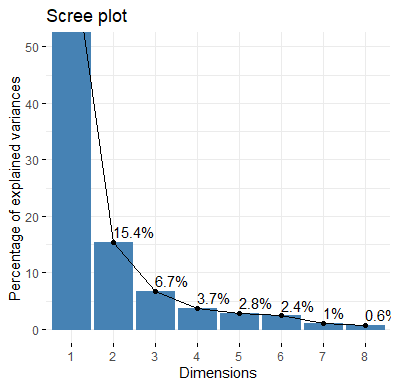
> eig.val
eigenvalue variance.percent cumulative.variance.percent
Dim.1 5.38858121 67.3572651 67.35727
Dim.2 1.23229559 15.4036948 82.76096
Dim.3 0.53207408 6.6509260 89.41189
Dim.4 0.29866081 3.7332601 93.14515
Dim.5 0.22699297 2.8374121 95.98256
Dim.6 0.18931363 2.3664203 98.34898
Dim.7 0.08028502 1.0035627 99.35254
Dim.8 0.05179670 0.6474587 100.00000
观察碎石图
fviz_eig(res.pca, addlabels = TRUE, ylim = c(0, 50))
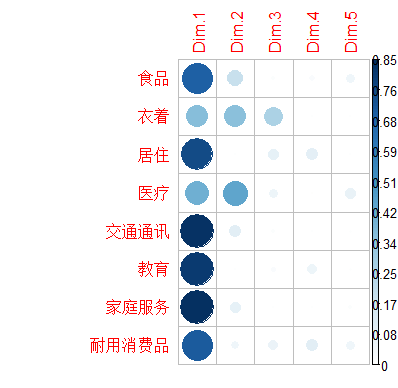
从PCA 输出中提取变量结果的一种简单方法是使用函数 get_pca_var()[factoextra package]。该函数提供了一个矩阵列表,其中包含活动变量的所有结果(坐标,变量与轴之间的相关性,余弦平方和贡献)
> var <- get_pca_var(res.pca)
> var
Principal Component Analysis Results for variables
===================================================
Name Description
1 "$coord" "Coordinates for the variables"
2 "$cor" "Correlations between variables and dimensions"
3 "$cos2" "Cos2 for the variables"
4 "$contrib" "contributions of the variables"
> # Coordinates
> head(var$coord)
Dim.1 Dim.2 Dim.3 Dim.4 Dim.5
食品 0.8309549 -0.439440979 0.1151560 0.157267242 0.23942030
衣着 0.5968496 0.594904015 0.5130757 0.013283797 -0.06211260
居住 0.8674876 -0.038553622 -0.3007570 -0.311292972 -0.05351647
医疗 0.6377140 0.664657743 -0.2453518 0.002703152 0.28597319
交通通讯 0.9113413 -0.323711002 0.1000397 0.065838532 0.07908669
教育 0.8970832 -0.007529241 0.1420381 -0.254423709 -0.08501927
> # Cos2: quality on the factore map
> head(var$cos2)
Dim.1 Dim.2 Dim.3 Dim.4 Dim.5
食品 0.6904861 1.931084e-01 0.01326091 2.473299e-02 0.057322080
衣着 0.3562295 3.539108e-01 0.26324670 1.764593e-04 0.003857975
居住 0.7525348 1.486382e-03 0.09045477 9.690331e-02 0.002864013
医疗 0.4066792 4.417699e-01 0.06019753 7.307029e-06 0.081780663
交通通讯 0.8305430 1.047888e-01 0.01000794 4.334712e-03 0.006254705
教育 0.8047584 5.668948e-05 0.02017483 6.473142e-02 0.007228276
> # Contributions to the principal components
> head(var$contrib)
Dim.1 Dim.2 Dim.3 Dim.4 Dim.5
食品 12.813875 15.670621251 2.492305 8.281295869 25.252800
衣着 6.610821 28.719634446 49.475573 0.059083501 1.699601
居住 13.965361 0.120618931 17.000408 32.445942285 1.261719
医疗 7.547054 35.849346573 11.313750 0.002446598 36.027840
交通通讯 15.413018 8.503545275 1.880930 1.451383010 2.755462
教育 14.934513 0.004600315 3.791734 21.673892623 3.184361
可以看出在第一主成分中,食品、居住、交通通讯和教育贡献率较大,而在第二主成分中医疗贡献率较大,在第三主成分中衣着贡献率较大。
Correlation circle
The correlation between a variable and a principal component (PC) is used as the coordinates of the variable on the PC i.e. variables are represented by their correlations.
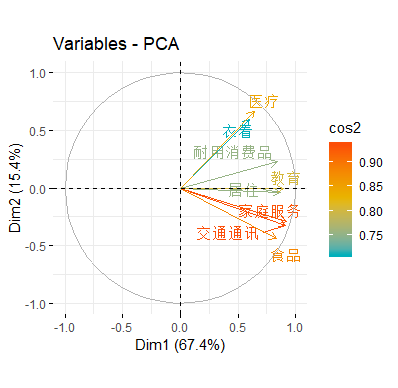
Quality of representation
The quality of representation of the variables on factor map is called cos2 (square cosine, squared coordinates) .
其实吧……我觉得它的第一主成分就包含了足够多的信息哈哈,把它直接降至一维就很不错。
It’s also possible to create a bar plot of variables cos2 using the function fviz_cos2()[in factoextra]
# Total cos2 of variables on Dim.1 and Dim.2
fviz_cos2(res.pca, choice = "var", axes = 1:2)
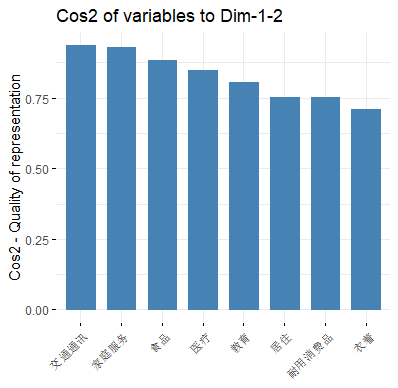
A high cos2 indicates a good representation of the variable on the principal component. In this case the variable is positioned close to the circumference of the correlation circle.
A low cos2 indicates that the variable is not perfectly represented by the PCs. In this case the variable is close to the center of the circle.
而我们发现大部分的变量的 cos2 均较高,这与这些变量在之前的相关圆中接近圆周是一致的。这也表明用两个主成分能很好地反应这些变量的信息。
下用颜色代表不同的 gradient 重新绘制 color variables by their cos2 values
那就写到这里吧,更多关于PCA分析绘图可以看 ref 链接:
http://www.sthda.com/english/articles/31-principal-component-methods-in-r-practical-guide/112-pca-principal-component-analysis-essentials.

本文分享自微信公众号 - 生信科技爱好者(bioitee)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。

