搜索引擎背后的经典数据结构和算法
前言
我们每天都在用 Google, 百度这些搜索引擎,那大家有没想过搜索引擎是如何实现的呢,看似简单的搜索其实技术细节非常复杂,说搜索引擎是 IT 皇冠上的明珠也不为过,今天我们来就来简单过一下搜索引擎的原理,看看它是如何工作的,当然搜索引擎博大精深,一篇文章不可能完全介绍完,我们只会介绍它最重要的几个步骤,不过万变不离其宗,搜索引擎都离不开这些重要步骤,剩下的无非是在其上添砖加瓦,所以掌握这些「关键路径」,能很好地达到观一斑而窥全貎的目的。
本文将会从以下几个部分来介绍搜索引擎,会深度剖析搜索引擎的工作原理及其中用到的一些经典数据结构和算法,相信大家看了肯定有收获。
- 搜索引擎系统架构图
- 搜索引擎工作原理详细剖析
搜索引擎系统架构图
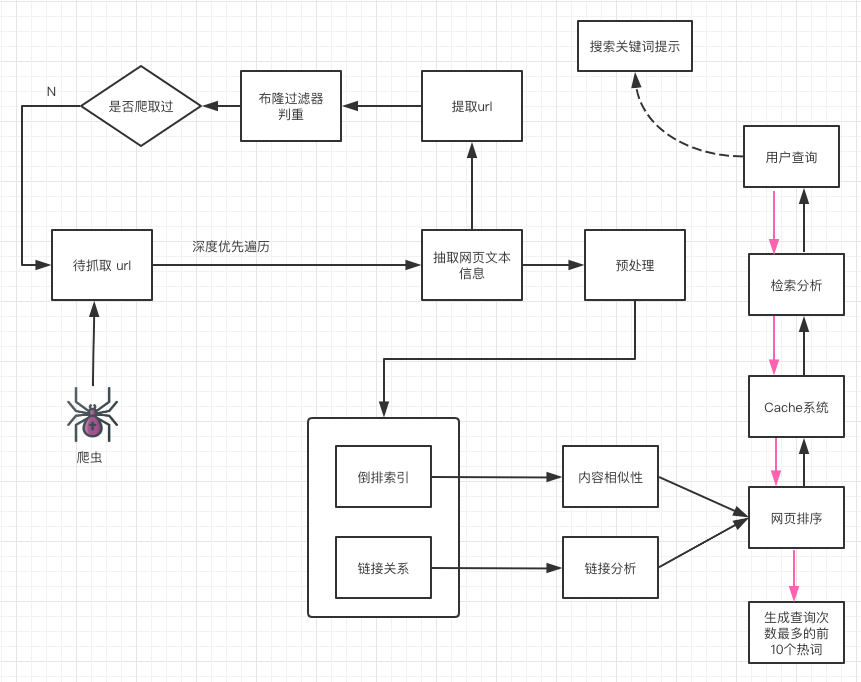
搜索引擎整体架构图如下图所示,大致可以分为搜集,预处理,索引,查询这四步,每一步的技术细节都很多,我们将在下文中详细分析每一步的工作原理。
搜索引擎工作原理详细剖析
一、收集
爬虫一开始是不知道该从哪里开始爬起的,所以我们可以给它一组优质种子网页的链接,比如新浪主页,腾讯主页等,这些主页比较知名,在 Alexa 排名上也非常靠前,拿到这些优质种子网页后,就对这些网页通过广度优先遍历不断遍历这些网页,爬取网页内容,提取出其中的链接,不断将其将入到待爬取队列,然后爬虫不断地从 url 的待爬取队列里提取出 url 进行爬取,重复以上过程...
当然了,只用一个爬虫是不够的,可以启动多个爬虫并行爬取,这样速度会快很多。
1、待爬取的 url 实现
待爬取 url 我们可以把它放到 Redis 里,保证了高性能,需要注意的是,Redis 要开启持久化功能,这样支持断点续爬,如果 Redis 挂掉了,重启之后由于有持续久功能,可以从上一个待爬的 url 开始重新爬。
2、如何判重
如何避免网页的重复爬取呢,我们需要对 url 进行去重操作,去重怎么实现?可能有人说用散列表,将每个待抓取 url 存在散列表里,每次要加入待爬取 url 时都通过这个散列表来判断一下是否爬取过了,这样做确实没有问题,但我们需要注意到的是这样需要会出巨大的空间代价,有多大,我们简单算一下,假设有 10 亿 url (不要觉得 10 亿很大,像 Google, 百度这样的搜索引擎,它们要爬取的网页量级比 10 亿大得多),放在散列表里,需要多大存储空间呢?
我们假设每个网页 url 平均长度 64 字节,则 10 亿个 url 大约需要 60 G 内存,如果用散列表实现的话,由于散列表为了避免过多的冲突,需要较小的装载因子(假设哈希表要装载 10 个元素,实际可能要分配 20 个元素的空间,以避免哈希冲突),同时不管是用链式存储还是用红黑树来处理冲突,都要存储指针,各种这些加起来所需内存可能会超过 100 G,再加上冲突时需要在链表中比较字符串,性能上也是一个损耗,当然 100 G 对大型搜索引擎来说不是什么大问题,但其实还有一种方案可以实现远小于 100 G 的内存:布隆过滤器。
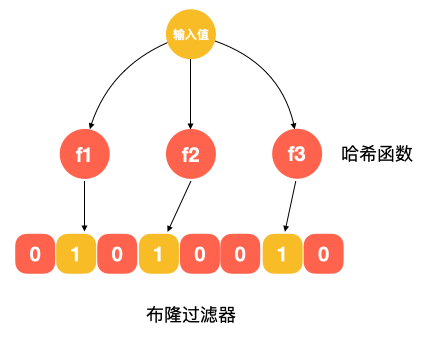
针对 10 亿个 url,我们分配 100 亿个 bit,大约 1.2 G, 相比 100 G 内存,提升了近百倍!可见技术方案的合理选择能很好地达到降本增效的效果。
当然有人可能会提出疑问,布隆过滤器可能会存在误判的情况,即某个值经过布隆过滤器判断不存在,那这个值肯定不存在,但如果经布隆过滤器判断存在,那这个值不一定存在,针对这种情况我们可以通过调整布隆过滤器的哈希函数或其底层的位图大小来尽可能地降低误判的概率,但如果误判还是发生了呢,此时针对这种 url 就不爬好了,毕竟互联网上这么多网页,少爬几个也无妨。
3、网页的存储文件: doc_raw.bin
爬完网页,网页该如何存储呢,有人说一个网页存一个文件不就行了,如果是这样,10 亿个网页就要存 10 亿个文件,一般的文件系统是不支持的,所以一般是把网页内容存储在一个文件(假设为 doc_raw.bin)中,如下
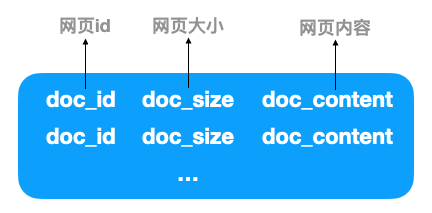 当然一般的文件系统对单个文件的大小也是有限制的,比如 1 G,那在文件超过 1 G 后再新建一个好了。
当然一般的文件系统对单个文件的大小也是有限制的,比如 1 G,那在文件超过 1 G 后再新建一个好了。
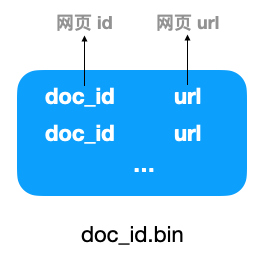
图中网页 id 是怎么生成的,显然一个 url 对应一个网页 id,所以我们可以增加一个发号器,每爬取完一个网页,发号器给它分配一个 id,将网页 id 与 url 存储在一个文件里,假设命名为 doc_id.bin,如下
二、预处理
爬取完一个网页后我们需要对其进行预处理,我们拿到的是网页的 html 代码,需要把 <script>,<style>,<option> 这些无用的标签及标签包含的内容给去掉,怎么查找是个学问,可能有人会说用 BF ,KMP 等算法,这些算法确实可以,不过这些算法属于单模式串匹配算法,查询单个字段串效率确实不错,但我们想要一次性查出<script>,<style>,<option>这些字段串,有啥好的方法不,答案是用AC 自动机多模式串匹配算法,可以高效一次性找出几个待查找的字段串,有多高效,时间复杂度接近 0(n)!关于 AC 自动机多模式匹配算法的原理不展开介绍,大家可以去网上搜搜看, 这里只是给大家介绍一下思路。
找到这些标签的起始位置后,剩下的就简单了,接下来对每个这些标签都查找其截止标签 </script>,</style>,</option>,找到之后,把起始终止标签及其中的内容全部去掉即可。
做完以上步骤后,我们也要把其它的 html 标签去掉(标签里的内容保留),因为我们最终要处理的是纯内容(内容里面包含用户要搜索的关键词)
三、分词并创建倒排索引
拿到上述步骤处理过的内容后,我们需要将这些内容进行分词,啥叫分词呢,就是将一段文本切分成一个个的词。比如 「I am a chinese」分词后,就有 「I」,「am」,「a」,「chinese」这四个词,从中也可以看到,英文分词相对比较简单,每个单词基本是用空格隔开的,只要以空格为分隔符切割字符串基本可达到分词效果,但是中文不一样,词与词之类没有空格等字符串分割,比较难以分割。以「我来到北京清华大学」为例,不同的模式产生的分词结果不一样,以 github 上有名的 jieba 分词开源库为例,它有如下几种分词模式
【全模式】: 我/ 来到/ 北京/ 清华/ 清华大学/ 华大/ 大学
【精确模式】: 我/ 来到/ 北京/ 清华大学
【新词识别】:他, 来到, 了, 网易, 杭研, 大厦
【搜索引擎模式】: 小明, 硕士, 毕业, 于, 中国, 科学, 学院, 科学院, 中国科学院, 计算, 计算所, 后, 在, 日本, 京都, 大学, 日本京都大学, 深造
分词一般是根据现成的词库来进行匹配,比如词库中有「中国」这个词,用处理过的网页文本进行匹配即可。当然在分词之前我们要把一些无意义的停止词如「的」,「地」,「得」先给去掉。
经过分词之后我们得到了每个分词与其文本的关系,如下

细心的你一定发现了,不同的网页内容有可能出现同样的分词,所以我们把具有相同分词的网页归在一起,如下所示

这样我们在搜「大学」的时候找到「大学」对应的行,就能找到所有包含有「大学」的文档 id 了。
看到以上「分词」+「倒排索引」的处理流程,大家想到了什么?没错,这不就是 ElasticSearch 搜索引擎干的事吗,也是 ES 能达到毫秒级响应的关键!
这里还有一个问题,根据某个词语获取得了一组网页的 id 之后,在结果展示上,哪些网页应该排在最前面呢,为啥我们在 Google 上搜索一般在第一页的前几条就能找到我们想要的答案。这就涉及到搜索引擎涉及到的另一个重要的算法: PageRank,它是 Google 对网页排名进行排名的一种算法,它以网页之间的超链接个数和质量作为主要因素粗略地分析网页重要性以便对其进行打分。我们一般在搜问题的时候,前面一两个基本上都是 stackoverflow 网页,说明 Google 认为这个网页的权重很高,因为这个网页被全世界几乎所有的程序员使用着,也就是说有无数个网页指向此网站的链接,根据 PageRank 算法,自然此网站权重就啦,恩,可以简单地这么认为,实际上 PageRank 的计算需要用到大量的数学知识,毕竟此算法是 Google 的立身之本,大家如果有兴趣,可以去网上多多了解一下。
完成以上步骤,搜索引擎对网页的处理就完了,那么用户输入关键词搜索引擎又是怎么给我们展示出结果的呢。
四、查询
用户输入关键词后,首先肯定是要经过分词器的处理。比如我输入「中国人民」,假设分词器分将其分为「中国」,「人民」两个词,接下来就用这个两词去倒排索引里查相应的文档

得到网页 id 后,我们分别去 doc_id.bin,doc_raw.bin 里提取出网页的链接和内容,按权重从大到小排列即可。
这里的权重除了和上文说的 PageRank 算法有关外,还与另外一个「 TF-IDF 」(https://zh.wikipedia.org/wiki/Tf-idf)算法有关,大家可以去了解一下。
另外相信大家在搜索框输入搜索词的时候,都会注意到底下会出现一串搜索提示词,
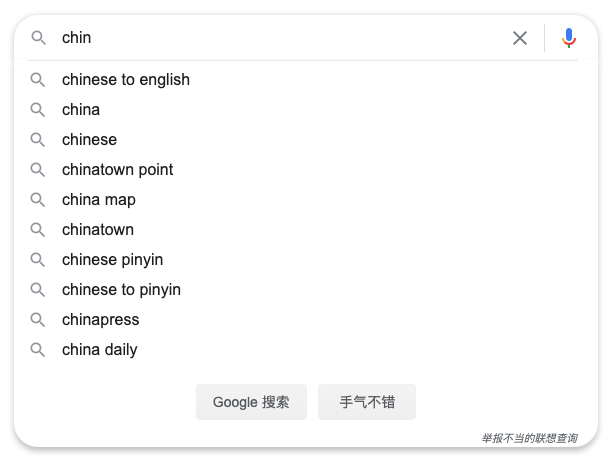
如图示:输入 chin 这四个字母后,底下会出现一列提示词。
如何实现的,这就不得不提到一种树形结构:Trie 树。Trie 树又叫字典树、前缀树(Prefix Tree)、单词查找树,是一种多叉树结构,如下图所示:
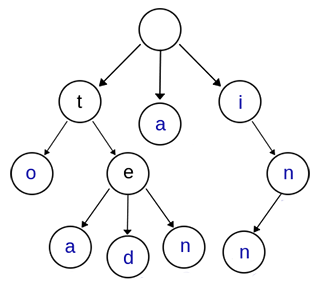 这颗多叉树表示了关键字集合 ["to","tea","ted","ten","a","i","in", "inn"]。从中可以看出 Trie 树具有以下性质:
这颗多叉树表示了关键字集合 ["to","tea","ted","ten","a","i","in", "inn"]。从中可以看出 Trie 树具有以下性质:
- 根节点不包含字符,除根节点外的每一个子节点都包含一个字符
- 从根节点到某一个节点,路径上经过的字符连接起来,为该节点对应的字符串
- 每个节点的所有子节点包含的字符互不相同
通常在实现的时候,会在节点结构中设置一个标志,用来标记该结点处是否构成一个单词(关键字)。
另外我们不难发现一个规律,具有公共前缀的关键字(单词),它们前缀部分在 Trie 树中是相同的,这也是 Trie 树被称为前缀树的原因,有了这个思路,我们不难设计出上文所述搜索时展示一串搜索提示词的思路:
一般搜索引擎会维护一个词库,假设这个词库由所有搜索次数大于某个阈值(如 1000)的字符串组成,我们就可以用这个词库构建一颗 Trie 树,这样当用户输入字母的时候,就可以以这个字母作为前缀去 Trie 树中查找,以上文中提到的 Trie 树为例,则我们输入「te」时,由于以「te」为前缀的单词有 ["tea","ted","ted","ten"],则在搜索引擎的搜索提示框中就可以展示这几个字符串以供用户选择。
五、寻找热门搜索字符串
Trie 树除了作为前缀树来实现搜索提示词的功能外,还可以用来辅助寻找热门搜索字符串,只要对 Trie 树稍加改造即可。假设我们要寻找最热门的 10 个搜索字符串,则具体实现思路如下:
一般搜索引擎都会有专门的日志来记录用户的搜索词,我们用用户的这些搜索词来构建一颗 Trie 树,但要稍微对 Trie 树进行一下改造,上文提到,Trie 树实现的时候,可以在节点中设置一个标志,用来标记该结点处是否构成一个单词,也可以把这个标志改成以节点为终止字符的搜索字符串个数,每个搜索字符串在 Trie 树遍历,在遍历的最后一个结点上把字符串个数加 1,即可统计出每个字符串被搜索了多少次(根节点到结点经过的路径即为搜索字符串),然后我们再维护一个有 10 个节点的小顶堆(堆顶元素比所有其他元素值都小,如下图示)
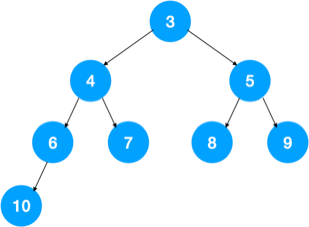 如图示:小顶堆中堆顶元素比其他任何元素都小
如图示:小顶堆中堆顶元素比其他任何元素都小
依次遍历 Trie 树的节点,将节点(字符串+次数)传给小顶堆,根据搜索次数不断调整小顶堆,这样遍历完 Trie 树的节点后,小顶堆里的 10 个节点即是最热门的搜索字符串。
总结
本文简述了搜索引擎的工作原理,相信大家看完后对其工作原理应该有了比较清醒的认识,我们可以看到,搜索引擎中用到了很多经典的数据结构和算法,所以现在大家应该能明白为啥 Google, 百度这些公司对候选人的算法要求这么高了。
本文只是介绍了搜索引擎的基本工作原理,要深入了解还需多查资料了解哦。

本文分享自微信公众号 - 生信科技爱好者(bioitee)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号