
多元统计分析-判别分析
判别分析是用一种统计的方法根据已有的数据集去分析新的数据属于那一类的方法
适用于数据集较小的情况,因为数据量够大的话神经网络的准确率会比传统的判别分析高得多
距离判别法:
欧氏距离
简单的计算数据集中每一类的样本均值
对于新数据,计算新数据与各类样本均值的欧氏距离
取离此新数据距离最近的类别为此数据的类别
马氏距离
马氏距离的优点是考虑了各特征之间的相互关系与尺度
马氏距离的公式 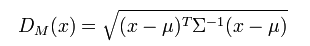
当协方差阵为单位阵时,各特征间无关,此时马氏距离等于欧氏距离
对马氏距离的具体分析在https://www.cnblogs.com/likai198981/p/3167928.html
具体做法
算出样本对每一类的距离,(在马氏距离中使用哪一类的均值和方差)
取距离最小的那一类即可
fisher判别法
fisher判别法是去找一个过原点的直线这个直线要达到的效果是
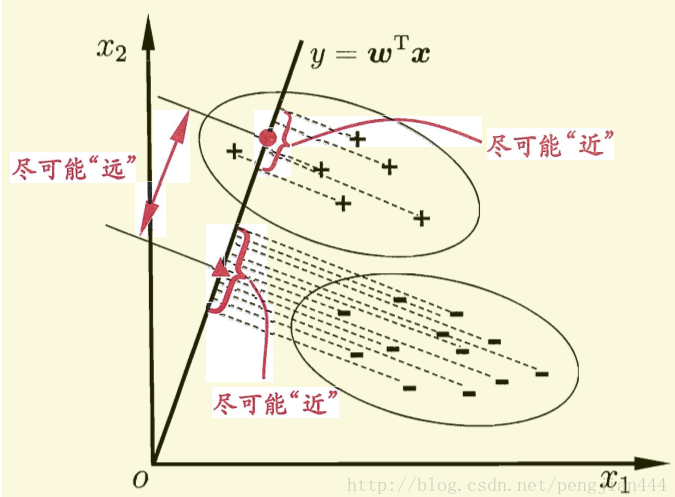
具体做法:

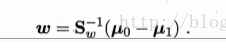
w即为这条直线的方向
直线为Y = wX
临界点y0 = (n0 * u0 + n1 * u1) / (n0 + n1)
判别时计算数据在线上的投影,将此投影与聚类的中心投影相比较得出此数据应属于那一类
贝叶斯判别法
书上的贝叶斯做法如下
对于两个多元总体
第一类有n1个样本,第二类有n2个样本
q1 = n1 / (n1 + n2)
q2 = n2 / (n1 + n2)
第一类的均值为u1,第二类的均值为u2
根据总体计算出协方差矩阵Σ
第i类样本的判别函数为
fi(x) = ln(qi) - 1/2 ui.T * Σ-1 * ui + x.T * Σ-1 * ui
然后对于所有点fi(x)做一个softmax然后其中的最大值就是后验概率
对于样本来说
首先我要知道密度函数和先验概率
对于k种分类先验概率为qk, 密度函数为fk
那么P(g|x)表示样本为x的情况下,种类为g的概率
P(g|x) = qg * fg(x) / ∑ qi * fi(x)
找出那个最大的P(g|x)即可
一般来说 qg使用样品频率来代替
计算出g的均值和方差,fg(x)使用正太分布来代替
工业上贝叶斯判别法用的也比较多
但一般来说不是这么用的
贝叶斯公式如下:

将其移项即可得到
P(gk|x) = P(x|gk) * ∑P(xi|gi) / P(x)
对于多元变量x,我们假设x的各个特征相互独立 设X = (u1,u2, ,,,,,um)
那么P(x|gk) = P(u1|gk) * P(u2|gk) **** P(um|gk)
P(x) = P(u1)*P(u2)*.....*P(um)
概率就用样本中的频率表示即可
一些理解
距离判别法
欧式距离只考虑了样本中心点的位置
马氏距离不仅考虑了样本中心点的位置,还考虑了样本各个特征间的相互关系以及样本的度量
fisher判别法
利用一条过原点的判别函数,使得不同类别在判别函数上投影的距离尽可能大
使得同一类的距离尽可能小
贝叶斯判别法
利用样本的先验概率计算密度函数
再使用密度函数,计算特定点的后验概率

