mysql学习笔记
mysql 的概述
1.什么是数据库
数据库就是一个 存储数据的仓库
2. 都有哪些公司在用数据库
购物网站, 金融机构, 游戏网站, 论坛网站

3. 提供数据库服务的软件
-
软件分类
mysql sql_server oracle mariadb db2 mongodb
-
在生产环境中,如何选择使用哪个数据库
-
是否开源
- 开源软件: 个人使用,免费, 企业使用, 收费 mysql mariadb mongodb
- 商业软件: 收费 oracle db2 sql_server
-
是否跨平台
- 不跨平台: sql_server
- 跨平台: 以上都是
-
公司的类型
商业软件: 政府部门, 金融机构
开源软件: 个人公司, 中小型企业
-
4.mysql 的特点
-
关系型数据库
-
关系型数据库的特点
- 数据是以行和列的形式去存储的
- 这一系列的行和列称为 表
- 表中的每一行 叫 一条记录
- 表中的每一列 叫 一个字段
- 表和表之间的逻辑关联叫关系
-
什么叫关系型数据库
-
关系型数据库存储
表1 : 学生信息表
姓名 年龄 班级
牛郎 25 aid1803
织女 23 aid1801
-
非关系型数据库中存储

-
-
-
跨平台
可以在 unix linux windows 上运行数据库服务
-
支持 多种编程语言
python, java, php ...
5. mysql 的安装
-
ubuntu 安装 mysql 服务 redhat(红帽子),centos, ubuntu
-
安装服务端
sudo apt install mysql-server
-
安装客户端
sudo apt install mysql-client
-
-
windows 安装 mysql 服务
- 官网下载 安装包
- 双击, 按照教程安装即可
6. mysql 服务
-
服务端启动
-
查看 mysql 服务状态
sudo /etc/init.d/mysql status
-
停止, 启动, 重启 mysql 服务
sudo /etc/init.d/mysql stop |start | restart
-
-
客户端连接
-
命令格式
mysql -h 主机地址 -u用户名 -p密码
mysql -hlocalhost -uroot -p123456
-
本地连接 可以 省略 -hlocalhost
-
MYSQL 基本操作
7. 基本sql 命令
sql 命令的使用规则
- 每条 sql 命令必须以 ; 结尾
- sql 命令不区分字母大小写
- 使用 \c 来终止命令的执行 (linux 中 ctrl + c)
库的管理
-
库的基本操作
-
查看已有的库
show databases;
-
创建库
create database 库名
create database 库名 default charset=utf8
-
查看创建库的语句
show create database 库名
-
查看当前所在库
select database();
-
切换库
use 库名;
-
查看库中已有表
show tables;
-
删除库
drop database 库名;
-
-
库名的命名规则
-
可以使用数字, 字母 , 下划线_ , 但不能使用纯数字
-
库名区分字母大小写
-
库名具有唯一性
-
不能使用特殊字符和 mysql 关键字
-
练习
- 创建库 aid1803db, 指定字符集为 utf-8
- 切换到该库 aid1803
- 查看当前所在库
- 查看库中已有的表
- 查看 aid1803 的字符集(查看创建库的语句)
- 删除库 aid1803db
create database aid1803 default charset=utf8;
use aid1803;
select database();
show tables;
show create database aid1803;
drop database aid1803;
表的管理
-
表的基本操作
-
创建表(指定字符集)
create table 表名(字段名 数据类型, 字段名 数据类型, ... ...);
create table 表名(字段名 数据类型, 字段名 数据类型, ... ...)default charset = utf8;
-
查看 创建表的语句(字符集)
show create table 表名;
-
查看表结构
desc 表名; -
删除表
drop table 表名;
-
-
表的命名规则(同库的命名规则)
-
练习
- 创建库 python
- 在库 python 中创建表 py_mysql, 指定字符集 utf8, 表中字段有 id int 和 name char(20) 两个字段
- 查看表 py_mysql 的字符集以及存储引擎
- 查看 py_mysql 的表结构
- 删除表 py_mysql
create database python; use python; create table py_mysql (id int,name char(20))default charset=utf8; show create table py_mysql; desc py_mysql; drop py_mysql; -
注意:
- 所有的数据都是以文件的形式存放在数据库目录下
- 数据库目录: /var/lib/mysql
8.更改库, 表 的默认字符集
-
方法
通过 mysql 服务的配置文件来实现
-
步骤

实际可能不同, 但是 大致一样
9. 表记录管理
在表中插入记录
insert into 表名 values(值1),(值2),...,(值n);

insert into 表名 (字段名列表) values(值1),...(值n);

查询表记录
select * from 表名; #查询所有字段
select 字段1, 字段2,....,字段n from 表名;
练习
- 查看所有的库
- 创建新库 stu1
- 在库 stu1 中创建表 students, 字段要求如下
- id int
- name char(15)
- age int
- address char(20)
- 在表中插入一条记录
- 在表中一次性插入两条记录
- 查看表 stu1 的表结构
- 查看所有表记录
- 删除表 students
- 删除库 stu1
1. show databases;
2. create database stu1;
3. create table students(id int,name char(15),age int,address char(20));
4. insert into students values(1,"mingyue",17,"china");
5.insert into students values(2,"shenxian",18,"jap"),(3,"xianhua",19"american");
6. show create table student;
7. select * from students;
8.drop table students;
9.drop database stu1;
10.客户端把数据存储到数据库服务器上的过程
- 连接到数据库服务器 mysql -uroot -p123456
- 选择一个库: use 库名
- 创建表 或者 修改表 : create .....
- 断开与数据库服务器的连接: exit | quit | \q
11.数据库名词
DB database 数据库
DBMS database management system 数据库管理系统:管理数据库的软件
DBS database system 数据库系统 dbs = db + dbms + 数据库应用+ users
12.数据库中的数据类型
-
数值型(有符号signed和无符号unsigned)
-
整型
- int 大整型(4个字节) 无符号:0~ 2**32 -1
- tinyint 微小整型(1个字节)
- 有符号(signed 默认):-128 ~ 127
- 有符号(unsigned ):0~255
-
浮点型
-
float(4 个字节, 最多显示 7 个有效位)
-
用法
字段名 float(m,n) m: 表示总位数 n:小数位位数
salary float(5,2) 取值范围: -999.99 ~ 999.99
-
注意
-
浮点型插入整数时会自动补全小数位位数
-
小数位如果多于指定的位数, 会对指定位的下一位进行四舍五入
float(5,2) -> 23.128 -> 23.13
-
-
-
double( 8 个字节, 最多显示 15 个有效位)
-
用法
字段名 double
其余 和 float 一致,
-
-
decimal (M + 2 个字节, 最多显示 28 个有效位)
-
用法
decimal(28,5)
-
-
-
-
字符类型
- char(定长)
- 取值范围: 1~255
- 默认为 1 (不指定宽度)
- varchar(变长)
- 取值范围: 1~ 65535
- 注意
- varchar 没有默认宽度, 必须给定一个宽度值 name varchar(20)
- char 和 varchar 的特点
- char 定长浪费存储空间, 但是性能高
- varchar 节省存储空间, 但是性能低下,
- char(定长)
-
枚举类型
-
定义
字段值只能在列举的范围内选择
-
enum(...) 单选(最多有 65535 个不同的值)
字段名 enum(值1, 值2,... , 值n)
-
set(...) 多选(最多有64 个不同的值)
字段名 set(值1, 值2,....,值n)
-
-
日期时间类型
- year: 年 YYYY
- date: 日期 YYYYMMDD
- time: 时间 HHMMSS
- datatime: 日期时间 YYYYMMDDHHMMSS
- timestamp: 日期时间 YYYYMMDDHHMMSS
注意
- 插入记录时, datatime 字段不给值, 默认返回 NULL
- timestamp 字段不给值默认返回系统当前时间
练习
-
创建表 stuinfo, 字段要求如下:
学号 id 大整型
姓名 name 变长, 宽度为 15
班级 classes 定长, 宽度为 7
年龄: age 微小整型, 要求不能输入负数
身高: height 浮点型, 小数位为 2 位,
-
查看表结构
-
在表 stuinfo 中插入2 条记录(行)
-
查询所有表记录
-
查询所有学生的姓名, 年龄和身高
create table stuinfo(id int, name varchar(15),classes char(7),age tinyint unsigned,height float(7,2));
desc stuinfo;
insert into stuinfo values(1,"mingyue","1803",18,1.85),(2,"shenhua","1803",19,1.86);
select * from stuinfo;
select name,age,height from stuinfo;
13. 表字段的操作
alter table 表名 执行动作;
添加字段
alter table 表名 add 字段名 数据类型 first | after 字段名;
删除字段
alter table 表名 drop 字段名;
修改字段数据类型
alter table 表名 modify 字段名 新数据类型;
不能从 int 改成 tinyint , 在修改数据类型时, 会受到表中原有数据的限制
修改字段名
alter table 表名 change 旧名 新名 数据类型;
修改表名
alter table 表名 rename 新表名;
14. 概念: 面试题
- 填空题
- mysql 中的数据类型 有 数值型 枚举型 字符串型 日期型
- 关系型数据库的核心内容是
- 简答题
- 简述客户端把数据存储到数据库服务器上的过程
- char 和 varchar 的区别? 各自的特点?
- 操作题
- 创建一个学校的库 school
- 在库中创建一张表 students 来存储学生信息 学号 姓名 年龄 成绩 性别 爱好 入学时间
- 查看students 的表结构
- 在 students 中添加一个字段id, 添加在第一列,
- 在表中随意插入 5 条记录
- 查看所有的学生信息
- 查看所有学生的姓名和成绩
- 练习一个 vi 文本编辑器
MySql设计规范
字符类型的宽度和数值类型的宽度的区别
- 数值类型的宽度仅仅为显示宽度, 只用于 select 查询显示, 和 占用的存储空间大小无关, 可用 zerofill 查看效果
- 字符类型的宽度超过则无法存储
where 条件子句
配合查询, 修改, 删除 , 操作 一起使用
语法格式
select * from 表名 where 条件;
表记录的管理
删除表记录
delete from 表名 where 条件;
注意: delete 语句后如果不加 where 条件子句, 会将表中所有记录全部删除
更新表记录
updata 表名 set 字段名1=值1 字段名2=值2,... where 条件;
update语句后如果不加 where 条件子句会将表中所有记录全部更改
运算符操作
数值比较&字符比较
数值比较: = != >= > < <=
字符比较运算符 = !=
范围内比较
运算符
between and
in
not in
语法
between 值1 and 值2
in(值1, 值2,...值n)
匹配空 非空
空: is null
非空 : is not null
注意:
- null : 空值,必须用 is 或者 is not 去匹配
- "" : 空字符串,用 = 或者 != 去匹配
模糊查询
_ : 匹配单个字符
% : 匹配0 到多个字符
示例:
- select name from sanguo where name like "_%_";
- select name from sanguo where name like "%";
- select name from sanguo where name like "___";
- select name from sanguo where name like "赵%"
正则匹配查询
-
where 字段名 regexp "正则表达式";
-
正则表达式符号
^ : 以.... 开头
$ : 以.... 结尾
. : 匹配任意一个字符
[]: 包含... 内容 [0~9]: 匹配带数字的 [a-z]:匹配带小写字母的
*: 星号前面的字符出现 0 个或者多次 .*
sql 查询
总结 (执行顺序)
3.5 select ... 聚合函数 from 表名
- where...
- group by...
- having ...
- order by...
- limit ...
order by
- 作用: 给查询的结果进行排序
- 语法格式: order by 字段名 排序方式;
- 排序方式
- asx(默认): 升序
- desc : 降序
limit(永远放在 sql 语句的最后写)
- 作用: 限制希纳是查询记录的个数
- 用法
- limit n: 显示 n 条记录
- limit m,n: 从第 (m+1)条开始, 显示 n 条记录
聚合函数
- 分类
- avg(字段名): 求字段的平均值
- sum(字段名): 求和
- max(字段名): 求最大值
- min(字段名):求最小值
- count(字段名): 统计该字段记录的个数
select sum(字段名) from 表名;
count(字段名) 空值不会被统计,空字符串会被统计
group by(先分组,再聚合)
select 字段名 from 表名 group by 字段名;
select country,avg(gongji) from sanguo group country;
执行过程:
- 先分组(此时未去重) group by country
- 再聚合( 求每组的平均攻击值)
- 去重
select country,count(*) from hero
group by country
order by count(*) desc
limit 2;
having
- 作用: 对查询的结果进行进一步筛选
distinct
作用: 不显示字段的重复值
select distinct 字段名 from 表名;
注意:
- distinct 处理的是 distinct 和 from 之间的所有字段, 所有字段的值必须完全相同才可以去重
- distinct 不能对任何字段做聚合处理
查询表数据的时候, 可以做数学运算
select 字段名*10 from 表名
+ - * / 都可以
约束
-
作用
为了保证数据的完整性 一致性 有效性, 可以限制无效的数据插入到数据表中
-
约束分类
-
默认约束(default)
-
作用: 在插入记录时, 如果不给该字段赋值,则使用默认值
-
格式
字段名 数据类型 default 默认值,
-
-
非空约束
-
作用: 不允许该字段的值有空值 NULL 记录
-
格式
字段名 数据类型 not null
-
-
索引
-
定义
对数据库中表的一列或者多列的值进行排序的一种结构(Mysql 中索引用 Btree 方式)
-
索引的优点
可以加快数据的检索速度
-
索引的缺点
- 当对表中的数据进行增加, 修改, 删除的时候, 索引需要动态维护, 降低了数据的维护速度
- 索引需要占用物理存储空间(数据库目录 /var/lib/mysql)
-
索引示例
- 运行 insert_.py 文件 , 插入100 万条数据
- 开始性能分析 set profiling = 1
- 执行 查询语句 select name from t1 where name="lucy999999";
- 查看性能分析结果 show profiles;
- 在 name 字段创建索引 create index name on t1(name);
- 执行查询语句 select name from t1 where name="lucy99999";
- 查看性能分析结果 show profiles;
- 关闭性能分析 set profiling = 0;
SQL 高级
索引
- 普通索引
- 唯一索引
- 主键属性
普通索引
使用规则:
创建
查看
- desc 表名; -> 查看key 标志为MUL
- show index from 表名 \G
删除
drop index 索引名 on 表名;
唯一索引
unique
使用规则
- 一个表中可以有多个 unique 字段
- unique 字段的值不允许重复,可以为空值 NULL
- unique 的 KEY 标志是 UNI
创建
基本等同 index创建
-
创建表时创建 : unique(字段名) ,unique(字段名)
-
已有表中创建
create unique index 索引名 on 表名(字段名);
查看, 删除
desc 表名
show index from 表名;
drop index 索引名 on 表名;
主键索引
primary key
自增长属性(auto_increment)
使用规则
- 一个表中只能有一个主键字段
- 对应字段的值不允许重复 且 不能为空值 NULL
- 主键字段的KEY标志为 PRI
- 把表中能够唯一标识一条记录的字段设置为主键, 通常把表中记录编号的字段设置为主键
创建主键
-
创建表时创建
- 字段名 数据类型 primary key auto_increment, 其他字段
- primary key(字段名); // 在最后写 可以 类型 auto_increment,
-
在已有表中添加主键
alter table 表名 add primary key(字段名) ;
-
删除主键
-
先删除自增长属性(modify)
alter table 表名 modify id int;
-
删除主键
alter table 表名 drop primary key;
-
主键有什么约束
字段值不允许重复也不允许为空值
主键约束 = 唯一约束 + not null
外键约束
走神了....
数据导入
把文件系统的内容导入到数据库中
load data infile "文件名"
into table 表名
fields terminated by "分隔符"
lines terminated by "\n"
实例
-
在数据库中创建对应的表
create table userinfo( username char(20), password char(20), uid int, gid int, comment varchar(50), homedir varchar(50), shell varchar(50) ) -
将要导入的文件拷贝到数据库的默认搜索路径中
-
查看数据库的默认搜索路径
show variables like "secure_file_priv";
/var/lib/mysql-files
-
sudo cp /etc/passwd /var/lib/mysql-files/
-
-
执行数据导入语句
load data infile "/var/lib/mysql-files/passwd" into table userinfo fields terminated by ":" lines terminated by "\n";
数据导出
将数据库表中的记录保存到系统文件里
select ... from 表名
into outfile "文件名"
fields terminated by "分隔符"
lines terminated by "\n";
表的复制
create table 表名 select 查询命令 ;
复制 userinfo 表中的全部记录 , userinfo2
create table userinfo2 select * from userinfo;
复制 userinfo 表中username, password , uid 三个字段的第 2 - 10 条记录, userinfo.
create table userinfo3 select username,password,uid from userinfo limit 1,9;
复制表结构
create table 表名 select 查询命令 where false;
复制表的时候不会把原有表的key 属性复制过来
嵌套查询(子查询)
把内层的查询结果作为 外层的查询条件
实例
把uid 的值 小于 uid 平均值的用户名 和 uid 号显示出来
select username,uid from userinfo
where uid < (select avg(uid)from userinfo) ;
连接查询
-
内连接
-
从表中删除与其他被连接的表中没有匹配到的行
-
语法格式
select 字段名列表 from 表1
-
-
外连接
- 左连接
- 右连接
多表查询
- select 字段名列表 from 表名列表;
- select 字段名列表 from 表名列表 where 条件;
mysql 用户账户管理
开始 mysql 远程连接
-
开始mysql 远程连接
-
获取 root 权限 sudo -i
-
cd 到配置文件所在路径 cd /etc/mysql/mysql.conf.d/
-
vi mysqld.cnf
bind-address = 127.0.0.1
修改这一行, 注释 或者 改成 * 任意
-
重启 mysql 服务 /etc/init.d/mysql restart
-
添加授权用户
-
使用 root 用户连接到服务器
mysql -uroot -p123456
-
添加新的授权用户
create user "用户名“@"ip地址"" identied by "密码";
create user "tiger"@"%" identified by "123456";
ip地址的表示方式:
- % 表示用户可以从任何地址连接到服务器
- localhost 用户只能从本地连接
- 指定一个 ip 表示用户只能从此 ip 连接到服务器
给用户授权
grant 权限列表 on 库.表 to "用户名"@"ip地址" with grant option;
grant all privileges on *.* to "tiger"@"%" with grant option;
权限列表 : select, update, delete , insert , alter, drop, create, ...
库.表: *.* 表示所有库的所有表
连接远程数据库命令 : mysql -hIP地址 -umonkey -p密码
练习
添加一个 授权用户 monkey , 所有人都可以连接, 只对 db1 库有查询权限
- 添加授权用户 monkey
- 给 monkey 用户授权
- 验证 : mysql -hIP地址 -umonkey -p密码
ip 地址查看 : linux 命令行: ifconfig
删除授权用户
drop user "用户名"@"IP地址";
drop user "tiger"@"%";
数据备份与恢复
备份
mysqldump -uroot -p 原库名 > 路径/*.sql
mysqldump -uroot -p db2 > /home/tarena/db2.sql
源数据库的表示方式
--all-databases 备份所有库
库名 备份单个库
-B 库1 库2 ... 备份多个库
库名 表1 表2 .. 备份制定库的指定表
恢复
mysql -u用户名 -p目标库名 < 路径/xxx.sql
备份分为 完全备份 和 增量备份
完全备份: mysqldump
增量备份: binlog日志, xbackup 工具
从所有库的备份文件中恢复某一个库 (--one-database)
mysql -u用户名 -p --one-database 目标库名 < all_mysql.sql
mysql -uroot -p --one-database db2 < all_mysql.sql
注意:
- 恢复库时库中新增的表不会删除
- 恢复时必须先创建空库
事务和事务回滚
- 事务: 一件事从开始发生到结束的整个过程
- 作用: 确保数据的一致性
mysql 中默认 sql 语句会自动 commit 到数据库
show variables like "autocommit";
事务应用
开始事务
start transaction;
此时 autocommit 被禁用 , sql 命令不会对数据库中数据做修改
终止事务
commit; 提交: 代表数据库 成功被修改
or
rollback; 回滚: 表示数据库 出现了问题, 没有 被修改
案例

存储引擎
用来处理 表的 处理器
innodb myisam
存储引擎的基本操作
-
查看 已有表的存储引擎
show create table 表名;
-
创建表时指定存储引擎
create table 表名(...) engine = myisam;
-
查看所有的存储引擎
show engines;
常用存储引擎的特点
- innodb 特点
- 共享表空间
- 支持行级锁
- myisam 特点
- 独享表空间
- 支持表级锁
如何决定使用那种 存储引擎
- 执行查询操作多的表使用 myisam 存储引擎(使用 innodb 浪费资源)
- 执行写操作比较多的表使用 innodb 存储引擎
如何更改表的 默认存储引擎
-
sudo -i
-
cd /etc/mysql/mysql.conf.d/
-
vi mysqld.cnf
[mysqld]
default-storage-engine = myisam
-
/etc/init.d/mysql restart
Memory 存储引擎
memory : 表记录存储在内存中
表名.frm 表结构
特点 : 服务重启之后结构在, 表记录都消失
锁
-
枷锁的目的
解决客户端并发访问的冲突问题
-
锁类型
读锁(select) 共享锁
加读锁之后不能更改表中内容,但可以进行查询
写锁(insert, update, delete ) 互斥锁, 排他锁
-
锁粒度 操作完成后, 会自动释放锁
表级锁
行级锁
mysql 调优
- 选择合适的存储引擎
- 经常用来读的表使用 myisam 存储引擎
- 其余的表都用 innodb 存储引擎
- sql 语句调优 ( 尽量避免全表扫描)
- 在 select, where, order by , 常涉及到的字段上建立索引
- where 子句中 尽量不要使用 != , 否则将放弃使用 索引 进行全表扫描
- 尽量避免用 NULL 值判断, 否则会全表扫描
- 尽量避免 使用or 来连接条件, 也会进行全表扫描
- 模糊查询尽量避免使用 前置 %, 导致全表扫描
- 尽量避免使用 select * ..., 要用具体的字段列表代替 * , 不要返回用不到的任何字段
python 数据库编程
python数据库接口 (python db-api)
为开发人员提供的数据库应用编程接口
支持的数据库服务软件: mysql Oracle SQL_Server, mongodb..
python提供的操作 mysql 模块
python3: pymysql
python2: MySQLdb
pymsql 模块使用流程
- 建立数据库连接
- 创建游标对象
- 使用游标对象的方法操作数据库
- 提交 commit
- 关闭游标对象
- 关闭数据库连接
实例
#coding = utf-8
#1. 创建数据库连接
db = pymysql.connect("localhost","root","123456","db2") #这边并不需要指定 默认字符集
#2. 创建游标对象
cursor = db.cursor()
# 3. 利用游标对象 cursor 的方法来操作数据库
cursor.execute("insert into sheng values(1,20000,'四川省');")
# 4. 提交到数据库 commit
db.commit()
# 5. 关闭游标对象
cursor.close()
# 6. 关闭数据库连接
db.close()
建立数据库连接 语法格式
2.32.43
-
语法格式
对象名 = pymysql.connect("主机地址","用户名","密码","库名",charset= "utf-8")
-
connect连接对象支持的方法
- cursor() 创建一个游标对象 db.cursor()
- commit() 提交到数据库执行(表记录增删改)
- rollback() 回滚
- close() 关闭数据库连接
-
游标对象支持的方法
- execute("sql命令") 执行sql 命令
- fetchone() 取得结果集的第一条记录
- fetchmany(n) 取得结果集的n 条记录
- fetchall() 取得结果集的所有记录
- close() 关闭游标对象
实例
查询表中记录
#coding = utf-8
import pymysql as mq
db = mq.connect("192.168.102.133","mingyue","123","test")
cursor = db.cursor()
# 执行 sql 语句
cursor.execute("select * from t1;")
data = cursor.fetchall()
print("fetchone的结果:",data)
# 提交数据改变
db.commit()
# 关闭游标对象
cursor.close()
# 关闭数据库对象
db.close()
'''
fetchone的结果: ((1,), (1,), (2,), (3,))
'''
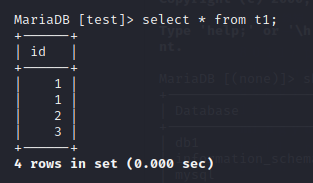
最终以元组的形式返回数据, 如果接收的长度 小于 查询数据的长度, 会进行截断操作
对元组进行处理, 就可以实现对数据的处理
python 使用面对对象 封装 sql操作
#coding = utf-8
import pymysql
class mysql:
def __init__(self,host,user,passwd,dbname,tablename):
'''
初始化 数据库对象
'''
self.db = pymysql.connect(host,user,passwd,dbname)
self.cur = db.cursor()
self.dbname = dbname
self.tablename = tablename
def select(self,name):
'''
查询 数据库中 内容
'''
checkcont = "select %s from %s;"%(name,tablename)
self.cur.execute(checkcont)
self.cur.close()
def insert(self,tablename,l):
'''
插入内容到数据库中
'''
try:
for i in l:
s = "insert into %s values (%s,%s,%s);"%(self.tablename,i[0],i[1],[2])
self.cur.execute(s)
self.db.commit()
except:
print("插入失败,出现异常")
self.db.rollback()
def execute(self,sql):
'''
执行sql 命令
'''
try:
self.cur.execute(sql)
self.db.commit()
except:
print("命令执行失败,出现异常,请检查 sql 语句是否正确书写")
self.db.rollback()
def __del__(self):
'''
析构函数
关闭游标对象
关闭 数据库对象
'''
self.cur.close()
self.db.close()
未经过测试的代码
mysql 的图形化操作
安装 mariadb 系统自动会 添加一个 heidiSQL 可以使用这个 远程连接数据库

然后其他动动手指即可
E-R 模型 & ER图
实体 - 关系 模型
- 实体
- 属性
- 关系
可以进行联想
-
定义: 实体之间的关系
-
分类
一对一关系 (1:1) : 班级与 班长 链表
一对多关系 (1:n) : 公司 和 职工 , 班级 和 学生 二叉树
多对多关系(m:n) : 学生和课程 集合
学生和课程的 ER图
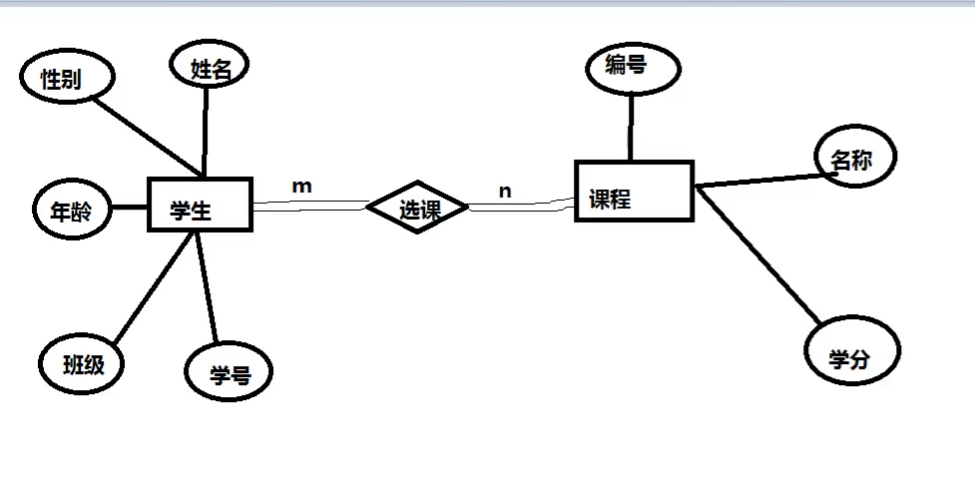
矩形框代替实体,菱形框代表关系, 椭圆形代表属性
总结
- mysql 很重要,对于数据管理来说,大型项目离不开数据库
- 这个mysql版本 索引使用的是 b树
- 有的地方,还需要更深层次的理解,万一以后用到了呢
