
网卡中断不均衡处理
在数据量大的时候,硬中断和软中断会形成瓶颈。
网卡接收数据包,从网卡产生中断信号,CPU将网络数据包拷贝到内核,然后进行协议栈的处理,最后将数据部分传递给用户空间,但硬件中断处理仅仅做从网卡拷贝数据的工作,而协议栈的处理的工作就交给软中断处理。所以当硬中断和软中断集中在cpu0的时候,会给调度带来负担(集中在其他cpu也会造成性能瓶颈,这里举cpu0的例子,是因为集中在cpu0影响最大)。
- 关闭irqbalance服务,service irqbalance stop,irqbalance在负载不高的时候是不错的服务,但负载太高,就显得力不从心,关闭irqbalance服务,我们自己手动绑定中断号到cpu。
- 然后确定使用的是哪个网卡,先lshw -C network –short看看都有哪些网卡。

可知有eth0 eth1 eth2 eth3四个网卡
- 然后ifconfig看下各网卡的流量,跑压测,再ifconfig,对比前后流量,可知是哪个网卡在跑。
压测前
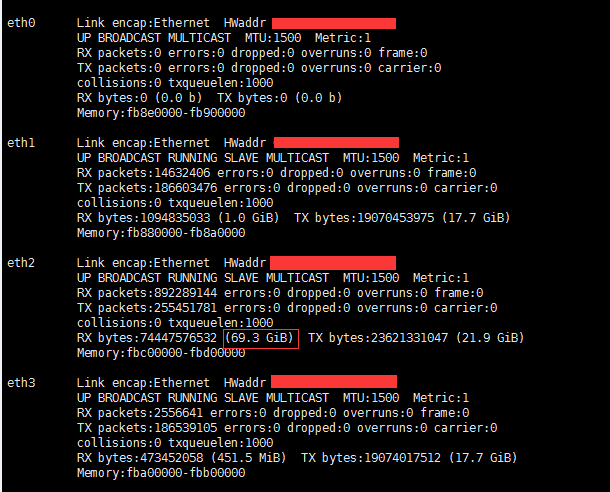
压测后
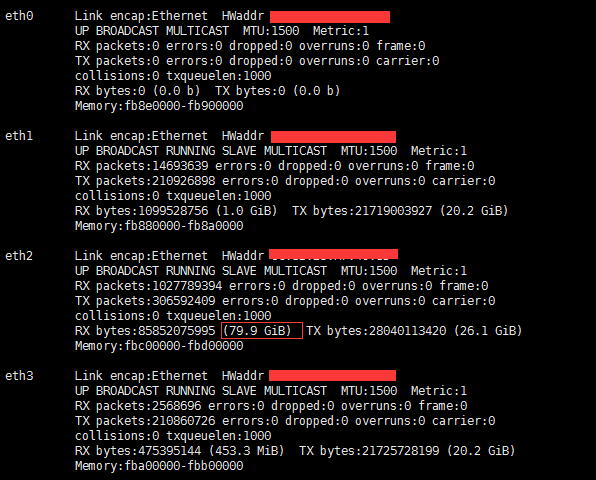
对比前后流量,可知用的是eth2
- 获取网卡的中断号
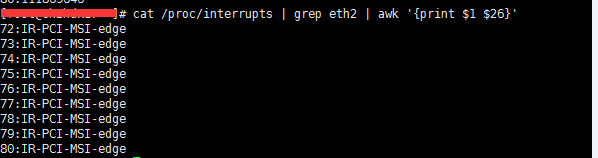
可知中断号是72-80
2.绑定
echo 9 > /proc/irq/72/smp_affinity_list
echo 10 > /proc/irq/73/smp_affinity_list
echo 11 > /proc/irq/74/smp_affinity_list
echo 12 > /proc/irq/75/smp_affinity_list
echo 13 > /proc/irq/76/smp_affinity_list
echo 14 > /proc/irq/77/smp_affinity_list
echo 15> /proc/irq/78/smp_affinity_list
echo 16 > /proc/irq/79/smp_affinity_list
echo 17 > /proc/irq/80/smp_affinity_list
网卡中断号的绑定可以分散硬中断,不过这样还不够彻底,因为硬中断集中在上述配置的几个核上,且软中断在硬中断结束后工作,也在同一个核上,一个核同时跑硬中断和软中断,这样会大大降低硬中断和软中断的处理速度,会对性能造成极大的瓶颈,因为如果中断没处理完,就无法分发请求到haproxy的各进程。
可通过rps和rfs,将软中断均衡到各个核上。
echo ffffff > /sys/class/net/eth2/queues/rx-0/rps_cpus 24核,所以设置fffff,分散到各核
echo ffffff > /sys/class/net/eth2/queues/rx-1/rps_cpus
echo ffffff > /sys/class/net/eth2/queues/rx-2/rps_cpus
echo ffffff > /sys/class/net/eth2/queues/rx-3/rps_cpus
echo ffffff > /sys/class/net/eth2/queues/rx-4/rps_cpus
echo ffffff > /sys/class/net/eth2/queues/rx-5/rps_cpus
echo ffffff > /sys/class/net/eth2/queues/rx-6/rps_cpus
echo ffffff > /sys/class/net/eth2/queues/rx-7/rps_cpus
echo 4096 > /sys/class/net/eth2/queues/rx-0/rps_flow_cnt 32768/N,N为网卡多队列的队列数
echo 4096 > /sys/class/net/eth2/queues/rx-1/rps_flow_cnt
echo 4096 > /sys/class/net/eth2/queues/rx-2/rps_flow_cnt
echo 4096 > /sys/class/net/eth2/queues/rx-3/rps_flow_cnt
echo 4096 > /sys/class/net/eth2/queues/rx-4/rps_flow_cnt
echo 4096 > /sys/class/net/eth2/queues/rx-5/rps_flow_cnt
echo 4096 > /sys/class/net/eth2/queues/rx-6/rps_flow_cnt
echo 4096 > /sys/class/net/eth2/queues/rx-7/rps_flow_cnt
echo 32768 > /proc/sys/net/core/rps_sock_flow_entries

