Amazon DeepRacer 让强化学习So Easy
Amazon DeepRacer 让强化学习So Easy
专注于基于AWS的云解决方案咨询工作,拥有15年IT行业从业经验和8年云架构咨询经验。在服务网宿科技全球一线客户的多年经验积累中,他敏锐意识到公司的目标客户群体与AWS客户群体的一致性,以及双方产品的互补性。基于AWS合作伙伴网络,他致力于推动网宿与AWS的技术、方案融合,解决外企入华和中国企业出海在技术方案选型、架构设计、持续优化等方面的诸多痛点,并成功为客户提供AWS源站的一站式计算、存储、网络、安全、加速解决方案。
作为一名人工智能 (Artificial Intelligence,AI) 新手,对于AI的学习在印象中一直是各种复杂算法和超多的数学公式,感觉学习无从下手。2021年6月,亚马逊云科技举办的Amazon DeepRacer线上大赛给了新手一个入门学习AI的机会,Amazon DeepRacer线上大赛是一个典型的强化学习AI场景。
为了简化和降低学习难度,在 Amazon DeepRacer 的控制台中,可以看到线上已有各种虚拟赛道环境和虚拟赛车。用户需要做的是,给赛车设定动作,设定奖励机制,然后让赛车一遍遍在赛道上奔跑,进行自我学习和强化训练。经过多次的训练和参数优化,选出一个最优模型与其他选手进行竞技。这就是一个 Amazon DeepRacer 简单的强化学习过程。
一、初体验
作为初次体验的新手,我们首先通过 Amazon DeepRacer 主页了解入门指导和规则,然后试着动手训练了第一个模型。在模拟跑道上模拟评估后,发现小车摇摇晃晃竟然也能完整地跑完一圈,只是后面两圈跑到圈外了。
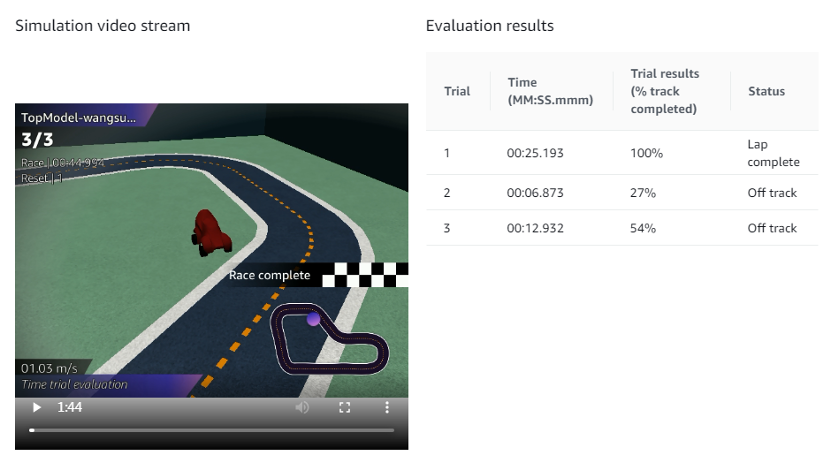
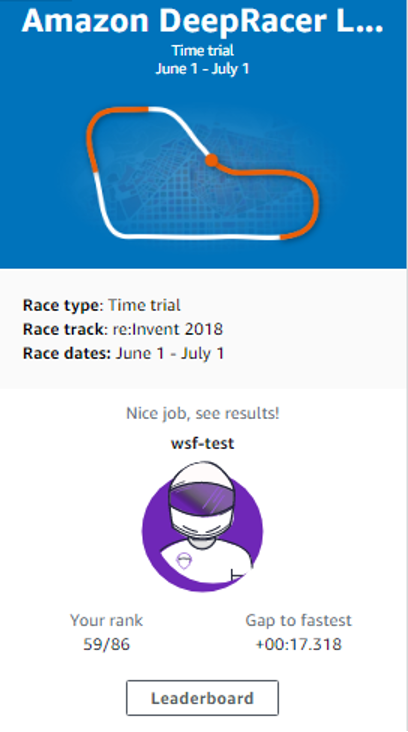
有了第一次经验后,我们后面就增加了训练时长,稍微修改了参数和奖励规则,重新训练好一个新模型。怀着忐忑的心情提交模型,与其他参赛者第一次竞赛,在86名参赛者中,我们的排名是59。竟然不是最后一名,感觉很欣喜和意外。
二、训练有道
通过参加一次完整的线上比赛,我们发现入门其实非常简单,具体操作过程如下。
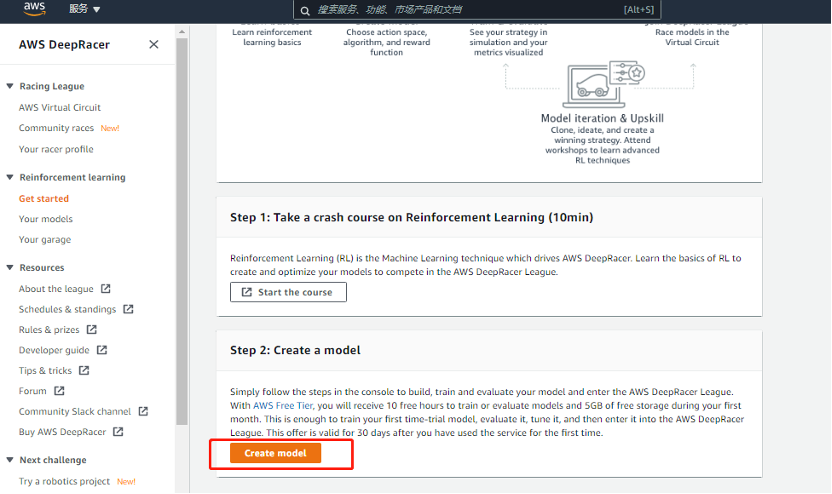
第一步,打开 Amazon DeepRacer 控制台,在了解基本原理后,点击 Create model 按钮开始创建模型。
创建模型时,先确认设置一个模型名称和环境模拟信息。
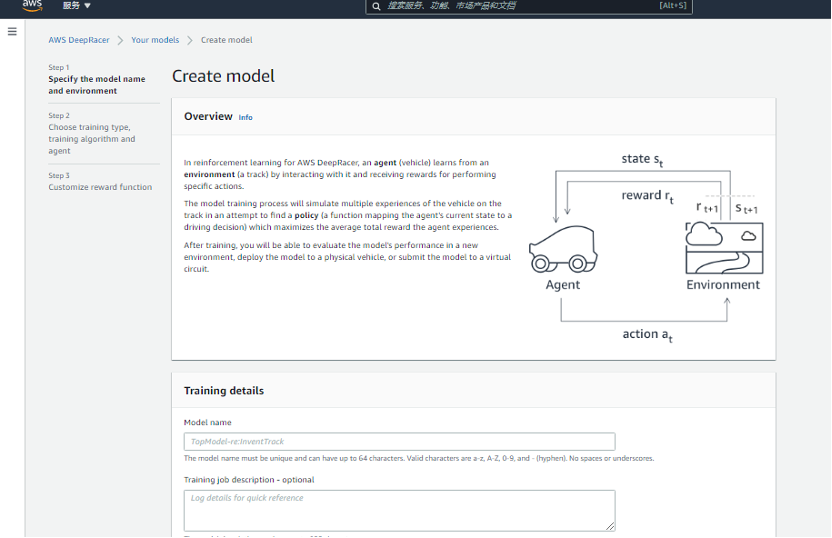
环境模拟 (Environment simulation) 部分选择用于训练的跑道。对于2021月6月的比赛,我们选择的跑道是“re:Invent 2018”。

第二步,选择模型的比赛类型 (Race type)、设置训练算法和超参和选择比赛车辆。
其中,比赛类型共三种模式:纯竞速、避障竞速、躲避车辆的竞速。我们默认选最简单的纯竞速模式。

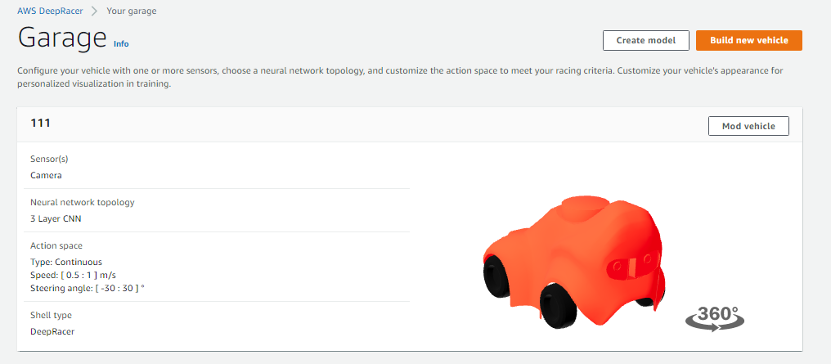
训练算法和超参可以采用默认设置,后续想提高成绩需要进行尝试不同的参数组合。由于学习框架为Tensorflow,所以会涉及 Tensorflow 框架中的相关算法和超参,默认算法是 PPO。其他超参包括:梯度下降的Batch size、学习率、损失函数等。对于这些超参,在首次体验也可以采用默认值。
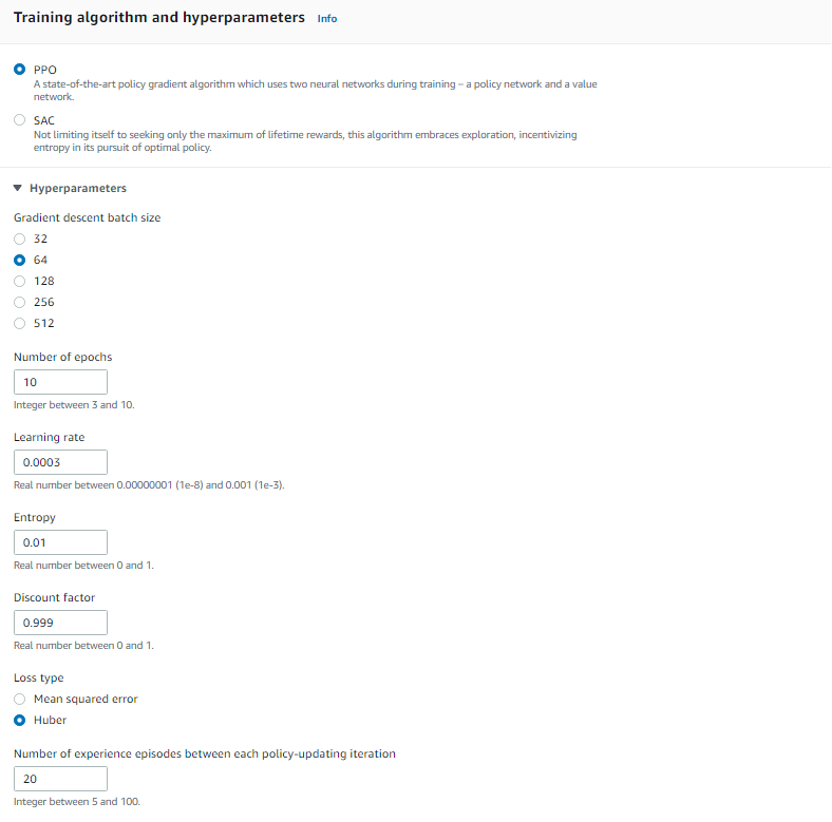
关于比赛车辆,车库(Your garage)中默认有一辆赛车,同时也支持自己定义车辆,包括自主选择赛车的颜色和action的转向角度等。
第三步,编写奖励函数 (Reward function)。奖励函数是模型的关键,奖励函数本质是训练赛车规则的组合,其关乎最终训练出来的模型质量。用户可以按照自己的想法编写奖励函数,在奖励函数中可以实时获取并计算赛车的各种状态,包括:赛车与赛道中线的距离、赛车到赛道两侧的距离、判断赛车是否脱离轨道、赛车当前的速度、赛道完成度等状态。根据赛车不同的状态,给予不同的奖励。例如,距离中线越近、比赛完成度越高、所有轮子都在跑道内、速度越高等情况下,给予正向奖励,在偏离赛道或未遵守自定义规则的情况下给予惩罚。基于以上奖励规则进行多次训练,赛车就会在赛道内按照规则进行奔跑。
编程高手甚至可以计算赛道的最优路径,基于最优路径调整速度并给予相应的奖励,从而训练获得更加精确的模型。

奖励函数的编程语言为Python。即使对Python不熟的用户也不会受影响,因为默认会有一个简单的奖励函数,可以不做修改直接使用。
关于训练时长需要合理设置,因为训练过程要占用 Amazon Web Services 底层资源,会产生费用。新用户会有xx小时的免费时长,同时,每个参赛队伍账号可以申请一定的服务抵扣券。学习时间长与超参中Learning rate相关,Learning rate调大时,训练时长可以调短,Learning rate调小时,训练时长可以加大,初次训练时可以使用默值。
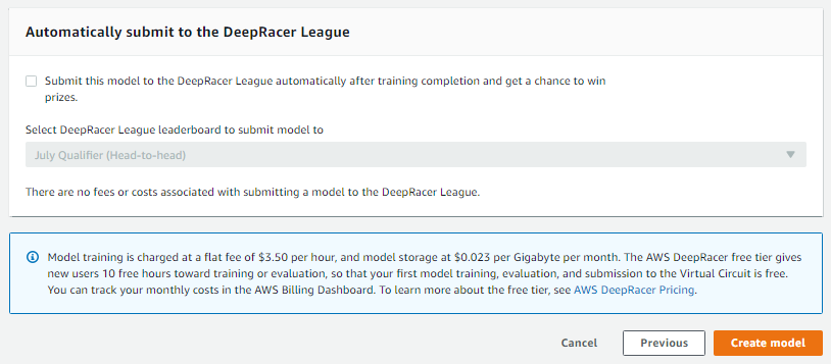
关于“模型训练完成后是否直接提交比赛?”这个选项,默认是直接提交,建议把勾选去掉,不直接提交。等模型训练完成后,先评估模型的效果再提交。训练效果差的模型,即使提交比赛也是被其他队伍吊打。
如果以上相关设置无问题,就可以单击 “Create model” 按钮创建自己的第一个模型了。
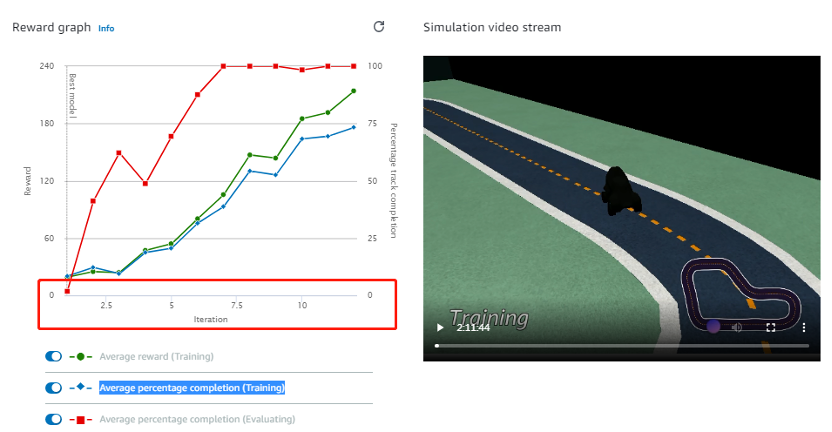
模型创建成功后,会经过几分钟的初始化过程,系统后台会按照创建模型的设置自动准备资源并开始训练。开始训练后,通过控制台可以实时观测训练过程,如下图,图片左侧显示模型训练的实时完成度,右侧显示赛车在赛道上实时运动轨迹的视频。在视频中可以观察到,训练初始阶段,赛车一直在尝试不同的运动方向,非常容易跑出赛道,随着训练的进行,赛车脱离赛道的概率变低,直到最后顺利跑完三圈,模型训练成功。正常情况下,模型训练过程中三条曲线随着训练过程,趋势逐步向上,直到Average percentage completion达到100%。
三、一决高下
模型完成训练后,我们可以通过控制台评估一下模型训练的效果,点击 Start evaluation按钮开始模型评估。。
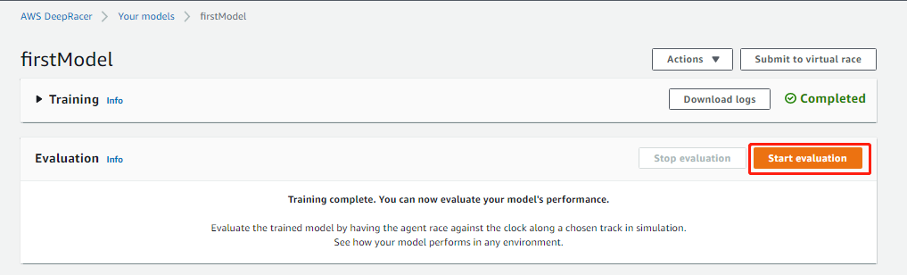
评估完成后结果如下图,若Trail results均为100%,并且Status为Lap complete,恭喜你,可以使用该模型和其他队伍一决高下了。
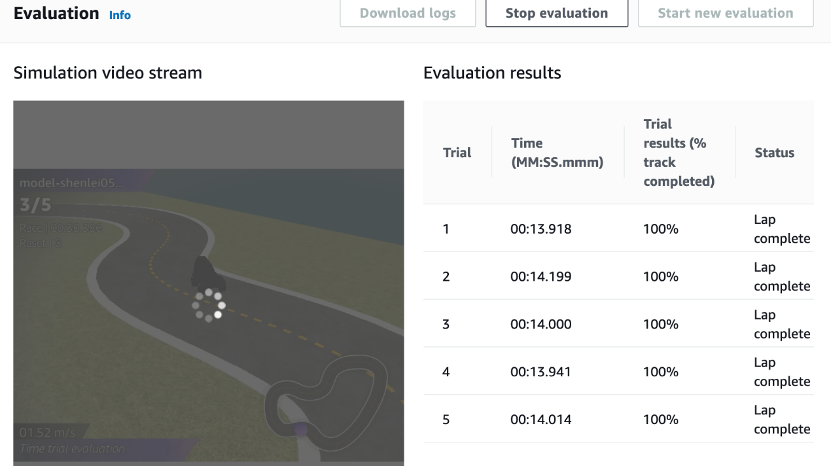
在控制台中,提交模型与其他队伍比赛过程如下,通过菜单Community races找到想要参加的比赛,在比赛面板中点击Enter race或Race again按钮提交模型进行模拟比赛。每个参赛队伍在比赛结束截止时间前,可以多次提交模型进行比赛,每次比赛的成绩为完整跑完三圈赛道的时间,排名最终以最优成绩为准。
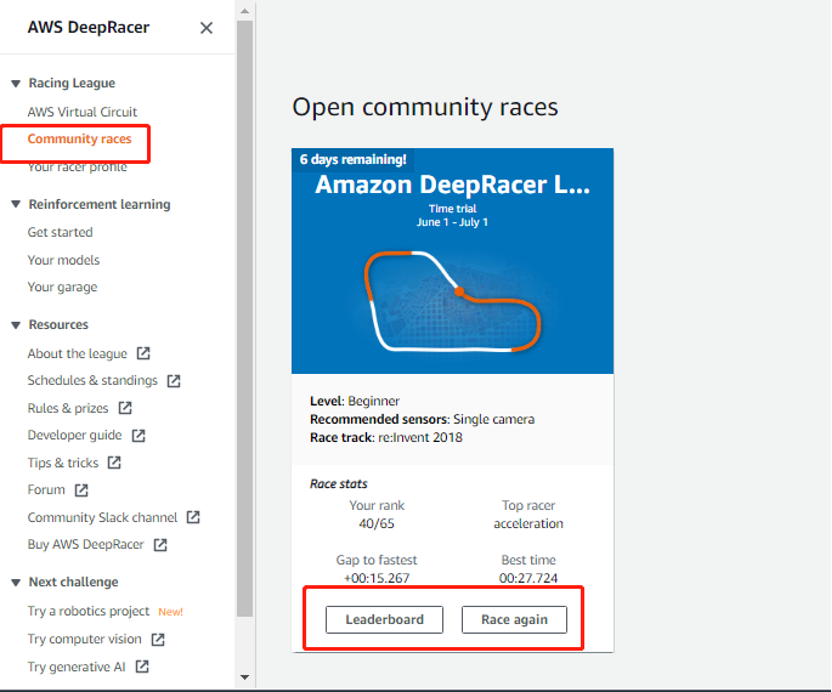
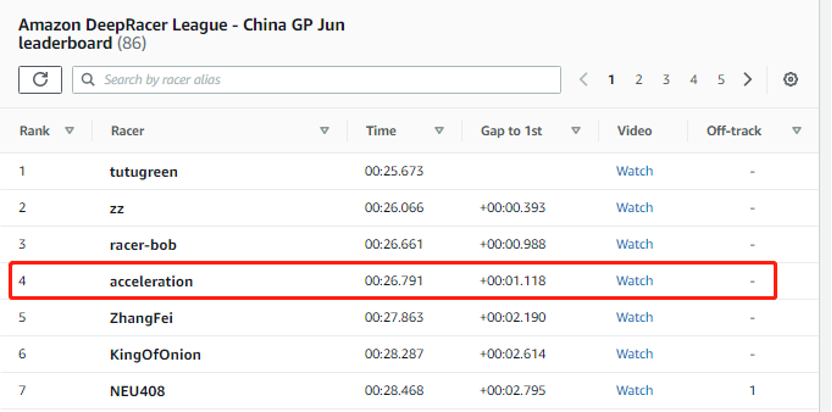
完整的端到端体验一次训练和比赛流程后,剩余的工作就是提高模型的质量,需要多次重复以上创建、训练、和提交模型的过程。通过不断尝试不同的奖励函数、算法及超参、赛车参数的组合,持续进行优化,直到训练出最优模型。经过不断优化,我们战队最终取得在86个队伍中排名第四的成绩。
四、峰会现场巅峰对决
DeepRacer线上赛于6月30日收官,线上成绩前十的队伍,可以得到7月22日亚马逊云科技上海SUMMIT峰会现场与其他高手对决的机会。
上海SUMMIT峰会DeepRacer现场赛,共有两轮:排位赛和排位决赛。其中,现场所有队伍均可参加排位赛,抽签决定上场顺序,在5分钟内进行赛道3圈计时赛,最终成绩前三的队伍晋级下一轮的排位决赛。排位决赛赛制和排位赛赛制相同,按照最终计时结果决出冠军、亚军、季军。
7月20日,我们提前到达上海峰会DeepRacer比赛现场,在宽阔的场地中,一眼就望到两个已搭好的“re:Invent 2018”真实赛道,和线上虚拟赛道完全一样,在现场见到备感亲切。穿上亚马逊云科技现场人员专门准备的赛车服,俨然F1赛场上真实的赛车手,心潮澎湃。

现场拿到实体赛车后,大家的第一印象都是:萌。前脸中间的眼睛内部藏的是一个摄像头,圆润的车身内部包括:电源、动力系统及由CPU、内存、存储组成的一个计算单元等硬件。线上训练的强化模型,实际就是加载到该计算单元。在赛车运行过程中,摄像头获取实时赛道图像,经过强化模型处理后,实时控制赛车在真实赛道上前进或转向。

虽然有着萌萌的外表,想控制它并非像控制线上赛车那么容易,我们在真实赛道上调试发现,线上成绩优异的模型,在真实赛场中并不一定表现良好。在实际赛场中,除了模型因素外,还受到赛场和实体赛车其他因素的影响,包括:赛场光线、赛车电量、赛车初始速度,赛车转向角度、赛车停止速度等参数。
现场比赛的氛围是线上赛无法体会的,现场观众的每一次欢呼,对于参赛者来说,都是一种鼓励。

经过激烈角逐,我们战队的赛车在本次DeepRacer大奖赛上海站的排位赛中以19.20秒的成绩排名第一,在排位决赛中,以22.71秒的成绩排名第二。感谢亚马逊云科技为我们提供此次线下参赛的机会。


五、DeepRacer体验总结
随着线上和线下整个赛程的结束,在此分享一下我们参与整个Deepracer比赛过程中的一些体会。
1、 亚马逊云科技的DeepRacer大大降低了强化学习的门槛,让AI的上手学习变得更加简单,系统会自动创建训练资源,无需手动管理,大大简化了模型训练的管理工作。
2、 同一个奖励函数下,训练时间过长和过短都无助于提高模型质量,训练时长与Learning rate相关。
3、 在训练过程中,优秀的模型的平均奖励分值(Average reward (Training))的正常趋势是逐渐向上的,如果分值在训练过程中随机跳跃,可能需要调整奖励函数规则。
4、 如果想对赛车进行精细化管理,可以通过数学方式计算出赛道的最优路径,并基于最优路径控制赛车速度及转向角度。
5、 在线上表现优异的模型,在真实赛场中并不一定同样表现优秀。需要在实际赛场中找到实体赛车与模型的最佳组合。
发挥你的想象,优化你的模型,挥洒你的汗水,奔跑吧,DeepRacers!8月北京见!
作者:赵毅鹏、成希才、沈磊

 浙公网安备 33010602011771号
浙公网安备 33010602011771号