
分类算法之k-近邻算法(KNN)
一、k-近邻算法概述
1、什么是k-近邻算法
如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
2、欧式距离
两个样本的距离可以通过如下公式计算,又叫欧式距离。比方说计算a(a1,a2,a3),b(b1,b2,b3)样本之间的距离:
\[\sqrt {{{\left( {{a_1} - {b_1}} \right)}^2} + {{({a_2} - {b_2})}^2} + ({a_3} - {b_3})} \]
3、实例
我们可以根据一部电影中的某些特征来判断该电影属于什么类别:

我们可以计算未知电影与已知电影的欧式距离,从而判断类别:
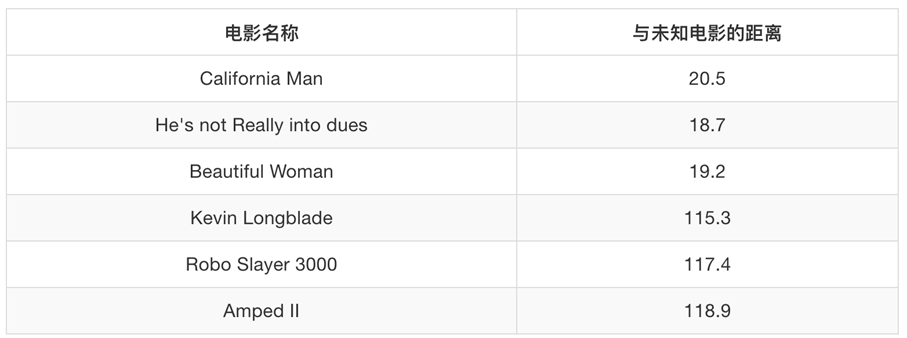
按照欧式距离的计算公式计算,比如:
\[\sqrt {{{\left( {18 - 3} \right)}^2} + {{(90 - 104)}^2}} = 20.5\]
根据距离的远近,从而判断未知样本与哪个类别更近,就可以判断未知样本的类别。
二、案例
(一)k-近邻算法API
1、sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,algorithm='auto')
- n_neighbors:int,可选(默认= 5),k_neighbors查询默认使用的邻居数
- algorithm:{‘auto’,‘ball_tree’,‘kd_tree’,‘brute’},可选用于计算最近邻居的算法。‘ball_tree’将会使用 BallTree;‘kd_tree’将使用 KDTree;‘auto’将尝试根据传递给fit方法的值来决定最合适的算法。 (不同实现方式影响效率)
(二)k-近邻算法实例(预测入住位置)
1、实例说明
可进入https://www.kaggle.com/c/facebook-v-predicting-check-ins/data查看详情,Facebook创建了一个人工世界,由10万乘10公里的正方形中的100,000多个地方组成。对于给定的一组坐标,您的任务是返回最可能的位置的排名列表。
文件说明:
- train.csv,test.csv
row_id:签到事件的ID
xy:坐标
精度:位置精度
时间:时间戳
place_id:入住位置ID,这是您要预测的目标
其数据形式如下:
row_id x y accuracy time place_id 0 0 0.7941 9.0809 54 470702 8523065625 1 1 5.9567 4.7968 13 186555 1757726713 2 2 8.3078 7.0407 74 322648 1137537235 3 3 7.3665 2.5165 65 704587 6567393236 4 4 4.0961 1.1307 31 472130 7440663949 5 5 3.8099 1.9586 75 178065 6289802927 6 6 6.3336 4.3720 13 666829 9931249544 7 7 5.7409 6.7697 85 369002 5662813655 8 8 4.3114 6.9410 3 166384 8471780938 9 9 6.3414 0.0758 65 400060 1253803156 ...
2、实例解析
显然,xy坐标、位置精度、时间戳是特征值,入住位置是目标值;那么这就是一个分类问题。这个数据量是比较大的,我们可以对其进行如下处理:
- 缩小数据范围(0<x<2,0<y<2)
- 将时间戳转换成年、月、日、时等新的特征
- 删除少于指定位置的签到人数位置删除
然后,再进行特征选取与目标值选取,以及做下面的操作。
3、实现
import pandas as pd from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.neighbors import KNeighborsClassifier import numpy as np def knn(): """ 近邻算法:预测入住位置 :return: """ # 读取训练集数据 df = pd.read_csv("./data/k-近邻算法数据/train.csv") # 读取前5行数据 # print(df.head(5)) """ 一、进行数据处理: 1、缩小数据范围 2、时间戳处理 3、删除少于指定位置的签到人数位置删除 """ # 1、缩小数据范围 df = df.query("x>0 & x<1.2 & y>0 & y<1.23") # 2、时间戳处理 df_time = pd.to_datetime(df["time"], unit='s') #把日期格式处理成字典格式 time_dict = pd.DatetimeIndex(df_time) # 构造时间特征 df["day"] = time_dict.day df["hour"] = time_dict.hour df["weekday"] = time_dict.weekday # 删除时间戳这一列 df = df.drop(['time'], axis=1) # 3、删除少于指定位置的签到人数位置删除 place_count = df.groupby('place_id').count() # 过滤出少于指定位置的签到人数位置,通过reset_index将索引转成列进行操作 pf = place_count[place_count["row_id"] > 3].reset_index() # 根据指定place_id进行过滤 df = df[df['place_id'].isin(pf['place_id'])] """ 二、获取特征值、目标值 """ # 1、获取特征值 x = df.drop(['place_id'], axis=1) # 2、获取目标值 y = df['place_id'] """ 三、进行数据集分割,分成训练集和测试集 """ x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25)
""" 四、特征工程:标准化 """ sd = StandardScaler() # 对训练集进行标准化 x_train = sd.fit_transform(x_train.astype(np.float64)) # 对测试集进行标准化 x_test = sd.transform(x_test.astype(np.float64))
""" 五、进行KNN算法预测 fit predict score """ knn = KNeighborsClassifier(n_neighbors=5) knn.fit(x_train, y_train) # 预测位置 y_predict = knn.predict(x_test) # print('预测的位置:',y_predict) # 准确率 predict_accurate = knn.score(x_test, y_test) print(predict_accurate) if __name__ == '__main__': knn()


import pandas as pd from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.neighbors import KNeighborsClassifier import numpy as np def knn(): """ 近邻算法:预测入住位置 :return: """ # 读取训练集数据 df = pd.read_csv("./data/k-近邻算法数据/train.csv") # 读取前5行数据 # print(df.head(5)) """ 进行数据处理: 1、缩小数据范围 2、时间戳处理 3、删除少于指定位置的签到人数位置删除 """ # 1、缩小数据范围 df = df.query("x>0 & x<1.2 & y>0 & y<1.23") # # 2、时间戳处理 df_time = pd.to_datetime(df["time"], unit='s') # print(df_time) """ 132 1970-01-08 19:14:45 142 1970-01-02 00:41:22 ... """ # #把日期格式处理成字典格式 time_dict = pd.DatetimeIndex(df_time) # print(time_dict) """ DatetimeIndex( ['1970-01-08 19:14:45', '1970-01-02 00:41:22', '1970-01-07 06:32:23', '1970-01-02 18:59:24',...], dtype='datetime64[ns]', name='time', length=417477, freq=None ) """ # 构造时间特征 df["day"] = time_dict.day df["hour"] = time_dict.hour df["weekday"] = time_dict.weekday # 删除时间戳这一列 df = df.drop(['time'], axis=1) # print(df) """ row_id x y ... day hour weekday 132 132 0.1902 0.1510 ... 8 19 3 142 142 0.1318 0.4975 ... 2 0 4 149 149 0.0179 0.2321 ... 7 6 2 ... """ # 3、删除少于指定位置的签到人数位置删除 place_count = df.groupby('place_id').count() # print(place_count) """ row_id x y accuracy day hour weekday place_id 1000213704 22 22 22 22 22 22 22 1000842315 6 6 6 6 6 6 6 1002574526 1 1 1 1 1 1 1 1002803051 1 1 1 1 1 1 1 ... """ # 过滤出少于指定位置的签到人数位置,通过reset_index将索引转成列进行操作 pf = place_count[place_count["row_id"] > 3].reset_index() # print(pf) """ place_id row_id x y accuracy day hour weekday 0 1000213704 22 22 22 22 22 22 22 1 1000842315 6 6 6 6 6 6 6 ... """ # 根据指定place_id进行过滤 df = df[df['place_id'].isin(pf['place_id'])] # print(df) """ 获取特征值、目标值 """ # 1、获取特征值 x = df.drop(['place_id'], axis=1) # 2、获取目标值 y = df['place_id'] """ 进行数据集分割,分成训练集和测试集 """ x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25) """ 特征工程:标准化 """ sd = StandardScaler() # 对训练集进行标准化 x_train = sd.fit_transform(x_train.astype(np.float64)) # 对测试集进行标准化 x_test = sd.transform(x_test.astype(np.float64)) """ 进行KNN算法预测 fit predict score """ knn = KNeighborsClassifier(n_neighbors=5) knn.fit(x_train, y_train) # 预测位置 y_predict = knn.predict(x_test) # print('预测的位置:',y_predict) """ [2013736336 4137191191 5861856288 ... 4223174852 8114087113 7163230644] """ # 准确率 predict_accurate = knn.score(x_test, y_test) print(predict_accurate) if __name__ == '__main__': knn()
可以看出,上面的实现的大致步骤是:获取数据与处理数据-->获取特征值与目标值-->进行数据集切割-->特征工程(标准化、降维等)-->算法预测
三、k-近邻算法的优缺点
1、优点
k-近邻算法的优点很明显,那就是简单、易于理解、易于计算。
2、缺点
- 内存开销大
可以看到,计算两个样本的欧式距离,如果样本数量较大,这样系统的开销比较大。
- k值的选择需慎重
k值在上面的实例过程中体现在KNeighborsClassifier方法的n_neighbors参数,如果这个参数过小,易受到异常点的影响;如果参数过大,那么容易受k值数量的波动。

