
转换器与预估器
一、转换器
在之前我们对数据做标准化或者其它的特征工程处理时使用了fit_transform方法,它是输入数据并且对数据进行转换;与之对应的就是fit方法与transform方法,实际上这两个方法相当于一个fit_transform方法。
In [1]: from sklearn.preprocessing import StandardScaler In [2]: data = [[1,2,3],[4,5,6]] In [3]: sd = StandardScaler() In [4]: sd.fit_transform(data) Out[4]: array([[-1., -1., -1.], [ 1., 1., 1.]])
如果,使用fit和transform来实现这个过程是这样的:
In [1]: from sklearn.preprocessing import StandardScaler In [2]: data = [[1,2,3],[4,5,6]] In [3]: ssd.fit(data) Out[3]: StandardScaler(copy=True, with_mean=True, with_std=True) In [4]: ssd.transform(data) Out[4]: array([[-1., -1., -1.], [ 1., 1., 1.]]) In [5]:
可以看到两个结果是相同的。
但是需要注意的是fit是做什么的呢?当你将数据通过fit函数进行输入时,是进行标准的指定,比如下面:
In [12]: ssd.fit([[8,9,0],[6,7,8]]) #制定标准 Out[12]: StandardScaler(copy=True, with_mean=True, with_std=True) In [13]: ssd.transform(data) Out[13]: array([[-6. , -6. , -0.25], [-3. , -3. , 0.5 ]]) In [14]:
可以看到fit中传入的数组不是data了,而是其它的数组,那么最后以当前的标准来对data进行标准化,就和以前不一样了。
所以,我们使用转换器进行特征工程时注意如果使用fit_transform时,不会出现上面的情况,但是如果两个函数分开使用就要注意,第一次fit后,后面进行transform的数据不要重复调用fit函数。从而保持标准的一致性。
二、预估器
在sklearn中,估计器(estimator)是一个重要的角色,分类器和回归器都属于estimator,是一类实现了算法的API。
1、分类估计器
- sklearn.neighbors k-近邻算法
- sklearn.naive_bayes 贝叶斯
- sklearn.linear_model.LogisticRegression 逻辑回归
2、回归估计器
- sklearn.linear_model.LinearRegression 线性回归
- sklearn.linear_model.Ridge 岭回归
3、工作流程
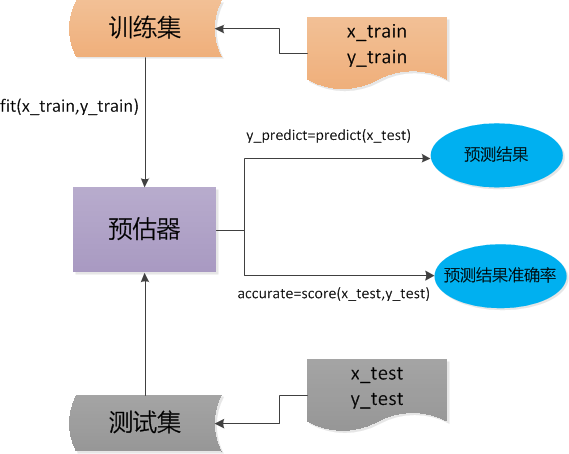
(1)数据集分为训练集和测试集
(2)调用fit方法,将训练集数据进行输入
(3)输入测试集数据
(4)测试集数据结果的预测与准确率的预测
作者:iveBoy
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须在文章页面给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号