
降维案例
一、数据集介绍
该案例描述的是一段时间内客户的订单,预测用户下一次将会买那些订单。
数据集的信息如下:
- products.csv 商品信息
- order_products__prior.csv 订单与商品关系信息
- orders.csv 订单信息
- aisles.csv 商品所属的具体类别
1、 products.csv
import pandas as pd product_df = pd.read_csv(r'I:\machine_learn\example_\products.csv') product_df.head(10)
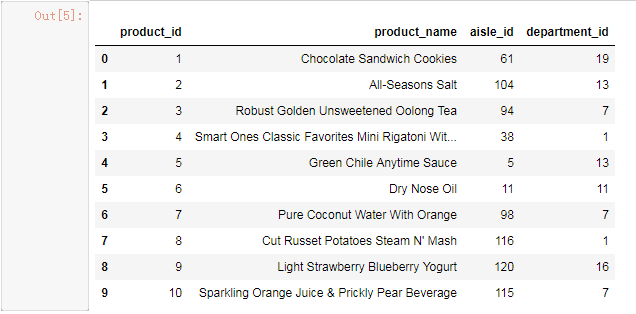
该文件是产品数据,里面的字段有product_id(产品ID),product_name(产品名称),aisle_id(产品类型)等。
2、order_products__prior.csv
order_products__prior_df = pd.read_csv(r'I:\machine_learn\example_\order_products__prior.csv') order_products__prior_df.head(10)
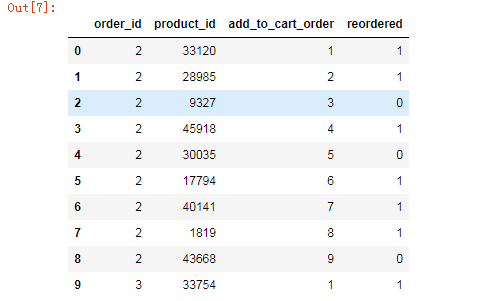
该文件是产品和订单数据,里面的字段有product_id(产品ID),order_id(订单ID)等。
3、orders.csv
orders_df = pd.read_csv(r'I:\machine_learn\example_\orders.csv') orders_df .head(10)
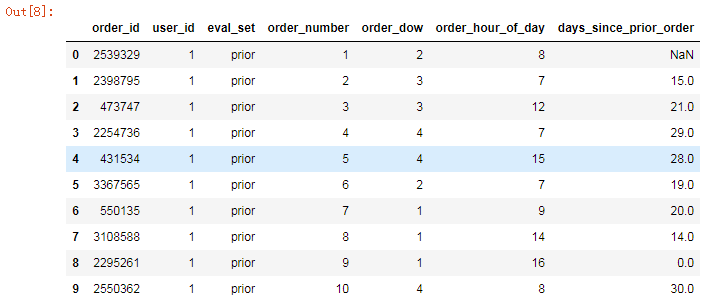
该文件是订单数据,里面的字段有user_id(用户ID),order_id(订单ID)等。
4、aisles.csv
aisles_df = pd.read_csv(r'I:\machine_learn\example_\aisles.csv') aisles_df .head(10)
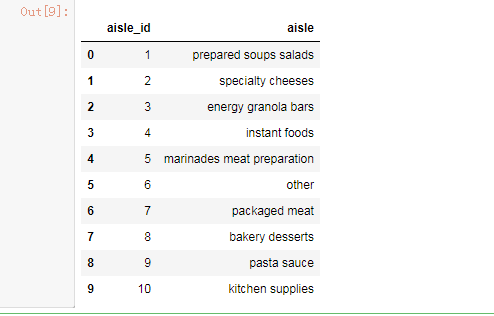
该文件是产品类型数据,里面的字段有aisle_id(产品数据类型ID),aisle(产品类型名称)。
二、预测
现在探究的是用户和物品类型的关系:

1、读取四张表
import pandas as pd from sklearn.depositions import PCA product_df = pd.read_csv(r'I:\machine_learn\example_\products.csv') order_products__prior_df = pd.read_csv(r'I:\machine_learn\example_\order_products__prior.csv') orders_df = pd.read_csv(r'I:\machine_learn\example_\orders.csv') aisles_df = pd.read_csv(r'I:\machine_learn\example_\aisles.csv')
2、合并四张表
_mg = pd.merge(order_products__prior_df,product_df,on=['product_id','product_id']) _mg = pd.merge(_mg,orders_df,on=['order_id','order_id']) _ma = pd.merge(_mg,aisles_df,on=['aisle_id','aisle_id']) _ma.head(10) #输出
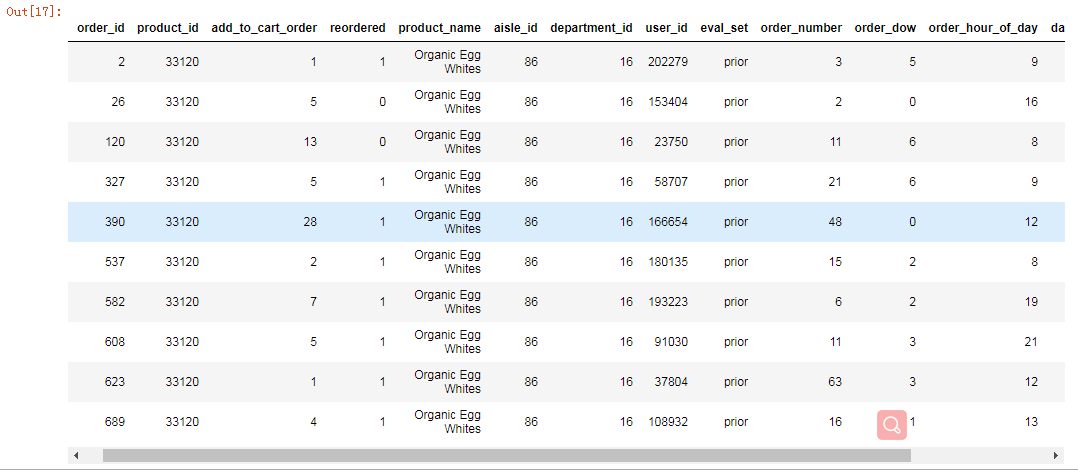
上面就是用户(user_id)与产品类型(aisle)的关系,但是现在需要统计的每一个用户的产品类型,所以用到交叉表(特殊的分组表)。可以查出每一个用户aisle(产品类型)的个数。
crossTab_df = pd.crosstab(_ma["user_id"],_ma["aisle"])
crossTab_df #输出
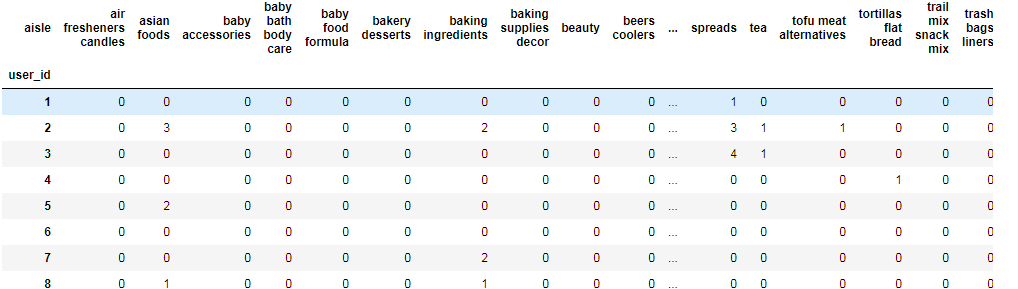
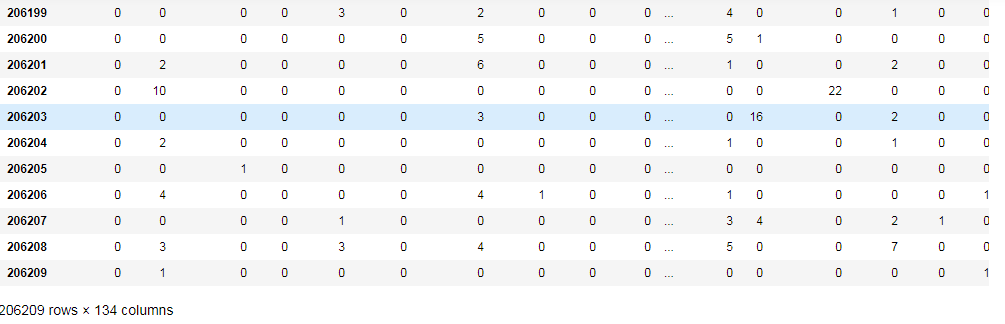
3、主成分分析
pca = PCA(n_components=0.9) data = pca.fit_transform(crossTab_df) data #输出

可以看看输出的行列:
data.shape """ (206209, 27) """
作者:iveBoy
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须在文章页面给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号