
Docker Swarm之RoutingMesh
一、集群之间的网络
之前有搭建过wordpress应用,其中wordpress运行在manager节点上,mysql服务运行在worker节点上,它们之间的运行时都制定了对应的网络overlay,但是当时只是在manager节点上创建了这个overlay网络,worker节点上并没有创建,但是当Swarm集群的manager节点启动了mysql服务并且运行在worker节点上后,worker节点上竟然也有了这个overlay网络,这是为什么呢?
这就涉及到了Swarm的网络RoutingMesh,它有两种体现的方式分别是:Internal和Ingress,其中Internal的通信通过overlay网络;Ingress是如果服务有绑定接口,则此服务可以通过任意Swarm节点的相应接口进行访问。
二、 Internal
1、创建overlay网络
首先先在Swarm的集群中创建一个overlay的network:
[root@centos-7 ~]# docker network create -d overlay demo
然后查看:
[root@centos-7 ~]# docker network ls NETWORK ID NAME DRIVER SCOPE ... xcjljjqcw26b demo overlay swarm ...
2、启动服务
在这个manager节点上利用demo这个网络启动一个服务
[root@centos-7 ~]# docker service create --name whoami -p 8000:8000 --network demo -d jwilder/whoami g0vvgklakfoqsjvy0fd1zefjo [root@centos-7 ~]# docker service ls ID NAME MODE REPLICAS IMAGE PORTS g0vvgklakfoq whoami replicated 0/1 jwilder/whoami:latest *:8000->8000/tcp [root@centos-7 ~]# docker service ps whoami ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS pk15budjscr7 whoami.1 jwilder/whoami:latest centos-7 Running Preparing about a minute ago
当我们启动这个服务后,可以尝试去访问它:
[root@centos-7 ~]# curl 127.0.0.1:8000 I'm 9842878ab31b
另外,我们再开启一个服务:
[root@centos-7 ~]# docker service create --name test -d --network demo busybox /bin/sh -c "while true;do slepp 3600;done"
注意,此时我们这个服务是在worker节点节点上运行的。
[root@centos-7 ~]# docker service ls ID NAME MODE REPLICAS IMAGE PORTS rqdbc7dtdh77 test replicated 1/1 busybox:latest g0vvgklakfoq whoami replicated 1/1 jwilder/whoami:latest *:8000->8000/tcp [root@centos-7 ~]# docker service ps test ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS 0wqwt54vbiue test.1 busybox:latest localhost.localdomain Running Running 3 minutes ago
3、不同节点上服务之间的通信
如果此时进入到worker节点的test服务容器中,去和manager节点上whoami服务的容器通信们是否可行呢?
- 进入test服务的容器中
[root@localhost _data]# docker exec -it d161e7c46a8c /bin/sh / # ping whoami PING whoami (10.0.1.33): 56 data bytes 64 bytes from 10.0.1.33: seq=0 ttl=64 time=33.921 ms 64 bytes from 10.0.1.33: seq=1 ttl=64 time=0.088 ms
可以看到,这是可行的,并且返回的地址是10.0.1.33,这是不是就说明了manager节点服务容器的ip是这个呢?我们查看一下。
- 进入whoami服务容器中
[root@centos-7 ~]# docker exec -it 9842878ab31b /bin/sh /app # ip a 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever 266: eth1@if267: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1450 qdisc noqueue state UP link/ether 02:42:0a:00:00:15 brd ff:ff:ff:ff:ff:ff inet 10.0.0.21/24 brd 10.0.0.255 scope global eth1 valid_lft forever preferred_lft forever 268: eth2@if269: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue state UP link/ether 02:42:ac:12:00:03 brd ff:ff:ff:ff:ff:ff inet 172.18.0.3/16 brd 172.18.255.255 scope global eth2 valid_lft forever preferred_lft forever 270: eth0@if271: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1450 qdisc noqueue state UP link/ether 02:42:0a:00:01:22 brd ff:ff:ff:ff:ff:ff inet 10.0.1.34/24 brd 10.0.1.255 scope global eth0 valid_lft forever preferred_lft forever
显然这里面并没有10.0.1.33,这是怎么回事呢?我们知道scale参数可以将容器水平扩展,不同的容器都有一个ip,为了保证这些服务的ip不变,这里使用了虚拟的ip,这个ip地址是不会改变的,比如现在利用scale多创建几个whoami服务的容器,然后再进行通信。
- 创建多个whoami服务的容器
[root@centos-7 ~]# docker service scale whoami=3 whoami scaled to 3 overall progress: 3 out of 3 tasks 1/3: running [==================================================>] 2/3: running [==================================================>] 3/3: running [==================================================>] verify: Service converged
- 再次测试
再在worker节点的test服务容器中进行测试:
[root@localhost ~]# docker exec -it 638b /bin/sh / # ping whoami PING whoami (10.0.1.33): 56 data bytes 64 bytes from 10.0.1.33: seq=0 ttl=64 time=49.712 ms 64 bytes from 10.0.1.33: seq=1 ttl=64 time=0.072 ms 64 bytes from 10.0.1.33: seq=2 ttl=64 time=0.072 ms
可以看到虽然whoami服务已经启动了3个容器,但是这个虚拟的ip还是没有变化,那么怎么查看这个虚拟ip对应的真实ip呢?可以通过以下命令查看:
[root@localhost ~]# docker exec -it 638b /bin/sh / # nslookup whoami Server: 127.0.0.11 Address: 127.0.0.11:53 / # nslookup tasks.whoami
我们也可以这样去验证,只需要在本地上去访问这个服务,看它返回的主机信息:
[root@localhost ~]# curl 127.0.0.1:8000 I'm 6f5862805bcf [root@localhost ~]# curl 127.0.0.1:8000 I'm d274e2b20fd8 [root@localhost ~]# curl 127.0.0.1:8000 I'm 9842878ab31b [root@localhost ~]# curl 127.0.0.1:8000 I'm 6f5862805bcf
这就是借助overlay网络实现的Swarm集群容器之间通信的模式。
4、总结
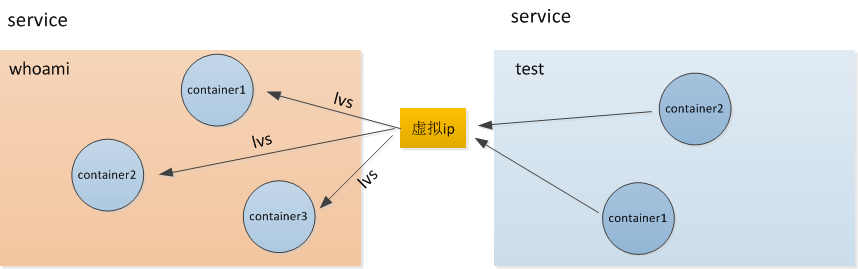
两个服务whoami和test之间是建立了虚拟的ip进行联系,但是一个虚拟的ip可能就对应一个服务中多个容器的ip,它们之间是通过lvs(Linux Virtual Server)技术来实现的,从而达到负载均衡的效果。
三、Ingress
1、什么是Ingress?
在Swarm集群中可能同一个service部署在不同的节点上,那么如果Swarm中有的节点没有 这个service,是否这个节点就不能访问这个服务呢?
现在先启动两个服务:
[root@centos-7 ~]# docker service create --name whoami -p 8000:8000 --network demo -d jwilder/whoami n9i8qe8obf5ke73ptbuejl49o [root@centos-7 ~]# docker service scale whoami=2 whoami scaled to 2 overall progress: 2 out of 2 tasks 1/2: running [==================================================>] 2/2: running [==================================================>] verify: Service converged
再看看这两个启动在节点上:
[root@centos-7 ~]# docker service ls ID NAME MODE REPLICAS IMAGE PORTS n9i8qe8obf5k whoami replicated 2/2 jwilder/whoami:latest *:8000->8000/tcp [root@centos-7 ~]# docker service ps whoami ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS jb4sodzzwoke whoami.1 jwilder/whoami:latest centos-7 Running Running 49 seconds ago ajnie812nqsg whoami.2 jwilder/whoami:latest localhost.localdomain Running Running 20 seconds ago
可以看到两个服务启动在不同的节点上,一个在manager节点(centos-7),一个在worker节点(localhost.localdomain),我们现在manager节点上访问:
[root@centos-7 ~]# curl 127.0.0.1:8000 I'm ae433c63efaf [root@centos-7 ~]# curl 127.0.0.1:8000 I'm d20d6ad9f7ae
可以看到manager节点上竟然两个都能访问,不是另一个部署在worker节点上了吗?那么再去worker节点上测试:
[root@localhost ~]# curl 127.0.0.1:8000 I'm ae433c63efaf [root@localhost ~]# curl 127.0.0.1:8000 I'm d20d6ad9f7ae
竟然也是一样的,这就是Swarm中的Ingress网络,它可以将服务端口暴露在Swarm中的各个节点上。
2、Ingress的实现
- 转发规则
我们可以看看worker节点上没有存在的服务它是怎么访问的,如果访问它内部是怎么转发的。
[root@localhost ~]# iptables -nL -t nat ... Chain DOCKER-INGRESS (2 references) target prot opt source destination DNAT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:8000 to:172.20.0.2:8000 RETURN all -- 0.0.0.0/0 0.0.0.0/0 ...
我们可以看到如果不存在的就会转发到172.20.0.2::8000这个这个地址上去,那么我们看看它自己的ip:
[root@localhost ~]# ip a ... 12: docker_gwbridge: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP link/ether 02:42:ab:b2:f4:f0 brd ff:ff:ff:ff:ff:ff inet 172.20.0.1/16 brd 172.20.255.255 scope global docker_gwbridge valid_lft forever preferred_lft forever inet6 fe80::42:abff:feb2:f4f0/64 scope link valid_lft forever preferred_lft forever ...
我们没有找到那个地址,但是找到了docker_gwbridge,可以看到两个ip处于同一段,那么172.20.0.2应该也连接上docker_gwbridge:
[root@localhost ~]# brctl show bridge name bridge id STP enabled interfaces br-2d6d1e198a6c 8000.0242deeae757 no br-8abcc5cd875c 8000.02424eb653eb no docker0 8000.02424a3fbec6 no docker_gwbridge 8000.0242abb2f4f0 no
veth1b22ec2 veth6839368 virbr0 8000.525400dec34c yes virbr0-nic
可以看到它有两个interface,但是哪一个才是 172.20.0.0使用的呢?那么我们现在可以从这个网络连接的容器着手。
[root@localhost ~]# docker network inspect docker_gwbridge [ ... "Containers": { "ae433c63efafd9376ff82699d127563e780ae73caebcb604c3b0966000236e79": { "Name": "gateway_fe0a7f060fb9", "EndpointID": "6eddc5ac0721d319e11eb475c3f937ccf78713ed56f89fef563c13333d2526b4", "MacAddress": "02:42:ac:14:00:03", "IPv4Address": "172.20.0.3/16", "IPv6Address": "" }, "ingress-sbox": { "Name": "gateway_ingress-sbox", "EndpointID": "08639c027efb5c9e51aaf742587c9ae944d1d82275f92ef4f2d1f77965194656", "MacAddress": "02:42:ac:14:00:02", "IPv4Address": "172.20.0.2/16", "IPv6Address": "" } } ... ]
可以看到它有两个容器,其中ingress-sbox容器的ip就是我们需要寻找的。它是什么呢?它是一个Network Namespace,那么也就是请求本转发到这里面来了。
- 进入ingress-sbox
我们可以先查看docker中所有的Network Namespace:
[root@localhost ~]# ls /var/run/docker/netns 1-lg0vf65qxp 1-xcjljjqcw2 fe0a7f060fb9 ingress_sbox lb_xcjljjqcw
然后通过下面的命令进入:
[root@localhost ~]# nsenter --net=/var/run/docker/netns/ingress_sbox
查看ip:
[root@localhost ~]# ip a 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever 10: eth0@if11: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP link/ether 02:42:0a:00:00:03 brd ff:ff:ff:ff:ff:ff link-netnsid 0 inet 10.0.0.3/24 brd 10.0.0.255 scope global eth0 valid_lft forever preferred_lft forever inet 10.0.0.26/32 brd 10.0.0.26 scope global eth0 valid_lft forever preferred_lft forever 13: eth1@if14: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP link/ether 02:42:ac:14:00:02 brd ff:ff:ff:ff:ff:ff link-netnsid 1 inet 172.20.0.2/16 brd 172.20.255.255 scope global eth1 valid_lft forever preferred_lft forever
这个名称空间中的ip就是我们要找的。
当被转发到这个名称空间后它又是怎么做的呢?我们先看看它的转发规则:
root@localhost ~]# iptables -nL -t mangle Chain PREROUTING (policy ACCEPT) target prot opt source destination MARK tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:8000 MARK set 0x10b Chain INPUT (policy ACCEPT) target prot opt source destination MARK all -- 0.0.0.0/0 10.0.0.26 MARK set 0x10b Chain FORWARD (policy ACCEPT) target prot opt source destination Chain OUTPUT (policy ACCEPT) target prot opt source destination Chain POSTROUTING (policy ACCEPT) target prot opt source destination
可以看到红色的部分,当转发8000端口时MARK set 0x10b,接下来执行如下的命令:
[root@localhost ~]# ipvsadm -l IP Virtual Server version 1.2.1 (size=4096) Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConn FWM 271 rr -> 10.0.0.27:0 Masq 1 0 0 -> 10.0.0.28:0 Masq 1 0 0
实际上在这个名称空间中也是讲这个端口进行了转发,转发到了上面红色字体的地址和8000端口,那这两个地址是什么呢?其实就是Swarm中的所有节点的8000端口,这也就是Ingress的作用了。
3、总结

当我们访问访问本地8000端口时,只要我们这个节点处于Swarm集群中,不管服务部署到那个节点都能访问,只要端口相同即可。我们本地的请求会被转发到Ingress_sbox这个Network Namespace中,在这个名称空间中再通过lvs转发到具体服务容器的ip和8000端口中去。

