
Pandas的使用
一、Pandas基础
Pandas是基于NumPy的一套数据分析工具,该工具是为了解决数据分析任务而创建的,所以它至少有以下特点或用途:
- 基于NumPy,提供了矩阵运算
- 强大的分析结构化数据的工具集
- 提供数据清洗功能
(一)数据结构
1、Series
是带标签的一维数组,可存储整数、浮点数、字符串、Python 对象等类型的数据。轴标签统称为索引。调用 pd.Series 函数即可创建 Series,所以它有以下特点:
- 类似一维数组的对象
- 可通过list或者dict构建Series
- 由数据和索引组成(索引在左,数据在右;索引是自动创建的)
#通过list创建Series数据核结构 >>> ser_obj = pd.Series(range(5)) >>> type(ser_obj) <class 'pandas.core.series.Series'> >>> ser_obj 0 0 1 1 2 2 3 3 4 4 dtype: int64 >>> pd.Series([0,1,2,3,4]) 0 0 1 1 2 2 3 3 4 4 dtype: int64 #通过values和index方法获取数据和索引 >>> ser_obj.index RangeIndex(start=0, stop=5, step=1) #获取索引对象,可通过迭代获取每一个值 >>> index_obj = ser_obj.index >>> index_obj[0] 0 >>> values_obj = ser_obj.values >>> values_obj array([0, 1, 2, 3, 4], dtype=int64) #获取值组成的数组 >>> #通过head方法预览数据 >>> ser_obj.head() #所有数据 0 0 1 1 2 2 3 3 4 4 dtype: int64 >>> ser_obj.head(2) #前两行 0 0 1 1 #通过索引获取数据 >>> ser_obj[1] 1 >>> #通过字典构建Series >>> ser_obj = pd.Series({'a':1,'b':2}) >>> ser_obj a 1 b 2 #Series支持name属性 >>> ser_obj = pd.Series(np.random.randn(5),name='he') >>> ser_obj.name 'he'
2、DataFrame
DataFrame 是由多种类型的列构成的二维标签数据结构,类似于 Excel 、SQL 表,或 Series 对象构成的字典。DataFrame 是最常用的 Pandas 对象,与 Series 一样,DataFrame 支持多种类型的输入数据:
- 一维 ndarray、列表、字典、Series 字典
- 二维 numpy.ndarray
- SeriesDataFrame
所以,总的来说它具有以下特点:
- 类似多维数组/表格数据
- 每列数据可以是不同的类型
- 索引包括列索引和行索引
DataFrame 的构建:
#通过ndarray构建DataFrame >>> array = np.arange(12).reshape(3,4) >>> array array([[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]]) >>> df_obj = pd.DataFrame(array) >>> df_obj.head() 0 1 2 3 0 0 1 2 3 1 4 5 6 7 #通过字典构建DataFrame >>> d = {'one':[1,2,3],'two':[4,5,6]} >>> df = pd.DataFrame(d) >>> df one two 0 1 4 1 2 5 2 3 6 >>> >>> d = {'one':[1,2,3],'two':[4,5,6]} >>> df = pd.DataFrame(d,index=['a','b','c']) >>> df one two a 1 4 b 2 5 c 3 6 >>> #通过Series构建DataFrame >>> d = {'one':pd.Series([1,2,3],index=['a','b','c']),'two':pd.Series([4,5,6],in dex=['a','b','c'])} >>> df = pd.DataFrame(d) >>> df one two a 1 4 b 2 5 c 3 6 >>>
操作DataFrame中的数据:
#通过列索引获取列数据(Series类型 ),df[col_idx] 或 df.col_idx >>> d = {'one':[1,2,3],'two':[4,5,6]} >>> df = pd.DataFrame(d) >>> df one two 0 1 4 1 2 5 2 3 6 >>> df['one'] 0 1 1 2 2 3 Name: one, dtype: int64 >>> type(df['one']) <class 'pandas.core.series.Series'> #增加列数据,类似dict添加key-value,df[new_col_idx] = data >>> df['three'] = [7,8,9] >>> df one two three 0 1 4 7 1 2 5 8 2 3 6 9 #删除列 del df[col_idx] >>> del df['three'] >>> df one two 0 1 4 1 2 5 2 3 6 >>>
索引对象Index:
#构建DataFrame >>> d = {'one':[1,2,3],'two':[4,5,6]} >>> df = pd.DataFrame(d) >>> df one two 0 1 4 1 2 5 2 3 6 #取出索引对象 >>> df.index RangeIndex(start=0, stop=3, step=1) >>> type(df.index) <class 'pandas.core.indexes.range.RangeIndex'> >>>
可以看出Pandas中的索引对象有以下特点:
- Series和DataFrame中的索引都是Index对象
- 不可变(immutable) (保证数据的安全性)
- 常见的Index对象的种类(Index,Int64Index,MultiIndex,DatetimeIndex)
(二)数据操作
1、索引操作
Pandas的索引可归纳为3种,分别为:.loc,标签索引;.iloc,位置索引;.ix,标签与位置混合索引(先按标签索引操作,然后再按位置索引操作)。值得注意的是DataFrame中的索引操作可按照NumPy中的ndarray进行操作。
位置索引不包含末尾的切片索引,但是标签索引包含末尾的切片索引。
-
Series索引操作
>>> import pandas as pd >>> ser_obj = pd.Series(range(5),index=['a','b','c','d','e']) >>> ser_obj.head() a 0 b 1 c 2 d 3 e 4 dtype: int64 #行索引 >>> ser_obj['b'] #标签索引 1 >>> ser_obj[1] #位置索引 1 #切片索引 >>> ser_obj['a':'c'] #标签索引 a 0 b 1 c 2 dtype: int64 >>> ser_obj[0:2] a 0 b 1 dtype: int64 #不连续索引 >>> ser_obj[[0,2]] a 0 c 2 dtype: int64 >>> ser_obj[['a','c']] a 0 c 2 dtype: int64 >>> #布尔索引,按照位置索引,将满足的位置的数据取出 >>> ser_bool = ser_obj > 2 >>> ser_bool a False b False c False d True e True dtype: bool >>> ser_obj[ser_bool] d 3 e 4 dtype: int64 >>>
-
DataFrame索引操作
>>> df_obj = pd.DataFrame(np.random.rand(3,4)) >>> df_obj 0 1 2 3 0 0.083639 0.773814 0.385009 0.067200 1 0.135069 0.286290 0.359994 0.204416 2 0.642119 0.830445 0.908530 0.483679 >>> df_obj = pd.DataFrame(np.random.rand(3,4),columns=['a','b','c','d']) >>> df_obj a b c d 0 0.876338 0.753406 0.098060 0.896880 1 0.245380 0.769202 0.212327 0.296384 2 0.892388 0.739253 0.173457 0.996446 #列索引 >>> df_obj['a'] # 返回Series类型 0 0.876338 1 0.245380 2 0.892388 Name: a, dtype: float64 #不连续列索引 >>> df_obj[['a','c']] a c 0 0.876338 0.098060 1 0.245380 0.212327 2 0.892388 0.173457 >>>
-
三种索引方式
##############1、Series################# >>> ser_obj a 0 b 1 c 2 d 3 e 4 dtype: int64 >>> #(1)标签索引loc >>> ser_obj['b':'d'] b 1 c 2 d 3 dtype: int64 >>> ser_obj.loc['b':'d'] b 1 c 2 d 3 dtype: int64 #(2)位置索引iloc >>> ser_obj[1:3] b 1 c 2 dtype: int64 >>> ser_obj.iloc[1:3] b 1 c 2 dtype: int64 #(3)混合索引ix >>> ser_obj.ix[1:3] b 1 c 2 dtype: int64 >>> ser_obj.ix['b':'c'] b 1 c 2 dtype: int64 ##############2、DataFrame################# >>> df_obj a b c d 0 0.876338 0.753406 0.098060 0.896880 1 0.245380 0.769202 0.212327 0.296384 2 0.892388 0.739253 0.173457 0.996446 >>> #(1)标签索引loc >>> df_obj['a'] 0 0.876338 1 0.245380 2 0.892388 Name: a, dtype: float64 >>> df_obj.loc[0:2,'a'] 0 0.876338 1 0.245380 2 0.892388 Name: a, dtype: float64 >>> #(2)位置索引iloc >>> df_obj.iloc[0:2,0] 0 0.876338 1 0.245380 Name: a, dtype: float64 #(3)混合索引ix >>> df_obj.ix[0:2,0] #先按标签索引尝试操作,然后再按位置索引尝试操作 0 0.876338 1 0.245380 2 0.892388 Name: a, dtype: float64
2、运算与对齐
- 按索引对齐运算,没对齐的位置补NaN(Series 按行索引对齐;DataFrame按行,列索引对齐)
- 填充未对齐的数据进行运算(使用add, sub, div, mul;同时通过fill_value指定填充值)
- 填充NaN(通过fillna进行填充)
###############按照索引对齐运算############ #Series对齐运算 >>> s1 = pd.Series(np.arange(10)) >>> s1 0 0 1 1 2 2 3 3 4 4 5 5 6 6 7 7 8 8 9 9 dtype: int32 >>> s2 = pd.Series(range(5)) >>> s2 0 0 1 1 2 2 3 3 4 4 dtype: int64 >>> s1+s2 #进行求和运算 0 0.0 1 2.0 2 4.0 3 6.0 4 8.0 5 NaN 6 NaN 7 NaN 8 NaN 9 NaN dtype: float64 >>> #DataFrame对齐运算 >>> df1 = pd.DataFrame(np.random.rand(3,2),columns=['a','b']) >>> df1 a b 0 0.312066 0.913311 1 0.562698 0.055995 2 0.917202 0.876010 >>> df2 = pd.DataFrame(np.arange(12).reshape(2,6),columns=['a','b','c','d','e',' f']) >>> df2 a b c d e f 0 0 1 2 3 4 5 1 6 7 8 9 10 11 >>> df1+df2 #进行求和运算 a b c d e f 0 0.010841 1.715210 NaN NaN NaN NaN 1 6.967361 7.151983 NaN NaN NaN NaN 2 NaN NaN NaN NaN NaN NaN >>> ###############填充未对齐的数据进行运算## ###Series运算 >>> s1 0 0 1 1 2 2 3 3 4 4 5 5 6 6 7 7 8 8 9 9 dtype: int32 >>> s2 0 0 1 1 2 2 3 3 4 4 dtype: int64 >>> s1.add(s2,fill_value=1) 0 0.0 1 2.0 2 4.0 3 6.0 4 8.0 5 6.0 6 7.0 7 8.0 8 9.0 9 10.0 dtype: float64 >>> ##DataFrame运算 >>> df1 a b 0 0.010841 0.715210 1 0.967361 0.151983 2 0.652059 0.857662 >>> df2 a b c d e f 0 0 1 2 3 4 5 1 6 7 8 9 10 11 >>> df1.div(df2,fill_value=1) a b c d e f 0 inf 0.715210 0.500 0.333333 0.25 0.200000 1 0.161227 0.021712 0.125 0.111111 0.10 0.090909 2 0.652059 0.857662 NaN NaN NaN NaN ###############填充NaN## >>> s3=s1+s2 >>> s3 0 0.0 1 2.0 2 4.0 3 6.0 4 8.0 5 NaN 6 NaN 7 NaN 8 NaN 9 NaN dtype: float64 >>> s3.fillna(1) #用1进行填充 0 0.0 1 2.0 2 4.0 3 6.0 4 8.0 5 1.0 6 1.0 7 1.0 8 1.0 9 1.0 dtype: float64 >>>
3、函数应用
-
使用NumPy的ufunc函数
#使用NumPy的ufunc函数 >>> df = pd.DataFrame(np.arange(12).reshape(6,2)) >>> df 0 1 0 0 1 1 2 3 2 4 5 3 6 7 4 8 9 5 10 11 >>> np.cos(df) 0 1 0 1.000000 0.540302 1 -0.416147 -0.989992 2 -0.653644 0.283662 3 0.960170 0.753902 4 -0.145500 -0.911130 5 -0.839072 0.004426 >>>
-
通过apply将函数应用到行或列上(注意指定轴的方向,默认axis=0)
>>> df 0 1 0 0 1 1 2 3 2 4 5 3 6 7 4 8 9 5 10 11 >>> df.apply(lambda x : x.max()) 0 10 1 11 dtype: int64 >>> df.apply(lambda x : x.max(),axis=1) #指定轴的方向 0 1 1 3 2 5 3 7 4 9 5 11 dtype: int64 >>>
-
通过applymap将函数应用到每个数据上
>>> df 0 1 0 0 1 1 2 3 2 4 5 3 6 7 4 8 9 5 10 11 >>> df.applymap(lambda x : x if x%2 ==0 else 0) #应用到每一个元素 0 1 0 0 0 1 2 0 2 4 0 3 6 0 4 8 0 5 10 0 >>>
4、排序
-
索引排序(sort_index)
在对DataFrame操作时注意轴的方向
########Series类型######## >>> ser_obj = pd.Series(np.arange(10),index=np.random.randint(10,size=10)) >>> ser_obj 5 0 0 1 1 2 5 3 8 4 6 5 5 6 3 7 6 8 6 9 dtype: int32 >>> ser_obj.sort_index() 0 1 1 2 3 7 5 0 5 3 5 6 6 5 6 8 6 9 8 4 dtype: int32 >>> ########DataFrame类型######## >>> df = pd.DataFrame(np.random.rand(5,6),index=np.random.randint(5,size=5),co mns=np.random.randint(6,size=6)) >>> df 1 3 5 4 2 1 1 0.606201 0.771622 0.883784 0.014313 0.841963 0.917798 1 0.532707 0.001340 0.098712 0.412165 0.593807 0.455049 0 0.920531 0.470740 0.735235 0.400583 0.440331 0.168443 1 0.823637 0.436724 0.180092 0.313742 0.979541 0.543043 0 0.905565 0.835106 0.802815 0.275947 0.051905 0.710654 >>> df.sort_index() 1 3 5 4 2 1 0 0.920531 0.470740 0.735235 0.400583 0.440331 0.168443 0 0.905565 0.835106 0.802815 0.275947 0.051905 0.710654 1 0.606201 0.771622 0.883784 0.014313 0.841963 0.917798 1 0.532707 0.001340 0.098712 0.412165 0.593807 0.455049 1 0.823637 0.436724 0.180092 0.313742 0.979541 0.543043 >>> df.sort_index(axis=1) #指定轴方向 1 1 2 3 4 5 1 0.606201 0.917798 0.841963 0.771622 0.014313 0.883784 1 0.532707 0.455049 0.593807 0.001340 0.412165 0.098712 0 0.920531 0.168443 0.440331 0.470740 0.400583 0.735235 1 0.823637 0.543043 0.979541 0.436724 0.313742 0.180092 0 0.905565 0.710654 0.051905 0.835106 0.275947 0.802815 >>> >>> df.sort_index(axis=1,ascending=False) #索引降序 5 4 3 2 1 1 1 0.883784 0.014313 0.771622 0.841963 0.606201 0.917798 1 0.098712 0.412165 0.001340 0.593807 0.532707 0.455049 0 0.735235 0.400583 0.470740 0.440331 0.920531 0.168443 1 0.180092 0.313742 0.436724 0.979541 0.823637 0.543043 0 0.802815 0.275947 0.835106 0.051905 0.905565 0.710654 >>>
-
值排序(sort_values)
sort_values(by=‘label’),其中参数by是按照标签名进行排序
>>> df 1 3 5 4 2 1 1 0.606201 0.771622 0.883784 0.014313 0.841963 0.917798 1 0.532707 0.001340 0.098712 0.412165 0.593807 0.455049 0 0.920531 0.470740 0.735235 0.400583 0.440331 0.168443 1 0.823637 0.436724 0.180092 0.313742 0.979541 0.543043 0 0.905565 0.835106 0.802815 0.275947 0.051905 0.710654 >>> df.sort_values(by=2) #按照label为2进行排序 1 3 5 4 2 1 0 0.905565 0.835106 0.802815 0.275947 0.051905 0.710654 0 0.920531 0.470740 0.735235 0.400583 0.440331 0.168443 1 0.532707 0.001340 0.098712 0.412165 0.593807 0.455049 1 0.606201 0.771622 0.883784 0.014313 0.841963 0.917798 1 0.823637 0.436724 0.180092 0.313742 0.979541 0.543043 >>>
5、处理缺失数据
-
判断是否存在缺失值
可通过ser.isnull()、df.isnull()判断是否存在缺失数据
#判断Series中是否有缺失数据 >>> ser = pd.Series([1,np.nan,2,3]) >>> ser 0 1.0 1 NaN 2 2.0 3 3.0 dtype: float64 >>> ser.isnull() 0 False 1 True 2 False 3 False dtype: bool >>> #判断DataFrame中是否有缺失数据 >>> df = pd.DataFrame([np.random.randint(3,size=3),[1,np.nan,2],[3,np.nan,7]],in dex=['a','b','c']) >>> df 0 1 2 a 0 1.0 1 b 1 NaN 2 c 3 NaN 7 >>> df.isnull() 0 1 2 a False False False b False True False c False True False >>>
-
丢弃缺失数据(dropna)
>>> df.dropna <bound method DataFrame.dropna of 0 1 2 a 0 1.0 1 b 1 NaN 2 c 3 NaN 7> >>> df.dropna() 0 1 2 a 0 1.0 1 >>> df.dropna(axis=1) #凡是某一行中有缺失的数据的列丢弃 0 2 a 0 1 b 1 2 c 3 7 >>> df.dropna(axis=0) #凡是某一列中有缺失的数据的行丢弃 0 1 2 a 0 1.0 1 >>>
-
填充缺失数据(fillna)
>>> df 0 1 2 a 0 1.0 1 b 1 NaN 2 c 3 NaN 7 >>> df.fillna(10) 0 1 2 a 0 1.0 1 b 1 10.0 2 c 3 10.0 7
二、Pandas进阶
(一)统计计算和描述
|
方法 |
说明 |
|
count |
非NA值得数量 |
|
describe |
针对Series或DataFrame列计算汇总统计 |
|
min、max |
计算最小值和最大值 |
|
argmin、argmax |
计算能够获取到的最小值和最大值的索引位置(整数) |
|
idxmin、idmax |
计算能够获取到的最小值和最大值的索引值 |
|
quantile |
计算样本的分位数(0到1) |
|
sum |
值得总和 |
|
mean |
值得平均数 |
|
median |
值的算术中位数 |
|
mad |
根据平均值计算平均绝对离差 |
|
var |
样本值得方差 |
|
std |
样本值得标准差 |
|
skew |
样本值的偏度(三阶矩) |
|
kurt |
样本值的峰度(四阶矩) |
|
cumsum |
样本值得累计和 |
|
cummin、cummax |
样本值得累计最大值和累积最小值 |
|
cumprod |
样本值得累计积 |
|
diff |
计算一阶差分(一般用于时间序列) |
|
pct_change |
计算百分数变化 |
1、常用的统计计算
- sum, mean, max, min
- axis=0 按列统计,axis=1按行统计
- skipna 排除缺失值, 默认为True
- idmax, idmin, cumsum
>>> df_obj = pd.DataFrame(np.random.rand(3,4),columns=['a','b','c','d']) >>> df_obj a b c d 0 0.123562 0.201605 0.823654 0.419873 1 0.402363 0.431577 0.134377 0.898711 2 0.019123 0.728064 0.548855 0.035298 >>> df_obj.sum() a 0.545049 b 1.361245 c 1.506887 d 1.353882 dtype: float64 >>> df_obj.max() a 0.402363 b 0.728064 c 0.823654 d 0.898711 dtype: float64 >>> df_obj.min() a 0.019123 b 0.201605 c 0.134377 d 0.035298 dtype: float64 >>> df_obj.mean() a 0.181683 b 0.453748 c 0.502296 d 0.451294 dtype: float64 >>> df_obj.min(axis=1) 0 0.123562 1 0.134377 2 0.019123 dtype: float64 >>>
2、统计描述
- describe 产生多个统计数据
>>> df_obj = pd.DataFrame(np.random.rand(3,4),columns=['a','b','c','d']) >>> df_obj a b c d 0 0.494064 0.188160 0.767935 0.939915 1 0.094445 0.183256 0.683518 0.058220 2 0.380939 0.350230 0.645671 0.190707 >>> df_obj.describe() a b c d count 3.000000 3.000000 3.000000 3.000000 mean 0.323149 0.240549 0.699041 0.396281 std 0.205982 0.095019 0.062593 0.475439 min 0.094445 0.183256 0.645671 0.058220 25% 0.237692 0.185708 0.664594 0.124464 50% 0.380939 0.188160 0.683518 0.190707 75% 0.437502 0.269195 0.725727 0.565311 max 0.494064 0.350230 0.767935 0.939915 >>>
(二)层级索引
|
|
|
0 |
1 |
|
A |
one |
3.000000 |
3.000000 |
|
two |
0.240549 |
0.323149 |
|
|
B |
one |
0.205982 |
0.095019 |
|
two |
0.094445 |
0.183256 |
- MultiIndex对象
- 选取子集(外层选取 ser_obj[‘outer_label’];内层选取 ser_obj[:, ‘inner_label’])
- 常用于分组操作、透视表的生成等
- 交换分层顺序(swaplevel())
- 排序分层(sortlevel())
#创建MultiIndex对象 >>> ser_obj = pd.Series(np.random.randint(4,size=4),index=[['A','A','B','B'],['o ne','two','one','two']]) >>> ser_obj A one 2 two 2 B one 2 two 2 dtype: int32 #选取子集 >>> ser_obj['A'] #外层选取 one 2 two 2 dtype: int32 >>> ser_obj[:,'two'] #内层选取 A 2 B 2 dtype: int32 >>> #交换分层 >>> ser_obj.swaplevel() one A 2 two A 2 one B 2 two B 2 dtype: int32 >>> #交换并排序分层 >>> ser_obj.swaplevel().sortlevel() __main__:1: FutureWarning: sortlevel is deprecated, use sort_index(level=...) one A 2 B 2 two A 2 B 2 dtype: int32
(三)分组(groupby)
对数据集进行分组,然后对每组进行统计分析,分组步骤如下:
- 拆分(split):进行分组的根据
- 应用(apply):每个分组运行的计算规则
- 合并(combine):把每个分组的计算结果合并起来
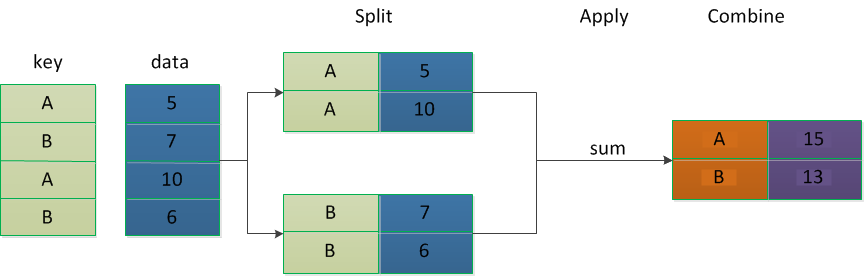
1、GroupBy对象属性
- GroupBy对象:DataFrameGroupBy,SeriesGroupBy
- GroupBy对象没有进行实际运算,只是包含分组的中间数据
- GroupBy对象进行分组运算/多重分组运算,如mean(),sum();注意非数值数据不进行分组运算
- size() 返回每个分组的元素个数
源数据:
>>> import pandas as pd >>> import numpy as np >>> dict_obj = {'k1':['a','b','c','a','b'],'d1':np.random.randn(5)} >>> df_obj = pd.DataFrame(dict_obj) >>> df_obj d1 k1 0 -0.716924 a 1 -1.533428 b 2 1.452550 c 3 0.586476 a 4 0.586688 b >>>
dataframe根据k1进行分组:
#DataFrameGroupBy 对象 >>> df_obj.groupby('k1') <pandas.core.groupby.groupby.DataFrameGroupBy object at 0x0000000004CEFC18> >>> df_obj.groupby('k1') <pandas.core.groupby.groupby.DataFrameGroupBy object at 0x0000000004CEFD30> >>> type(df_obj.groupby('k1')) <class 'pandas.core.groupby.groupby.DataFrameGroupBy'>
dataframe某一列根据k1进行分组:
#SeriesGroupBy对象 >>> df_obj d1 k1 0 -0.716924 a 1 -1.533428 b 2 1.452550 c 3 0.586476 a 4 0.586688 b >>> df_obj['d1'].groupby(df_obj['k1']) <pandas.core.groupby.groupby.SeriesGroupBy object at 0x0000000004D01710> >>> type(df_obj['d1'].groupby(df_obj['k1'])) <class 'pandas.core.groupby.groupby.SeriesGroupBy'> >>>
分组运算:
>>> df_obj d1 k1 0 -0.716924 a 1 -1.533428 b 2 1.452550 c 3 0.586476 a 4 0.586688 b >>> df_obj.groupby('k1') <pandas.core.groupby.groupby.DataFrameGroupBy object at 0x0000000004CF94A8> #分组求均值 >>> df_obj.groupby('k1').mean() d1 k1 a -0.065224 b -0.473370 c 1.452550 #分组求和 >>> df_obj.groupby('k1').sum() d1 k1 a -0.130448 b -0.946740 c 1.452550 >>> #分组中的每一组元素个数 >>> df_obj.groupby('k1').size() k1 a 2 b 2 c 1 dtype: int64 >>>
2、分组的依据
- 按列名分组(obj.groupby(‘label’))
- 按列名多层分组(obj.groupby([‘label1’, ‘label2’])->多层dataframe)
- 按自定义的key分组(obj.groupby(self_def_key);自定义的key可为列表或多层列表)
- unstack可以将多层索引的结果转换成单层的dataframe
- 其它分组依据(按列分组、字典分组、函数分组,函数传入的参数为行索引或列索引、索引级别)
>>> df_obj d1 k1 0 -0.716924 a 1 -1.533428 b 2 1.452550 c 3 0.586476 a 4 0.586688 b #按列名分组 >>> df_obj.groupby('k1') <pandas.core.groupby.groupby.DataFrameGroupBy object at 0x0000000004CF94A8> #按列分组 >>> df_obj.dtypes d1 float64 k1 object dtype: object >>> #按数据类型分组 >>> df_obj.dtypes d1 float64 k1 object dtype: object >>> df_obj.groupby(df_obj.dtypes,axis=1) <pandas.core.groupby.groupby.DataFrameGroupBy object at 0x0000000004CEF748> >>> df_obj.groupby(df_obj.dtypes,axis=1).size() float64 1 object 1 dtype: int64
3、GroupBy对象操作
-
GroupBy对象支持迭代操作
每次迭代返回一个元组 (group_name, group_data),可用于分组数据的具体运算。
>>> df_obj d1 k1 0 -0.716924 a 1 -1.533428 b 2 1.452550 c 3 0.586476 a 4 0.586688 b >>> grouped1 = df_obj.groupby('k1') >>> grouped1 <pandas.core.groupby.groupby.DataFrameGroupBy object at 0x0000000004CF9BE0> >>> for group_name,group_data in grouped1: ... print(group_name) ... print(group_data) ... a d1 k1 0 -0.716924 a 3 0.586476 a b d1 k1 1 -1.533428 b 4 0.586688 b c d1 k1 2 1.45255 c >>>
-
GroupBy对象可以转换成列表或字典
>>> df_obj d1 k1 0 -0.716924 a 1 -1.533428 b 2 1.452550 c 3 0.586476 a 4 0.586688 b >>> grouped1 = df_obj.groupby('k1') >>> grouped1 <pandas.core.groupby.groupby.DataFrameGroupBy object at 0x0000000004CF9BE0> >>> list(grouped1) #转成列表 [('a', d1 k1 0 -0.716924 a 3 0.586476 a), ('b', d1 k1 1 -1.533428 b 4 0.586688 b), ('c', d1 k1 2 1.45255 c)] >>> >>> dict(list(grouped1)) #转成字典 {'b': d1 k1 1 -1.533428 b 4 0.586688 b, 'c': d1 k1 2 1.45255 c, 'a': d1 k1 0 -0.716924 a 3 0.586476 a} >>>
(四)聚合(aggregation)
1、常用聚合函数
聚合常用于对分组后的数据进行计算,常见的聚合函数如下:
|
函数名 |
说明 |
|
count |
分组中非NA值得数量 |
|
sum |
非NA值的和 |
|
mean |
非NA值得平均值 |
|
median |
非NA值得算术中位数 |
|
std、var |
无偏(分母为n-1)标准差和方差 |
|
min、max |
非NA值得最小值和最大值 |
|
Prod |
非NA值得积 |
|
first、last |
第一个和最后一个非NA值 |
#内置聚合函数 >>> import pandas as pd >>> import numpy as np >>> dict_obj = {'k1':['a','b','c','a','b'],'d1':np.random.randn(5)} >>> df_obj = pd.DataFrame(dict_obj) >>> df_obj d1 k1 0 1.688729 a 1 -0.187755 b 2 0.900189 c 3 -0.105254 a 4 0.133984 b >>> df_obj.groupby('k1') #以k1进行分组 <pandas.core.groupby.groupby.DataFrameGroupBy object at 0x000000000470C8D0> >>> df_obj.groupby('k1').sum() #求和 d1 k1 a 1.583474 b -0.053770 c 0.900189 >>> df_obj.groupby('k1').mean() #均值 d1 k1 a 0.791737 b -0.026885 c 0.900189 >>> df_obj.groupby('k1').describe() d1 ... count mean std ... 50% 75% max k1 ... a 2.0 0.791737 1.268538 ... 0.791737 1.240233 1.688729 b 2.0 -0.026885 0.227504 ... -0.026885 0.053550 0.133984 c 1.0 0.900189 NaN ... 0.900189 0.900189 0.900189 [3 rows x 8 columns] >>> df_obj.groupby('k1').first() d1 k1 a 1.688729 b -0.187755 c 0.900189 >>> df_obj.groupby('k1').last() d1 k1 a -0.105254 b 0.133984 c 0.900189 >>> df_obj.groupby('k1').prod() d1 k1 a -0.177746 b -0.025156 c 0.900189 >>>
2、自定义聚合函数
当然还可以自定义聚合函数,传入agg方法中:
- grouped.agg(func)
- func的参数为groupby索引对应的记录
#源数据 >>> dict_obj = {'k1':['a','b','c','a','b'],'d1':np.random.randn(5)} >>> df_obj = pd.DataFrame(dict_obj) >>> df_obj d1 k1 0 1.688729 a 1 -0.187755 b 2 0.900189 c 3 -0.105254 a 4 0.133984 b #自定义聚合函数,对每一组中的数据进行处理,注意传入的是每一组数据 >>> def peak_range(df): #对每一组数据中的最大值和最小值求差值,df为索引对应的记录 ... return df.max()-df.min() ... >>> df_obj.groupby('k1').agg(peak_range) d1 k1 a 1.793983 b 0.321739 c 0.000000 >>> #另一种直接使用lambda函数 >>> df_obj.groupby('k1').agg(lambda df : df.max() - df.min())
3、应用多个聚合函数
- 同时应用多个函数进行聚合操作,使用函数列表
- 对不同的列分别作用不同的聚合函数,使用dict
#使用函数列表 >>> df_obj d1 k1 0 1.688729 a 1 -0.187755 b 2 0.900189 c 3 -0.105254 a 4 0.133984 b >>> df_obj.groupby('k1').agg(['mean','count',peak_range]) d1 mean count peak_range k1 a 0.791737 2 1.793983 b -0.026885 2 0.321739 c 0.900189 1 0.000000 >>> >>> df_obj.groupby('k1').agg(['mean','count',('range',peak_range)]) #通过元祖提供别名 d1 mean count range k1 a 0.791737 2 1.793983 b -0.026885 2 0.321739 c 0.900189 1 0.000000 >>> #通过字典作用于不同列的函数 >>> dict_mapping = {'d1':'sum'} >>> df_obj.groupby('k1').agg(dict_mapping) d1 k1 a 1.583474 b -0.053770 c 0.900189 >>> >>> dict_mapping = {'d1':['sum','max','min']} >>> df_obj.groupby('k1').agg(dict_mapping) d1 sum max min k1 a 1.583474 1.688729 -0.105254 b -0.053770 0.133984 -0.187755 c 0.900189 0.900189 0.900189 >>>
4、分组聚合运算后保持shape
-
源数据
>>> df_obj d1 k1 0 1.688729 a 1 -0.187755 b 2 0.900189 c 3 -0.105254 a 4 0.133984 b >>> df_obj.groupby('k1').agg('sum').add_prefix('func_') func_d1 k1 a 1.583474 b -0.053770 c 0.900189 >>>
-
方法一 merge外连接
>>> k1_func = df_obj.groupby('k1').agg('sum').add_prefix('func_') >>> pd.merge(df_obj,k1_func,left_on='k1',right_index=True) d1 k1 func_d1 0 1.688729 a 1.583474 3 -0.105254 a 1.583474 1 -0.187755 b -0.053770 4 0.133984 b -0.053770 2 0.900189 c 0.900189
-
方法二 transform
>>> k1_func = df_obj.groupby('k1').transform(np.sum).add_prefix('func_') >>> df_obj[k1_func.columns] = k1_func >>> df_obj d1 k1 func_d1 0 1.688729 a 1.583474 1 -0.187755 b -0.053770 2 0.900189 c 0.900189 3 -0.105254 a 1.583474 4 0.133984 b -0.053770 >>>
另外,tansform也可以传入自定义函数:
>>> df_obj d1 k1 func_d1 0 1.688729 a 1.583474 1 -0.187755 b -0.053770 2 0.900189 c 0.900189 3 -0.105254 a 1.583474 4 0.133984 b -0.053770 #自定义函数 >>> def peak_range(df): ... return df.max()-df.min() ... >>> df_obj.groupby('k1').transform(peak_range) d1 func_d1 0 1.793983 0.0 1 0.321739 0.0 2 0.000000 0.0 3 1.793983 0.0 4 0.321739 0.0
三、Pandas高级
(一)数据清洗
数据清洗是将重复、多余的数据筛选清除,将缺失的数据补充完整,将错误的数据纠正或者删除,最后整理成为可以进一步加工、使用的数据。
数据清洗的步骤:
- 分析数据
- 缺失值处理
- 异常值处理
- 去重处理
- 噪音数据处理
常见使用的方法:
- 填充缺失值(pd.fillna())
- 删除缺失值(pd.dropna())
(二)数据连接
根据单个或多个键将不同DataFrame的行连接起来,可使用pd.merge()方法来实现,该方法默认的是将不同DataFrame重叠列的列名作为”外键“进行连接:
- on显示指定“外键”
- left_on,左侧数据的“外键”
- right_on,右侧数据的“外键”
该方法默认的是“内连接”(inner),即结果中的键是交集。
pd.merge()方法参数说明:
|
参数 |
说明 |
|
left |
参与合并的左侧DataFrame |
|
right |
参与合并的右侧DataFrame |
|
how |
“inner”、”outer”、”left”、”right”,默认为”inner” |
|
on |
用于连接的列名。必须存在于左右两个DataFrame对象中,默认为left和right列名的交集作为连接键。 |
|
left_on |
左侧DataFrame用作连接键的列 |
|
right_on |
右侧DataFrame用作连接键的列 |
|
left_index |
将左侧的行索引用作其连接键 |
|
right_index |
将右侧的行索引用作其连接键 |
|
sort |
根据连接键对合并后的数据进行排序,默认为True |
|
suffixes |
字符串值元祖,用于追加到重叠列名的末尾,默认为(”_x”,”_y”)。例如,如果左右两个DataFrame对象都有”data”,则结果就会出现”data_x”和“data_y” |
|
copy |
设置为False,可以避免将数据复制到结果数据结构中,默认是复制。 |
1、默认的方式重叠列连接
>>> import pandas as pd >>> import numpy as np >>> df_obj1 = pd.DataFrame({'k':['a','b','a','c','a','b'],'d1':np.arange(10,16)} ) >>> df_obj1 d1 k 0 10 a 1 11 b 2 12 a 3 13 c 4 14 a 5 15 b >>> df_obj2 = pd.DataFrame({'k':['a','b','a','b'],'d1':np.random.randint(0,15,4) }) >>> df_obj2 d1 k 0 13 a 1 14 b 2 7 a 3 10 b # 默认将重叠列的列名作为“外键”进行连接 >>> pd.merge(df_obj1,df_obj2) d1 k d2 0 10 a 14 1 10 a 4 2 12 a 14 3 12 a 4 4 14 a 14 5 14 a 4 6 11 b 10 7 11 b 9 8 15 b 10 9 15 b 9 #指定连接的外键 >>> pd.merge(df_obj1,df_obj2,on='k') d1 k d2 0 10 a 14 1 10 a 4 2 12 a 14 3 12 a 4 4 14 a 14 5 14 a 4 6 11 b 10 7 11 b 9 8 15 b 10 9 15 b 9
2、外连接、左连接、右连接
>>> df_obj1 d1 k 0 10 a 1 11 b 2 12 a 3 13 c 4 14 a 5 15 b >>> df_obj1=df_obj1.rename(columns={'k':'k1'}) # 更改列名 >>> df_obj1 d1 k1 0 10 a 1 11 b 2 12 a 3 13 c 4 14 a 5 15 b >>> df_obj2 d2 k 0 14 a 1 10 b 2 4 a 3 9 b >>> df_obj2=df_obj2.rename(columns={'k':'k2'}) # 更改列名 >>> df_obj2 d2 k2 0 14 a 1 10 b 2 4 a 3 9 b >>> pd.merge(df_obj1,df_obj2,left_on='k1',right_on='k2') d1 k1 d2 k2 0 10 a 14 a 1 10 a 4 a 2 12 a 14 a 3 12 a 4 a 4 14 a 14 a 5 14 a 4 a 6 11 b 10 b 7 11 b 9 b 8 15 b 10 b 9 15 b 9 b >>> #外连接 >>> pd.merge(df_obj1, df_obj2, left_on='k1', right_on='k2', how='outer') d1 k1 d2 k2 0 10 a 14.0 a 1 10 a 4.0 a 2 12 a 14.0 a 3 12 a 4.0 a 4 14 a 14.0 a 5 14 a 4.0 a 6 11 b 10.0 b 7 11 b 9.0 b 8 15 b 10.0 b 9 15 b 9.0 b 10 13 c NaN NaN #左连接 >>> pd.merge(df_obj1, df_obj2, left_on='k1', right_on='k2', how='left') d1 k1 d2 k2 0 10 a 14.0 a 1 10 a 4.0 a 2 11 b 10.0 b 3 11 b 9.0 b 4 12 a 14.0 a 5 12 a 4.0 a 6 13 c NaN NaN 7 14 a 14.0 a 8 14 a 4.0 a 9 15 b 10.0 b 10 15 b 9.0 b #右连接 >>> pd.merge(df_obj1, df_obj2, left_on='k1', right_on='k2', how='right') d1 k1 d2 k2 0 10 a 14 a 1 12 a 14 a 2 14 a 14 a 3 10 a 4 a 4 12 a 4 a 5 14 a 4 a 6 11 b 10 b 7 15 b 10 b 8 11 b 9 b 9 15 b 9 b >>>
3、处理重复列名
>>> df_obj1 = pd.DataFrame({'key': ['b', 'b', 'a', 'c', 'a', 'a', 'b'],
... 'data' : np.random.randint(0,10,7)})
>>>
>>> df_obj1
data key
0 1 b
1 5 b
2 8 a
3 3 c
4 3 a
5 0 a
6 9 b
>>> df_obj2 = pd.DataFrame({'key': ['a', 'b', 'd'],
... 'data' : np.random.randint(0,10,3)})
>>>
>>> df_obj2
data key
0 1 a
1 4 b
2 4 d
#处理列名相同使用suffixes参数
>>> pd.merge(df_obj1,df_obj2,on='key',suffixes=('_left','_right'))
data_left key data_right
0 1 b 4
1 5 b 4
2 9 b 4
3 8 a 1
4 3 a 1
5 0 a 1
>>>
(三)数据合并
沿轴方向将多个对象合并到一起,使用pd.concat()方法:
- 注意指定轴方向,默认axis=0
- join指定合并方式,默认为outer
- Series合并时查看行索引
- DataFrame合并时同时查看行索引和列索引
1、NumPy中的concatenate
#numpy中的合并concatenate >>> import numpy as np >>> import pandas as pd >>> arr1 = np.random.randint(0,10,(2,5)) >>> arr2 = np.random.randint(0,10,(3,5)) >>> arr1 array([[6, 4, 0, 5, 4], [8, 9, 4, 1, 9]]) >>> arr2 array([[0, 5, 5, 2, 5], [4, 2, 2, 5, 6], [9, 3, 3, 8, 4]]) >>> np.concatenate([arr1,arr2]) array([[6, 4, 0, 5, 4], [8, 9, 4, 1, 9], [0, 5, 5, 2, 5], [4, 2, 2, 5, 6], [9, 3, 3, 8, 4]]) >>>
2、Series中的concat
#1、索引不重复 >>> ser_obj1 = pd.Series(np.random.randint(0,10,5),index=range(5)) >>> ser_obj2 = pd.Series(np.random.randint(0,10,3),index=range(5,8)) >>> ser_obj1 0 0 1 1 2 2 3 9 4 5 dtype: int32 >>> ser_obj2 5 0 6 8 7 0 dtype: int32 #进行合并 >>> pd.concat([ser_obj1,ser_obj2]) 0 0 1 1 2 2 3 9 4 5 5 0 6 8 7 0 dtype: int32 >>> #axis=1 >>> pd.concat([ser_obj1,ser_obj2],axis=1) 0 1 0 0.0 NaN 1 1.0 NaN 2 2.0 NaN 3 9.0 NaN 4 5.0 NaN 5 NaN 0.0 6 NaN 8.0 7 NaN 0.0 >>> #2、索引有重复的 >>> ser_obj1 = pd.Series(np.random.randint(0,10,5),index=range(5)) >>> ser_obj2 = pd.Series(np.random.randint(0,10,3),index=range(3)) >>> ser_obj1 0 0 1 3 2 0 3 2 4 0 dtype: int32 >>> ser_obj2 0 2 1 0 2 1 dtype: int32 >>> pd.concat([ser_obj1,ser_obj2]) 0 0 1 3 2 0 3 2 4 0 0 2 1 0 2 1 dtype: int32 >>> >>> pd.concat([ser_obj1,ser_obj2],axis=1,join='inner') #axis方向 0 1 0 0 2 1 3 0 2 0 1 >>>
3、DataFrame中的concat
>>> df_obj1 = pd.DataFrame(np.random.randint(0,10,(3,4)),index=['a','b','c'],col umns=['A','B','C','D']) >>> df_obj2 = pd.DataFrame(np.random.randint(0,10,(2,4)),index=['a','b'],columns =['E','F','G','H']) >>> df_obj1 A B C D a 1 4 7 3 b 2 7 5 6 c 9 4 7 3 >>> df_obj2 E F G H a 5 6 6 5 b 3 3 1 5 >>> pd.concat([df_obj1,df_obj2]) A B C D E F G H a 1.0 4.0 7.0 3.0 NaN NaN NaN NaN b 2.0 7.0 5.0 6.0 NaN NaN NaN NaN c 9.0 4.0 7.0 3.0 NaN NaN NaN NaN a NaN NaN NaN NaN 5.0 6.0 6.0 5.0 b NaN NaN NaN NaN 3.0 3.0 1.0 5.0 >>> >>> pd.concat([df_obj1,df_obj2],axis=1) #指定轴方向 A B C D E F G H a 1 4 7 3 5.0 6.0 6.0 5.0 b 2 7 5 6 3.0 3.0 1.0 5.0 c 9 4 7 3 NaN NaN NaN NaN >>>
(四)数据重构
1、stack
- 将列索引旋转为行索引
- 完成层级索引
- DataFrame->Series
#stack将DataFrame转成Series >>> import numpy as np >>> import pandas as pd >>> df_obj = pd.DataFrame(np.random.randint(0,10,(3,4)),columns=['a','b','c','d' ]) >>> df_obj a b c d 0 1 5 8 8 1 5 5 0 1 2 6 5 5 3 >>> stacked = df_obj.stack() >>> stacked 0 a 1 b 5 c 8 d 8 1 a 5 b 5 c 0 d 1 2 a 6 b 5 c 5 d 3 dtype: int32 >>> type(stacked) <class 'pandas.core.series.Series'> >>> type(stacked.index) <class 'pandas.core.indexes.multi.MultiIndex'> >>>
2、unstack
- 将层级索引展开
- Series->DataFrame
- 默认操作内层索引,即level=-1
>>> stacked 0 a 1 b 5 c 8 d 8 1 a 5 b 5 c 0 d 1 2 a 6 b 5 c 5 d 3 dtype: int32 >>> stacked .unstack() ## 默认操作内层索引 a b c d 0 1 5 8 8 1 5 5 0 1 2 6 5 5 3 >>> stacked .unstack(level=0) # 通过level指定操作索引的级别 0 1 2 a 1 5 6 b 5 5 5 c 8 0 5 d 8 1 3 >>>
(五)数据转换
1、处理重复数据
- duplicated() 返回布尔型Series表示每行是否为重复行
- drop_duplicates() 过滤重复行(默认判断全部列;可指定按某些列判断)
>>> df_obj = pd.DataFrame({'d1':['a']*3+['b']*5,'d2':np.random.randint(0,10,8)})
>>> df_obj
d1 d2
0 a 1
1 a 1
2 a 6
3 b 0
4 b 6
5 b 3
6 b 4
7 b 3
>>> df_obj.duplicated() #判断重复行,重复行为True
0 False
1 True
2 False
3 False
4 False
5 False
6 False
7 True
dtype: bool
>>> df_obj.drop_duplicates() #将重复行去除
d1 d2
0 a 1
2 a 6
3 b 0
4 b 6
5 b 3
6 b 4
>>>
>>> df_obj.drop_duplicates('d2')
d1 d2
0 a 1
2 a 6
3 b 0
5 b 3
6 b 4
>>>
2、map
- Series根据map传入的函数对每行或每列进行转换
>>> ser_obj = pd.Series(np.random.randint(0,15,10)) >>> ser_obj 0 10 1 8 2 13 3 14 4 12 5 7 6 6 7 14 8 4 9 8 dtype: int32 >>> ser_obj.map(lambda x:x**3) 0 1000 1 512 2 2197 3 2744 4 1728 5 343 6 216 7 2744 8 64 9 512 dtype: int64 >>> ser_obj.map(lambda x:x**3)
3、数据替换(replace)
#Series中的替换 >>> ser_obj = pd.Series(np.random.randint(0,15,10)) >>> ser_obj 0 1 1 10 2 10 3 9 4 12 5 11 6 8 7 7 8 8 9 2 dtype: int32 #单值替换 >>> ser_obj.replace(10,100) #将10这个数替换成100 0 1 1 100 2 100 3 9 4 12 5 11 6 8 7 7 8 8 9 2 dtype: int32 #多值替换 >>> ser_obj 0 1 1 10 2 10 3 9 4 12 5 11 6 8 7 7 8 8 9 2 >>> ser_obj.replace([1,9],-100) #将1和9替换成-100 0 -100 1 10 2 10 3 -100 4 12 5 11 6 8 7 7 8 8 9 2 dtype: int32 >>> ser_obj.replace([1,9],[-100,-200]) #将1替换成-100,将9替换成-200 0 -100 1 10 2 10 3 -200 4 12 5 11 6 8 7 7 8 8 9 2 dtype: int64 >>>

