
Zeppelin原理简介
Zeppelin是一个基于Web的notebook,提供交互数据分析和可视化。后台支持接入多种数据处理引擎,如spark,hive等。支持多种语言: Scala(Apache Spark)、Python(Apache Spark)、SparkSQL、 Hive、 Markdown、Shell等。本文主要介绍Zeppelin中Interpreter和SparkInterpreter的实现原理。
转载请注明
http://www.cnblogs.com/shenh062326/p/6195064.html
安装与使用
参考http://blog.csdn.net/jasonding1354/article/details/46822391
原理简介
Interpreter
Zeppelin中最核心的概念是Interpreter,interpreter是一个插件允许用户使用一个指定的语言或数据处理器。每一个Interpreter都属于换一个InterpreterGroup,同一个InterpreterGroup的Interpreters可以相互引用,例如SparkSqlInterpreter 可以引用 SparkInterpreter 以获取 SparkContext,因为他们属于同一个InterpreterGroup。当前已经实现的Interpreter有spark解释器,python解释器,SparkSQL解释器,JDBC,Markdown和shell等。下图是Zeppelin官网中介绍Interpreter的原理图。
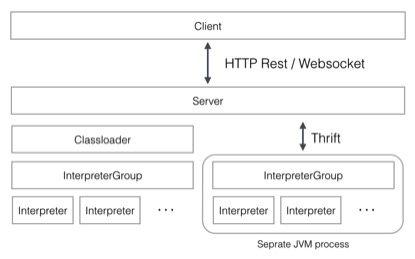
Interpreter接口中最重要的方法是open,close,interpert三个方法,另外还有cancel,gerProgress,completion等方法。
Open 是初始化部分,只会调用一次。
Close 是关闭释放资源的接口,只会调用一次。
Interpret 会运行一段代码并返回结果,同步执行方式。
Cancel可选的接口,用于结束interpret方法
getPregress 方法获取interpret的百分比进度
completion 基于游标位置获取结束列表,实现这个接口可以实现自动结束
SparkInterpreter
Open方法中,会初始化SparkContext,SQLContext,ZeppelinContext;当前支持的模式有:
• local[*] in local mode
• spark://master:7077 in standalone cluster
• yarn-client in Yarn client mode
• mesos://host:5050 in Mesos cluster
其中Yarn集群只支持client模式。
if (isYarnMode()) { conf.set("master", "yarn"); conf.set("spark.submit.deployMode", "client"); }
Interpret方法中会执行一行代码(以\n分割),其实会调用spark 的SparkILoop一行一行的执行(类似于spark shell的实现),这里的一行是逻辑行,如果下一行代码中以“.”开头(非“..”,“./”),也会和本行一起执行。关键代码如下:
scala.tools.nsc.interpreter.Results.Result res = null; try { res = interpret(incomplete + s); } catch (Exception e) { sc.clearJobGroup(); out.setInterpreterOutput(null); logger.info("Interpreter exception", e); return new InterpreterResult(Code.ERROR, InterpreterUtils.getMostRelevantMessage(e)); } r = getResultCode(res);
sparkInterpret的关键方法:
close 方法会停止SparkContext
cancel 方法直接调用SparkContext的cancel方法。sc.cancelJobGroup(getJobGroup(context)
getProgress 通过SparkContext获取所有stage的总的task和已经结束的task,结束的tasks除以总的task得到的比例就是进度。
问题1,是否可以存在多个SparkContext?
Interpreter支持'shared', 'scoped', 'isolated'三种选项,在scopde模式下,spark interpreter为每个notebook创建编译器但只有一个SparkContext;isolated模式下会为每个notebook创建一个单独的SparkContext。
问题2,isolated模式下,多个SparkContext是否在同一个进程中?
一个服务端启动多个spark Interpreter后,会启动多个SparkContext。不过可以用另外一个jvm启动spark Interpreter。
Zeppelin优缺点小结
优点
1.提供restful和webSocket两种接口。
2.使用spark解释器,用户按照spark提供的接口编程即可,用户可以自己操作SparkContext,不过用户3.不能自己去stop SparkContext;SparkContext可以常驻。
4.包含更多的解释器,扩展性也很好,可以方便增加自己的解释器。
5.提供了多个数据可视化模块,数据展示方便。
缺点
1.没有提供jar包的方式运行spark任务。
2.只有同步的方式运行,客户端可能需要等待较长时间。

