深入剖析linq的联接
内联接
代码如下
from a in new List<string[]>{ new string[2]{"张三","男"}, new string[2]{"李四","女"}, new string[2]{"王五","男"} } join b in new List<string[]>{ new string[3]{"张三","英语","90"}, new string[3]{"张三","语文","70"}, new string[3]{"李四","数学","100"} } on a[0] equals b[0] select new {User=a,Score=b}
结果的结构如下
注意结果里没有a表的“王五”数据,在内联接查询里,内部联接会生成一个结果集,在该结果集中,第一个集合的每个元素对于第二个集合中的每个匹配元素都会出现一次。 如果第一个集合中的元素没有匹配元素,则它不会出现在结果集中。
总结:内联接用“join 数据源 on 条件"语法,会将左表(即写在前面的表)的每一条记录和右表(即写在后面的表)的每一条记录进行比较,如果左表有x条记录,右表有y条记录,比较会有x*y次比较,但最后的结果不会有x*y条,而是在x*y条里过滤出符合on条件的记录,有点类似“笛卡尔积+条件判断”的操作。
上面的内联接可完全改成两个from操作(进行笛卡尔积求值),结果的结构是完全一样的
from a in new List<string[]>{ new string[2]{"张三","男"}, new string[2]{"李四","女"}, new string[2]{"王五","男"} } from b in new List<string[]>{ new string[3]{"张三","英语","90"}, new string[3]{"张三","语文","70"}, new string[2]{"李四","100"} } where a[0]==b[0] select new {User=a,Score=b}
写到这,可能会问,那所有的内联接操作都改成几个from表就行,还用得着join on的内联接吗?答案是内联接比单纯对几个表进行笛卡尔积求值“效率高很多”,假设有a,b,c三个表,分别为x,y,z条记录,如果用笛卡尔积算法(linq代码如:from a in tab_a from b in tab_b from c in tab_c where ...... select ....),一共会进行x*y*z次连接操作,并对x*y*z条记录进行where过滤;但如果用内联接(linq代码如:from a in tab_a join b in tab_b on ... join c in tab_c on ... select ....),每一次的内联接会基于上一次的结果来进行下一次的操作,即a表和b表进行x*y次操作后,最后可能只得出w条记录(此时的w可能远小于x*y),然后再对c表进行w*z次操作,两者比较x*y*z可能远大于w*z。如果不是a,b,c三个表,而是更多的表进行联接,效率就差距很大了。
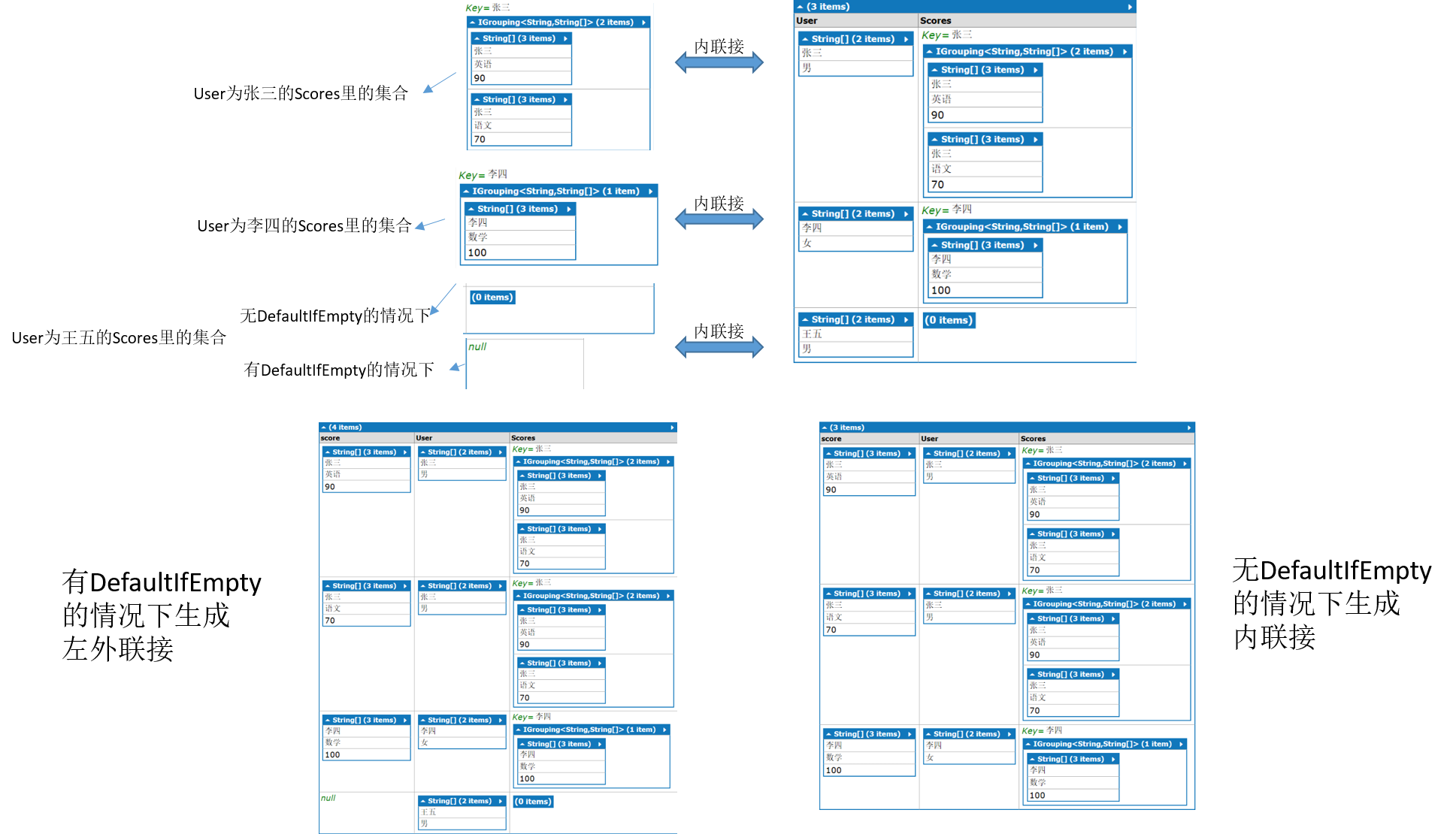
组联接
代码如下:
from a in new List<string[]>{ new string[2]{"张三","男"}, new string[2]{"李四","女"}, new string[2]{"王五","男"} } join b in new List<string[]>{ new string[3]{"张三","英语","90"}, new string[3]{"张三","语文","70"}, new string[3]{"李四","数学","100"} } on a[0] equals b[0] into b_group select new {User=a,Score=b_group}
结果的结构如下

注意:此时“王五”出现在了结果里,在组联接里,第一个集合的每个元素都会出现在分组联接的结果集中(无论是否在第二个集合中找到关联元素)。 在未找到任何相关元素的情况下,该元素的相关元素序列为空。 因此,结果选择器有权访问第一个集合的每个元素。 这与非分组联接中的结果选择器不同,后者无法访问第一个集合中在第二个集合中没有匹配项的元素。
总结:内联接用“join 数据源 on 条件 into 新数据源"语法,会以左表(即写在前面的表)的每一条记录为一组,分别和右表(即写在后面的表)的每一条记录进行比较,如果左表有x条记录,右表有条记录,比较会有x*y次比较,但结果只有x组,而每一组可能有<=y条>=0条记录。
如果要对上面的代码进行输出操作,会有两次循环操作
var query=from a in new List<string[]>{ new string[2]{"张三","男"}, new string[2]{"李四","女"}, new string[2]{"王五","男"} } join b in new List<string[]>{ new string[3]{"张三","英语","90"}, new string[3]{"张三","语文","70"}, new string[3]{"李四","数学","100"} } on a[0] equals b[0] into b_group select new {User=a,Score=b_group}; foreach(var p1 in query){ Console.WriteLine($@"{p1.User[0]}的成绩如下:"); foreach(var p2 in p1.Score){ Console.Write($@"---{p2[1]}-{p2[2]}---"); } Console.WriteLine(); }
结果输出如下:
张三的成绩如下:
---英语-90------语文-70---
李四的成绩如下:
---数学-100---
王五的成绩如下:
可以发现,单是用组联接其实返回的结果在有些情况下是不方便进行处理的,因为要对每一个组再进行循环才能取到我们最终想要的值,下面介绍用“内联接+组联接”来方便的得到我们想要的值
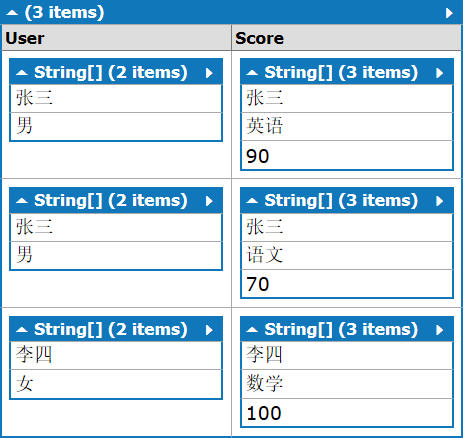
内联接+组联接
代码如下:
from a in new List<string[]>{ new string[2]{"张三","男"}, new string[2]{"李四","女"}, new string[2]{"王五","男"} } join b in new List<string[]>{ new string[3]{"张三","英语","90"}, new string[3]{"张三","语文","70"}, new string[3]{"李四","数学","100"} } on a[0] equals b[0] into b_group from b2 in b_group select new {User=a,Score=b2}
即在组联接后的新表b_group再次联接:from b2 in b_group
结果的结构如下:
如果细心的朋友会注意到现在的结果和最前面“内联接”一节的结果是一样的。
这样的结果结构相比上一节的组联接的结构更容易获取结果内容,不再需要需要两次循环,取值代码如下
foreach(var p1 in query){ Console.WriteLine($@"{p1.User[0]}-{p1.User[1]}-{p1.Score[1]}-{p1.Score[2]}"); }
输出如下:
张三-男-英语-90
张三-男-语文-70
李四-女-数学-100
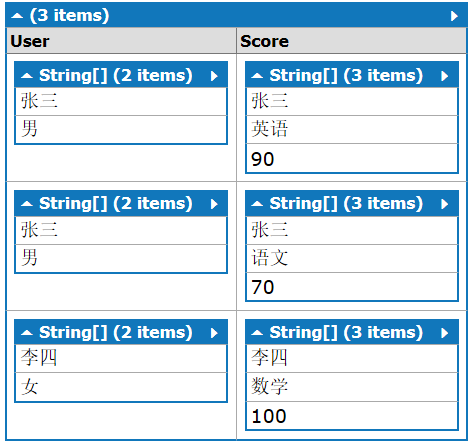
对代码稍作修改
from a in new List<string[]>{ new string[2]{"张三","男"}, new string[2]{"李四","女"}, new string[2]{"王五","男"} } join b in new List<string[]>{ new string[3]{"张三","英语","90"}, new string[3]{"张三","语文","70"}, new string[3]{"李四","数学","100"} } on a[0] equals b[0] into b_group from b2 in b_group select new {User=a,Score=b_group}
只是将
select new {User=a,Score=b2}改成了
select new {User=a,Score=b_group}
结果的结构变成如下
每条结果的结构变成string[]和IGrouping<string,string[]>,不管结果的结构如何,记录里已经没有“王五”的数据。
再改下代码,看看b_group,b2和a的全部结构是怎样的
代码如下:
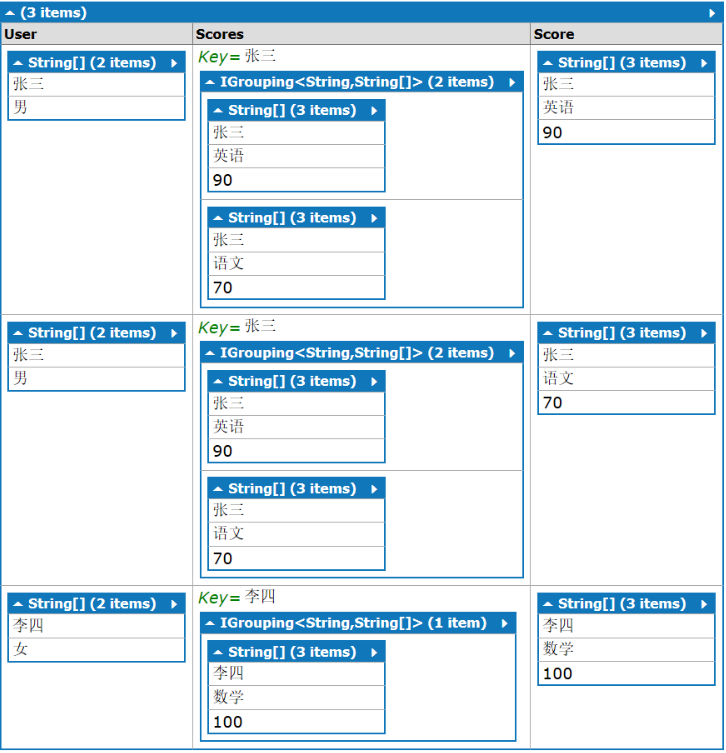
from a in new List<string[]>{ new string[2]{"张三","男"}, new string[2]{"李四","女"}, new string[2]{"王五","男"} } join b in new List<string[]>{ new string[3]{"张三","英语","90"}, new string[3]{"张三","语文","70"}, new string[2]{"李四","100"} } on a[0] equals b[0] into b_group from b2 in b_group.DefaultIfEmpty() select new{User=a, Scores=b_group,Score=b2}
结果的结构如下:
左外联接
代码如下
from a in new List<string[]>{ new string[2]{"张三","男"}, new string[2]{"李四","女"}, new string[2]{"王五","男"} } join b in new List<string[]>{ new string[3]{"张三","英语","90"}, new string[3]{"张三","语文","70"}, new string[2]{"李四","100"} } on a[0] equals b[0] into b_group from b2 in b_group.DefaultIfEmpty() select new{User=a, Score=b2}
只是在“内联接+组联接”的代码上做了一点改动,将from b2 in b_group改成了from b2 in b_group.DefaultIfEmpty()
结果如下

代码稍作修改,看看内部所有结构
from a in new List<string[]>{ new string[2]{"张三","男"}, new string[2]{"李四","女"}, new string[2]{"王五","男"} } join b in new List<string[]>{ new string[3]{"张三","英语","90"}, new string[3]{"张三","语文","70"}, new string[2]{"李四","100"} } on a[0] equals b[0] into b_group from b2 in b_group.DefaultIfEmpty() select new{User=a, Scores=b_group,Score=b2}
结果的结构如下
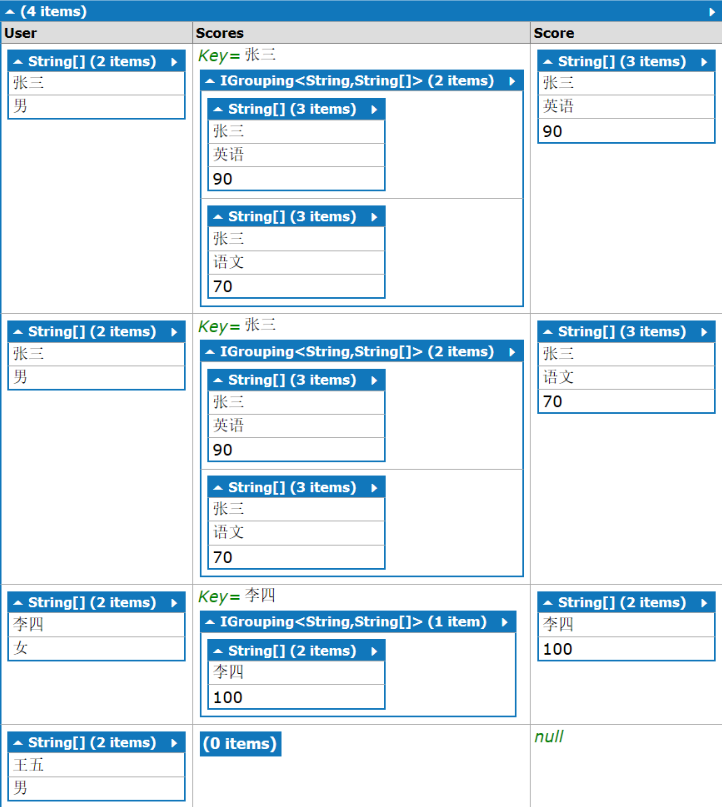
结构和“内联接+组联接"的结构是完成一样的,只是找不到成绩的“王五”也出现在结果集里。
很多资料只写了怎么用“左联接”,但为什么要这么“别扭”写的原因却没有说明,特别是熟悉sql语句的对这种方式很不理解,觉得太绕了。要理解linq,先要抛开之前sql语句的影响,linq既然是c#里对象的sql语句,那我们就要以对象的方式去思考,微软的目的是为了保证linq to object、linq to sql、linq to xml的语法是一样的。先理解linq to object,至于linq to sql最终生成的sql语句是由linq底层的算法来实现的。的下面用图说明下“组联接”--》“内联接+组联接”--》“左外联接“是怎么生成的