
国产烂片深度揭秘
1.读取数据
以“豆瓣评分”为标准,看看电影评分分布,及烂片情况
① 读取数据“moviedata.xlsx”
② 查看“豆瓣评分”数据分布,绘制直方图、箱型图
③ 判断“豆瓣评”数据是否符合正态分布
④ 如果符合正态分布,这里以上四分位数(该样本中所有数值由小到大排列后第25%的数字)评分为“烂片标准”
⑤ 筛选出烂片数据,并做排名,找到TOP20
===>>>
① 读取数据之后去除缺失值
② 这里可以用ks检验来判断数据是否符合正态分布
烂片评价标准:4.3分,整理后烂片数据大概546条

import numpy as np import pandas as pd import matplotlib.pyplot as plt import warnings warnings.filterwarnings('ignore') # 不发出警告 from bokeh.io import output_notebook output_notebook() # 导入notebook绘图模块 from bokeh.plotting import figure,show from bokeh.models import ColumnDataSource,HoverTool # 导入图表绘制、图标展示模块 # 导入ColumnDataSource模块
# (1)查看数据,数据清洗 import os os.chdir(r'E:\Python数据分析\项目\11烂片') # 创建工作路径 df = pd.read_excel('moviedata.xlsx') df = df[df['豆瓣评分'] > 0] print('初步清洗后数据量为%i条' % len(df)) # 读取数据 # 删除“豆瓣评分”小于等于0的值
# (2)查看豆瓣评分情况 fig = plt.figure(figsize = (10,6)) plt.subplots_adjust(hspace=0.2) # 创建绘图空间 ax1 = fig.add_subplot(2,1,1) df['豆瓣评分'].plot.hist(stacked=True,bins=50,color = 'green',alpha=0.5,grid=True) plt.ylim([0,150]) plt.title('豆瓣评分数据分布-直方图') # 绘制直方图 ax2 = fig.add_subplot(2,1,2) color = dict(boxes='DarkGreen', whiskers='DarkOrange', medians='DarkBlue', caps='Gray') df['豆瓣评分'].plot.box(vert=False, grid = True,color = color) plt.title('豆瓣评分数据分布-箱型图') # 绘制箱型图 df['豆瓣评分'].describe()
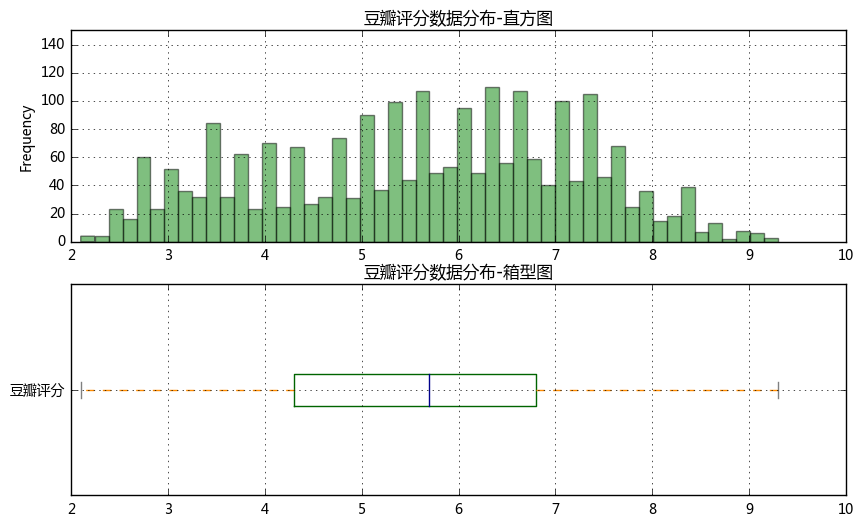
# 判断是否符合正态分布 from scipy import stats # 导入相关模块 u = df['豆瓣评分'].mean() # 计算均值 std = df['豆瓣评分'].std() # 计算标准差 stats.kstest(df['豆瓣评分'], 'norm', (u, std)) # 这里p值大于0.05,为正态分布 # 结论 # 这里以样本数据上四分位数为烂片评判标准 → 4.3分
# 筛选出烂片数据,并做排名,找到TOP20 data_lp = df[df['豆瓣评分']<4.3].reset_index() print('数据整理后,得到烂片数据量为%i条' % len(data_lp)) # 筛选烂片数据 lp_top20 = data_lp[['电影名称','豆瓣评分','导演','主演']].sort_values(by = '豆瓣评分').iloc[:20].reset_index() del lp_top20['index'] lp_top20 # 查看烂片top20
2、什么题材的电影烂片最多?
① 按照“类型”字段分类,筛选不同电影属于什么题材
② 整理数据,按照“题材”汇总,查看不同题材的烂片比例,并选取TOP20
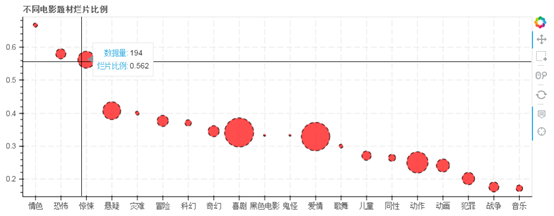
③ 将得到的题材烂片比例TOP20制作散点图 → 横坐标为“题材”类型,纵坐标为烂片比例,点大小为样本数量
** 用bokeh制图
** 按照烂片比例做降序排列
===>>>
① 删除“类型”字段空值的数据
② 由于一个电影“类型”会有多个,这里需要将一个电影每个“类型”都识别出来,在统计某个题材时都需要计算,例如:
如果一个电影的类型为:“喜剧/爱情”,则在计算“喜剧”、“爱情”题材的烂片比例时,都需要将该电影算上
③ 注意类型字段中,要删除空格字符
④ bokeh图设置点大小,这里通过 开方减小数据差距 → size = count**0.5*系数
# (3)筛选出所有题材类型,查看不同题材烂片比例 typelst = [] for i in df[df['类型'].notnull()]['类型'].str.replace(' ','').str.split('/'): typelst.extend(i) # 取出所有电影的“类型”,并整理成列表 # 注意这里要删除“类型”中的空格字符 typelst = list(set(typelst)) print(typelst) # 列表去重
# 创建函数,查看不同题材的烂片比例 # 这里要删除“类型”字段空值的数据 lst_type_lp = [] # 创建空字典、空列表 df_type = df[df['类型'].notnull()][['电影名称','豆瓣评分','类型']] # 筛选数据 def f1(data,typei): dic_type_lp = {} datai = data[data['类型'].str.contains(typei)] # 筛选数据 lp_pre_i = len(datai[datai['豆瓣评分']<4.3])/len(datai) # 计算该题材烂片比例 dic_type_lp['typename'] = typei dic_type_lp['typecount'] = len(datai) dic_type_lp['type_lp_pre'] = lp_pre_i # 将结果记录进字典中,包括题材类型、烂片比例、样本数据数量 return(dic_type_lp) for i in typelst: dici = f1(df_type,i) lst_type_lp.append(dici) # 按照题材遍历数据,得到不同题材的烂片比例 df_type_lp = pd.DataFrame(lst_type_lp) type_lp_top20 = df_type_lp.sort_values(by = 'type_lp_pre',ascending = False).iloc[:20] type_lp_top20 # 筛选出烂片比例TOP的题材类型
#(4) bokeh制图 type_lp_top20['size'] = type_lp_top20['typecount']**0.5*2 # 设置点大小,这里通过开方减小数据差距 source = ColumnDataSource(data=type_lp_top20) # 创建数据 lst_type = type_lp_top20['typename'].tolist() # 设置横坐标list hover = HoverTool(tooltips=[("数据量", "@typecount"), ("烂片比例","@type_lp_pre")]) # 设置标签显示内容 p = figure(x_range=lst_type, plot_width=900, plot_height=350, title="不同电影题材烂片比例", tools=[hover,'reset,xwheel_zoom,pan,crosshair,box_select']) # 构建绘图空间 p.circle(x='typename',y='type_lp_pre',source = source, size = 'size', line_color = 'black',line_dash = [6,4],fill_color = 'red',fill_alpha = 0.7) # 绘制散点图 p.xgrid.grid_line_dash = [10,4] p.ygrid.grid_line_dash = [10,4] # 设置其他参数 show(p)
3、和什么国家合拍更可能产生烂片?
① 按照“制片国家/地区”字段分类,筛选不同电影的制片地
② 整理数据,按照“题材”汇总,查看不同题材的烂片比例,并选取TOP20
===>>>
① 删除“制片国家/地区”字段空值的数据
② 删除“制片国家/地区”中不包括“中国大陆”的数据
③ 制片地删除“中国大陆”、“中国”、“台湾”、“香港”等噪音数据
④ 筛选合作电影大于等于3部以上的国家
# 筛选电影制片地; 这里要删除“制片国家/地区”字段空值的数据; 制片地删除“中国大陆”、“中国”、“台湾”、“香港”等噪音数据 #(1)和什么国家合拍更可能产品烂片
df_loc = df[['电影名称','制片国家/地区','豆瓣评分']][df['制片国家/地区'].notnull()] df_loc = df_loc[df_loc['制片国家/地区'].str.contains('中国大陆')] # 筛选数据 loclst = [] for i in df_loc['制片国家/地区'].str.replace(' ','').str.split('/'): loclst.extend(i) # 取出所有电影的制片地,并整理成列表; 注意这里要删除“制片国家/地区”中的空格字符 loclst = list(set(loclst)) loclst.remove('中国大陆') loclst.remove('中国') loclst.remove('台湾') loclst.remove('香港') print(loclst) # 列表去重
# 创建函数,查看不同制片地的烂片比例 lst_loc_lp = [] # 创建空列表 def f2(data,loci): dic_loc_lp = {} datai = data[data['制片国家/地区'].str.contains(loci)] # 筛选数据 lp_pre_i = len(datai[datai['豆瓣评分']<4.3])/len(datai) # 计算该制片地烂片比例 dic_loc_lp['loc'] = loci dic_loc_lp['loccount'] = len(datai) dic_loc_lp['loc_lp_pre'] = lp_pre_i # 将结果记录进字典中,包括制片地、烂片比例、样本数据数量 return(dic_loc_lp) for i in loclst: dici = f2(df_loc,i) lst_loc_lp.append(dici) # 按照题材遍历数据,得到不同制片地的烂片比例 df_loc_lp = pd.DataFrame(lst_loc_lp) df_loc_lp = df_loc_lp[df_loc_lp['loccount']>=3] # 筛选合作电影大于等于3部以上的国家 loc_lp_top20 = df_loc_lp.sort_values(by = 'loc_lp_pre',ascending = False).iloc[:20] loc_lp_top20 # 筛选出烂片比例TOP的制片地 # 结论 # 综合来看,居然和欧美合作更可能产生烂片
4、卡司数量是否和烂片有关?
① 计算每部电影的主演人数
② 按照主演人数分类,并统计烂片率
** 分类:'1-2人','3-4人','5-6人','7-9人','10以上'
③ 查看烂片比例最高的演员TOP20
===>>
① 通过“主演”字段内做分列来计算主演人数
② 需要分别统计不同主演人数的电影数量及烂片数量,再计算烂片比例
③ 这里可以按照明星再查看一下他们的烂片率,比如:吴亦凡、杨幂、黄晓明、甄子丹、刘亦菲、范冰冰....
#(2)卡司数量与烂片的关系
# 计算每部电影的主演人数,并统计烂片率 # 分类:'1-2人','3-4人','5-6人','7-9人','10以上'
df['主演人数'] = df['主演'].str.split('/').str.len() # 计算主演人数 df_leadrole1 = df[['主演人数','豆瓣评分']].groupby('主演人数').count() df_leadrole2 = df[['主演人数','豆瓣评分']][df['豆瓣评分']<4.3].groupby('主演人数').count() # 按照主演人数分组,分别统计电影数量及烂片数量 df_leadrole_pre = pd.merge(df_leadrole1,df_leadrole2,left_index = True,right_index = True) df_leadrole_pre.columns = ['电影数量','烂片数量'] # 按照主演人数统计烂片比例 df_leadrole_pre.reset_index(inplace = True) df_leadrole_pre['主演人数分类'] = pd.cut(df_leadrole_pre['主演人数'], [0,2,4,6,9,50], labels = ['1-2人','3-4人','5-6人','7-9人','10人及以上']) df_leadrole_pre2 = df_leadrole_pre[['主演人数分类','电影数量','烂片数量']].groupby('主演人数分类').sum() df_leadrole_pre2['烂片比例'] = df_leadrole_pre2['烂片数量']/df_leadrole_pre2['电影数量'] df_leadrole_pre2 # 按照主演人数分类后再统计 # 分类:'1-2人','3-4人','5-6人','7-9人','10以上'
#(3)不同主演的烂片比例
# 筛选主演; 这里用烂片数据来筛选,不用全数据 df_role1 = df[(df['豆瓣评分']<4.3) & (df['主演'].notnull())] df_role2 = df[df['主演'].notnull()] leadrolelst = [] for i in df_role1['主演'][df_role1['主演'].notnull()].str.replace(' ','').str.split('/'): leadrolelst.extend(i) # 取出所有电影的主演,并整理成列表; 注意这里要删除“主演”中的空格字符 leadrolelst = list(set(leadrolelst)) print('筛选后的主演演员人数为%i人' % len(leadrolelst)) print(leadrolelst) # 列表去重
# 查看不同主演的烂片比例; 这里去除掉拍过3次电影以下的演员 lst_role_lp = [] # 创建空字典、空列表 for i in leadrolelst: datai = df_role2[df_role2['主演'].str.contains(i)] if len(datai) >2: dic_role_lp = {} lp_pre_i = len(datai[datai['豆瓣评分']<4.3])/len(datai) # 计算该主演烂片比例 dic_role_lp['role'] = i dic_role_lp['rolecount'] = len(datai) dic_role_lp['role_lp_pre'] = lp_pre_i lst_role_lp.append(dic_role_lp) # 按照题材遍历数据,得到不同主演的烂片比例 df_role_lp = pd.DataFrame(lst_role_lp) role_lp_top20 = df_role_lp.sort_values(by = 'role_lp_pre',ascending = False).iloc[:20] role_lp_top20 # 筛选出烂片比例TOP20的演员
# 查看特定演员的烂片率 print(df_role_lp[df_role_lp['role'] == '吴亦凡']) df_role2[['电影名称','主演','豆瓣评分']][df_role2['主演'].str.contains('吴亦凡')]
5、不同导演每年电影产量情况是如何的?
① 通过“上映日期”筛选出每个电影的上映年份
② 查看不同导演的烂片比例、这里去除掉拍过10次电影以下的导演
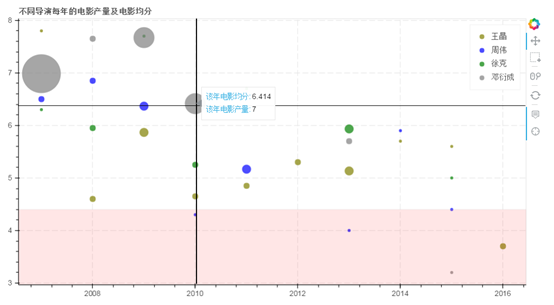
③ 查看不同导演每年的电影产量制作散点图 → 横坐标为年份,纵坐标为每年电影平均分,点大小该年电影数量
** 用bokeh制图
** 横坐标限定为2007-2017年
** 绘制散点图只需要用产出过烂片的导演数据
===>>
① 注意要删除“上映日期”中的空格字符
② 绘制图表时,分开建立数据绘制
#(1) 电影上映时间整理 电影“上映日期”字段整理 → 时间序列; 注意这里要删除“上映日期”中的空格字符 # 年份限定为2007-2017年 df_year = df[['电影名称','导演','豆瓣评分','上映日期']][df['导演'].notnull()] df_year = df_year[df_year['上映日期'].notnull()] df_year['上映日期'] = df_year['上映日期'].str.replace(' ','') # 删除空格字符 df_year['year'] = df_year['上映日期'].str[:4] # 识别年份 df_year = df_year[df_year['year'].str[0] == '2'] # 去除错误数据 df_year['year'] = df_year['year'].astype(np.int) # 年份设置为整型 df_year.head()
# (2)筛选导演 directorlst = [] for i in df_year['导演'].str.replace(' ','').str.split('/'): directorlst.extend(i) # 取出所有电影的主演,并整理成列表; 注意这里要删除“主演”中的空格字符 directorlst = list(set(directorlst)) print('筛选后的导演人数为%i人' % len(directorlst)) print(directorlst) # 列表去重
# (3)查看不同导演的烂片比例 # 这里去除掉拍过10次电影以下的导演 # 年份限定为2007-2017年 lst_dir_lp = [] # 创建空字典、空列表 for i in directorlst: datai = df_year[df_year['导演'].str.contains(i)] if len(datai) >10: dic_dir_lp = {} lp_pre_i = len(datai[datai['豆瓣评分']<4.3])/len(datai) # 计算该主演烂片比例 dic_dir_lp['dir'] = i dic_dir_lp['dircount'] = len(datai) dic_dir_lp['dir_lp_pre'] = lp_pre_i lst_dir_lp.append(dic_dir_lp) # 按照题材遍历数据,得到不同主演的烂片比例 df_dir_lp = pd.DataFrame(lst_dir_lp) df_dir_lp # 查看烂片比例
#(4)不同导演的电影产量及电影均分; 计算不同导演每年的电影产量及电影均分; 这里只看产出过烂片的导演数据 def f3(data,diri): datai = data[data['导演'].str.contains(diri)] # 筛选数据 data_moviecount = datai[['year','电影名称']].groupby('year').count() data_scoremean = datai[['year','豆瓣评分']].groupby('year').mean() df_i = pd.merge(data_moviecount,data_scoremean,left_index = True,right_index = True) df_i.columns = ['count','score'] df_i['size'] = df_i['count']*5 return(df_i) dirdata1 = f3(df_year,'王晶') dirdata2 = f3(df_year,'周伟') dirdata3 = f3(df_year,'徐克') dirdata4 = f3(df_year,'邓衍成') # 分别得到不同导演的数据 dirdata1
# (5)bokeh制图 from bokeh.models.annotations import BoxAnnotation # 导入BoxAnnotation模块 hover = HoverTool(tooltips=[("该年电影均分", "@score"), ("该年电影产量","@count")]) # 设置标签显示内容 p = figure(plot_width=900, plot_height=500, title="不同导演每年的电影产量及电影均分", tools=[hover,'reset,xwheel_zoom,pan,crosshair,box_select']) # 构建绘图空间 source1 = ColumnDataSource(dirdata1) p.circle(x='year',y='score',source = source1,size = 'size',legend="王晶",fill_color = 'olive',fill_alpha = 0.7,line_color = None) # 绘制散点图1 source2 = ColumnDataSource(dirdata2) p.circle(x='year',y='score',source = source2,size = 'size',legend="周伟",fill_color = 'blue',fill_alpha = 0.7,line_color = None) # 绘制散点图2 source3 = ColumnDataSource(dirdata3) p.circle(x='year',y='score',source = source3,size = 'size',legend="徐克",fill_color = 'green',fill_alpha = 0.7,line_color = None) # 绘制散点图3 source4 = ColumnDataSource(dirdata4) p.circle(x='year',y='score',source = source4,size = 'size',legend="邓衍成",fill_color = 'gray',fill_alpha = 0.7,line_color = None) # 绘制散点图4 bg = BoxAnnotation(top=4.4,fill_alpha=0.1, fill_color='red') p.add_layout(bg) # 绘制烂片分隔区域 p.xgrid.grid_line_dash = [10,4] p.ygrid.grid_line_dash = [10,4] p.legend.location = "top_right" # 设置其他参数 show(p)



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人