
关系网络数据可视化:3. 案例:公司职员关系图表 & 导演演员关系网络可视化
1. 公司职员关系图表
节点和边界数据
节点是指每个节点本身的数据,代表公司职工的名称;属性(Country)、分类(Category)和地区(Region,给每个节点定义的属性数据)。文件必须是.csv的格式。
连接线数据,不同的两个点之间的关系,权重(可以用各种方式做一个度量)。节点的数据结构可以是以点的形式,一个行数据是一个节点它有它的属性;边线的数据它每一行是两个点之间的关系。

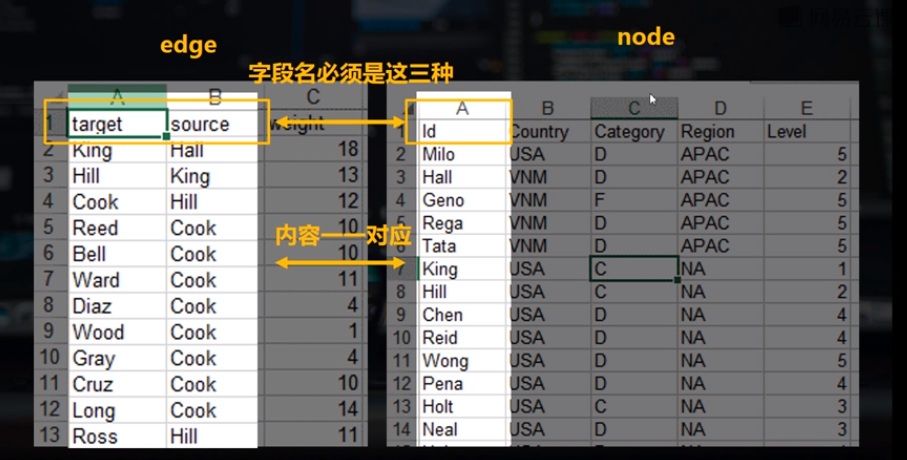
节点数据名第一个字段必须是Id(第一个必须大写,第二个字母d小写),后边的字段Country、Category、Region、Level是可以变的(它们是点的属性);
边线的字段名必须target和source,并且内容是一一对应的(就是target和source所对应的点必须在node文件里边必须是能够对应的上的,否则无法识别) 一个edge代表了点与点间的关系,而node代表每个点的属性,它肯定要有个标签去对应,这个标签就是它的Id名称,
第一步:导入数据,node和edge
节点---node; 边---edge。
第二步:按照不同的国家做一个颜色的界定
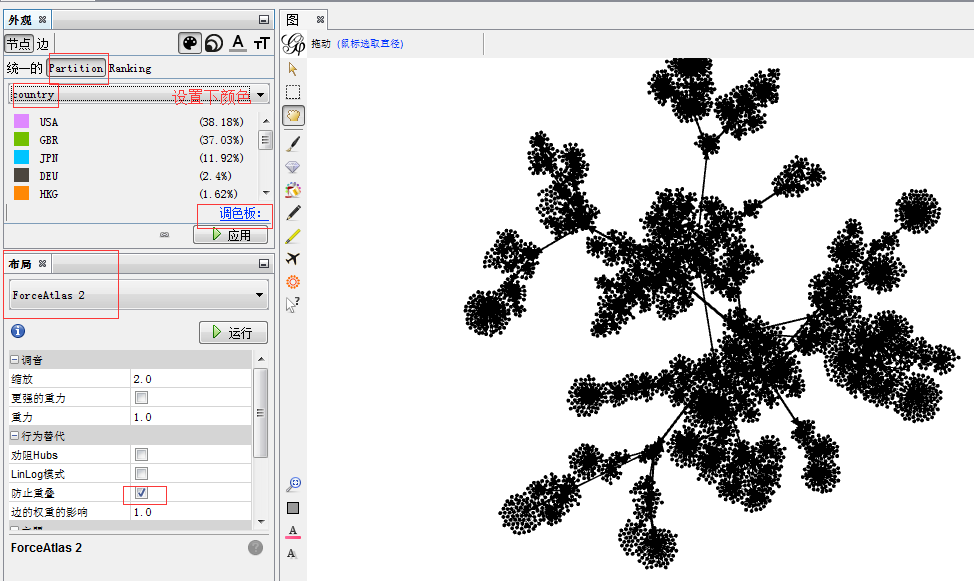
第三步:设置下

节点有多大,里边的字体就有多大。
还是密密麻麻的,节点按照某种关系做一个输出,连出度越大,这个点本身越大。
连出度代表我这个人跟多少人是有关系的;

度就是我这个点跟其他点的连接关系;连出度是往外连接的,连入度是从外边往里边连接的。整个度是两个的求和。
第四步:参数
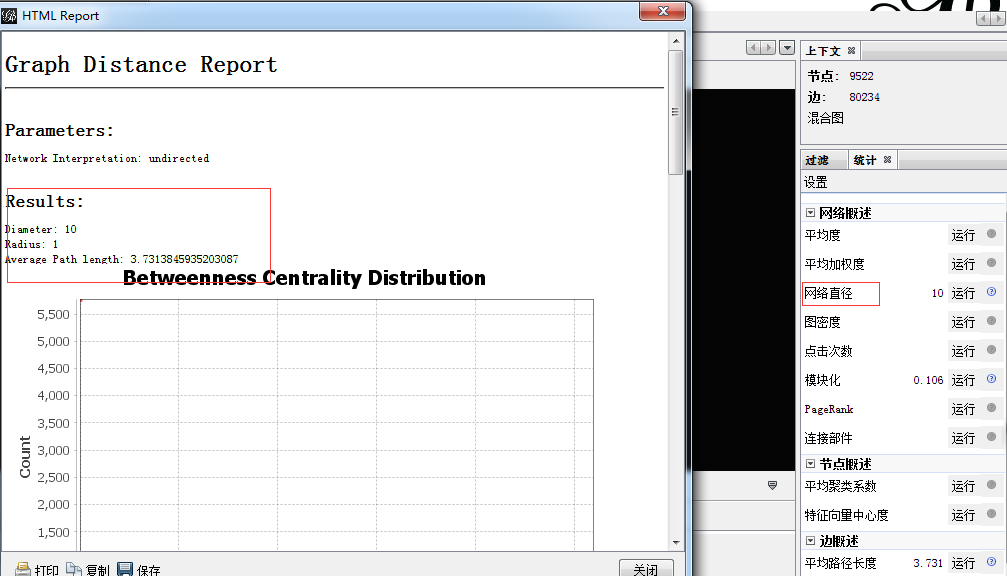
网络直径是点与点之间的最小距离


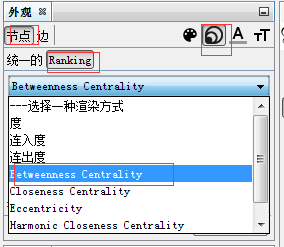
Betweenness Centrality:网络中任意两个点之间的最短路径,如果这个最短 路径都经过某个节点,那么这个节点的最短基数越高。
Closeness centrality
Eccentricity
Harmonic closeness centrality

把布局再调整下: ForceAtlas2 收缩 扩展
Betweenness Centrality中层领导(连接高层领导又连接下层的一个角色);
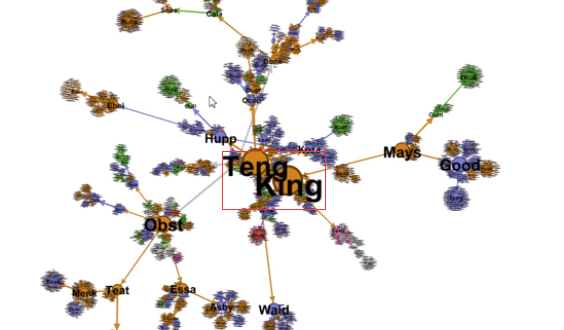
Closeness centrality: 所有跟我有连接的平均值是最短的;在公司中他跟谁都近,但连入度不一定是最高的
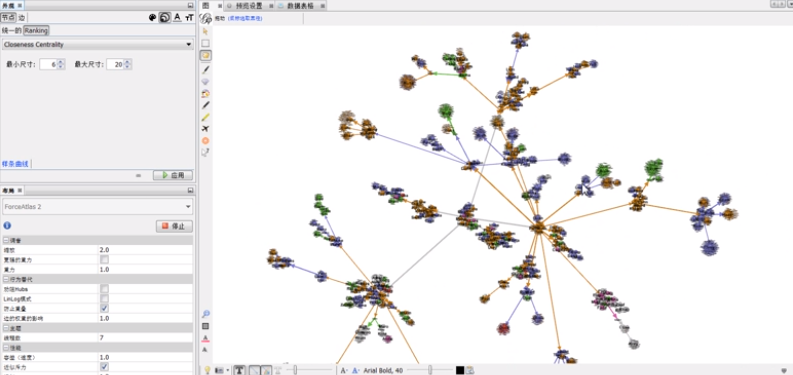
这个不是特别明显,大家的值的区别都不是很大,大小都是差不多大。
2. 案例:导演演员关系网络可视化
如何做一个筛选和数据清洗?通过可视化的方式直接清洗它
主要用到过滤和统计的模块

第一步:
加载数据---->> 数据太多,需要进行筛选和处理,筛选之后,统计计算只会计算筛选下来的内容;
第二步:
进行过滤
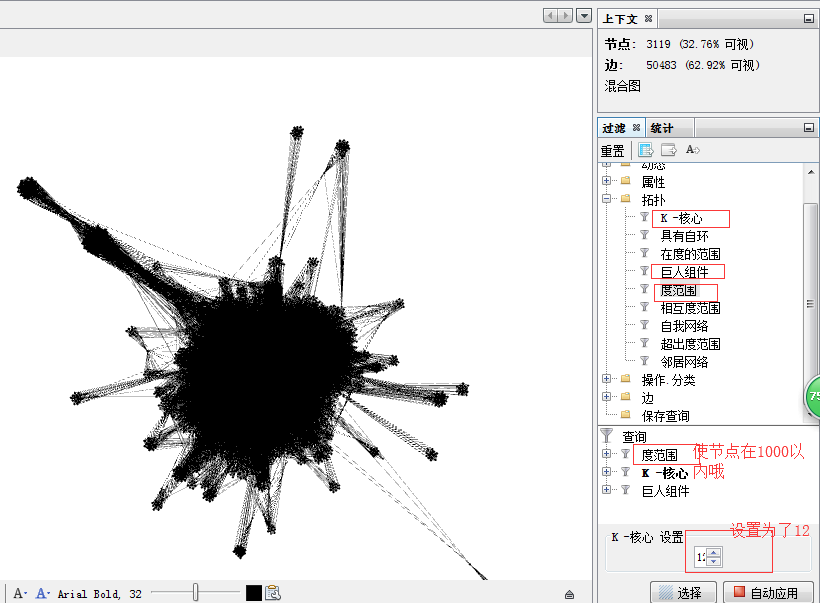
数据清洗
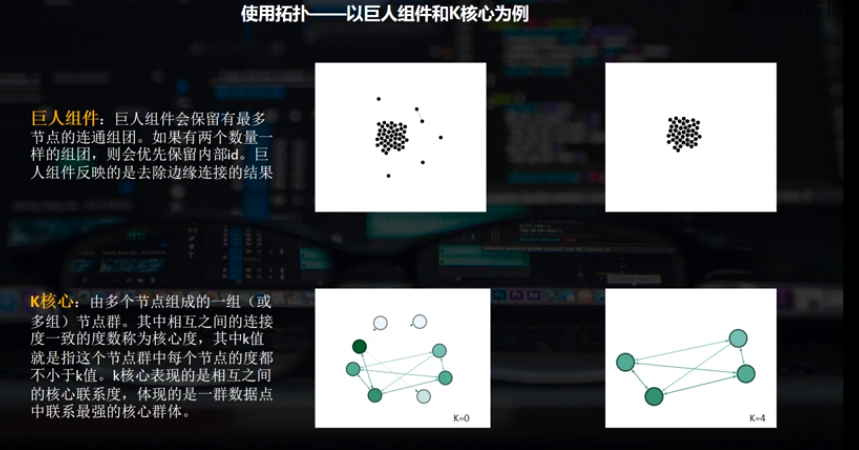
清洗的逻辑有:巨人组件参数和K核心
巨人组件是会保留一个组团中连接最多的那些节点,由于本身又一些连接关系,但是会有一些点没有联系(相当于没有那个参数),由于重力的关系会实现一个簇。巨人组件就会自动的删除周边这些点。
把相互之间的点的度看成它的一个均值,每一个点都有一个度,K核心可以按照这个度做一个筛选,比如K(核心)=0,基本上不会做任何的筛选,度非常小的接线还会保留。
K=4的时候它就会把那些小的接线给去掉了。
通过这两个方法不断去优化这些数据点的个数。节点数尽 量在1000个左右,还可以通过相互度的范围做下一步的筛选。
1000个节点(经验数值)以下的好做运算。
第三步:
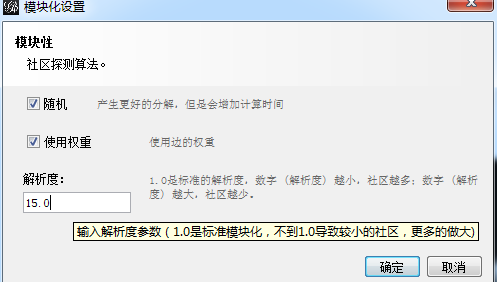
再通过模块化对整个数据做一个聚类,得到里边的模块。最后这个模块就会呈现出我们想要的效果。

在这一步我们需要不断的去调整参数,去做这个设置,解析度越大,簇的社区越少。

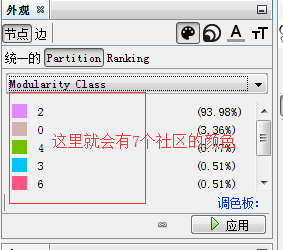
布局 用扩展和ForceAtlas2来进行调节。

哪些点是属于黏度比较高的?算下网络的直径,
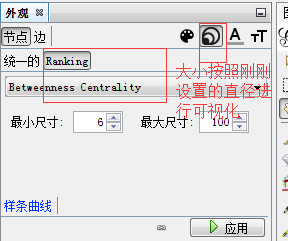

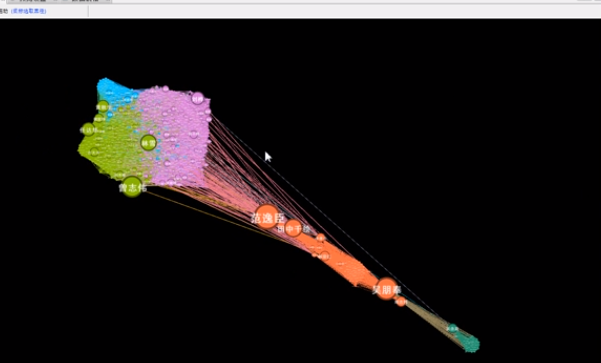
预览

度范围的操作结果如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号