
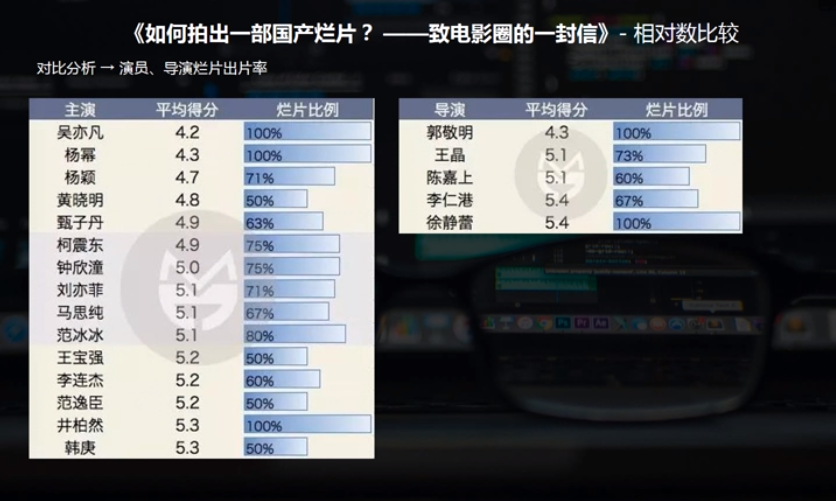
数据特征分析:2.对比分析
对比分析
两个相互联系的数(指标)进行比较(绝对数比较、相对数比较)
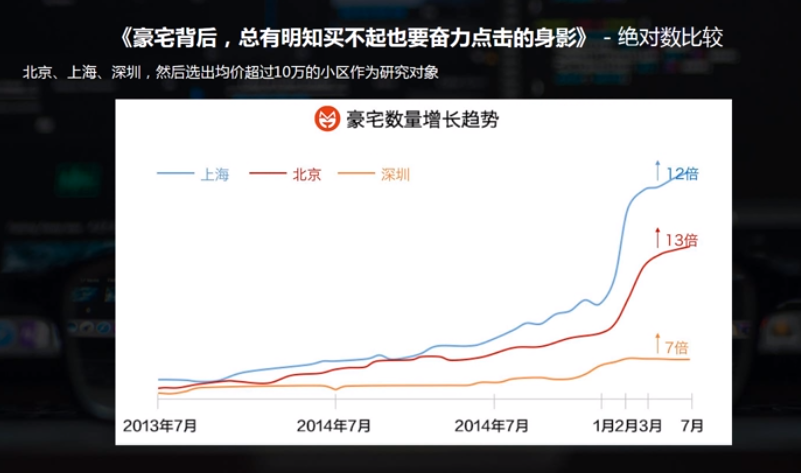
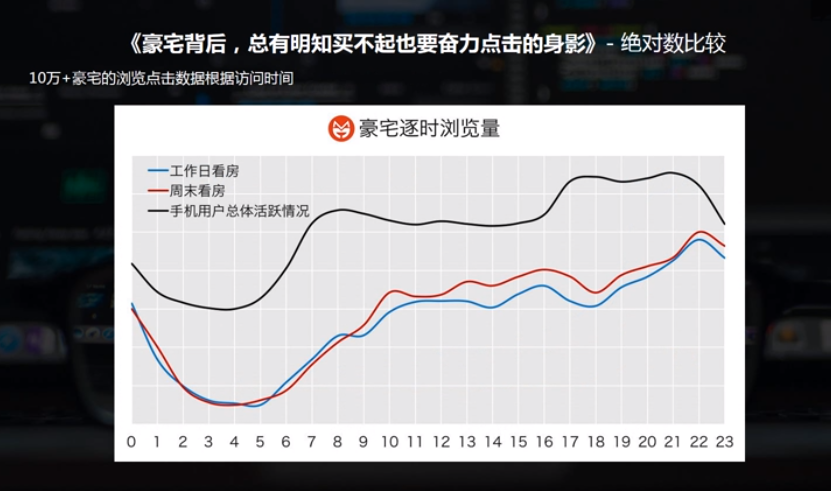
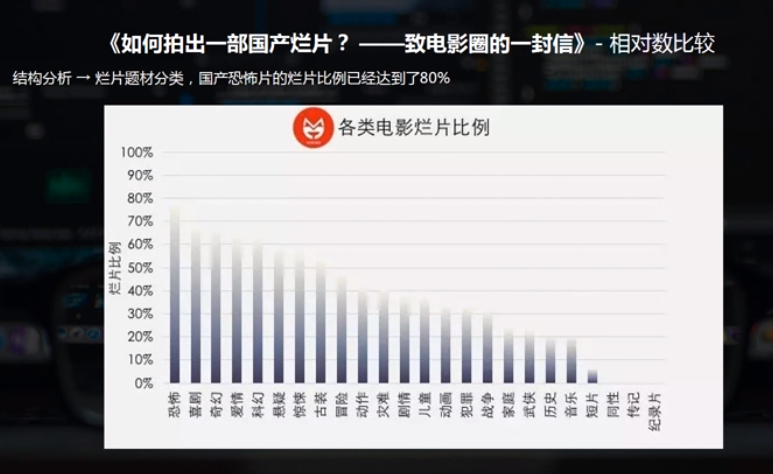
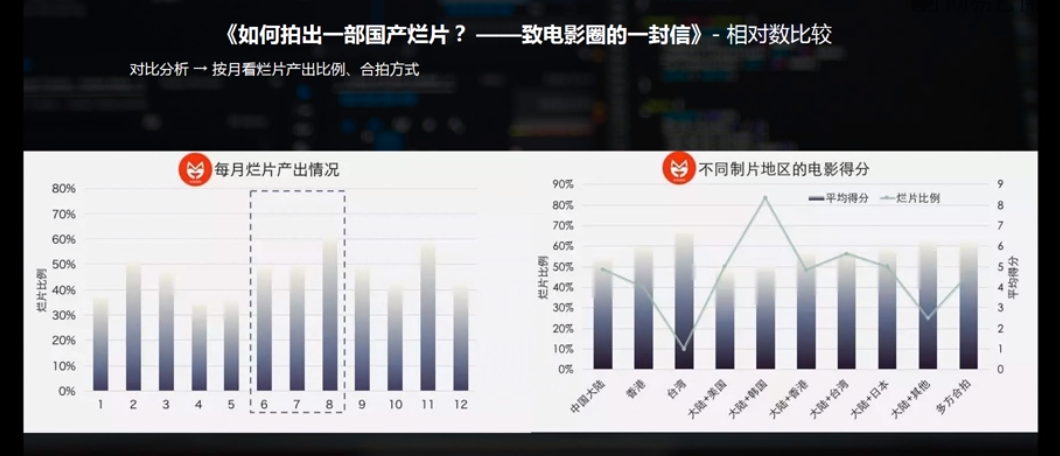
对比分析
对比分析 → 两个互相联系的指标进行比较
绝对数比较(相减) / 相对数比较(相除)
结构分析、比例分析、空间比较分析、动态对比分析
1.绝对数比较 -->相减
相互对比的指标在量级上不能差别过大
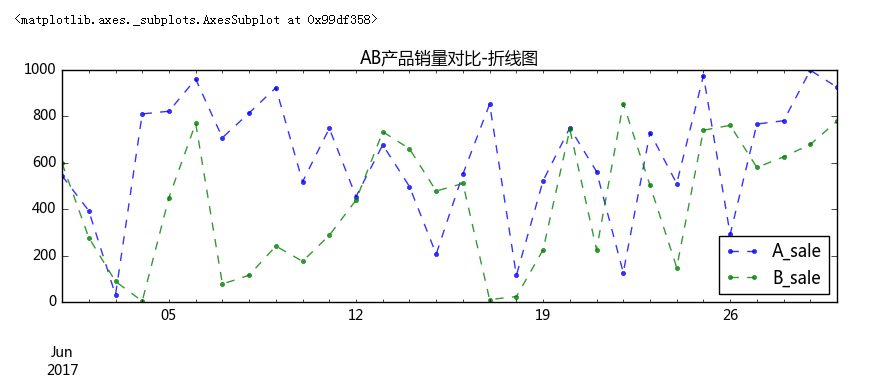
(1)折线图比较
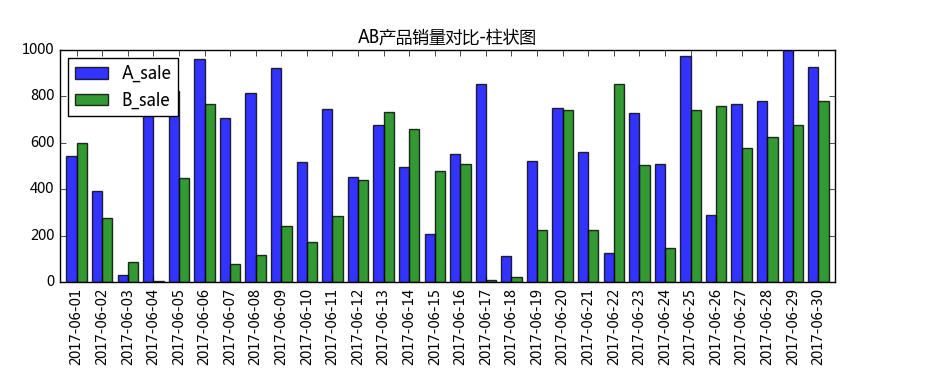
(2)多系列柱状图比较
data.plot(kind='line',style = '--.',alpha = 0.8,figsize = (10,3),title = 'AB产品销量对比-折线图')
data.plot(kind = 'bar', width = 0.8,alpha = 0.8,figsize = (10,3),title = 'AB产品销量对比-柱状图')
import numpy as np import pandas as pd import matplotlib.pyplot as plt % matplotlib inline

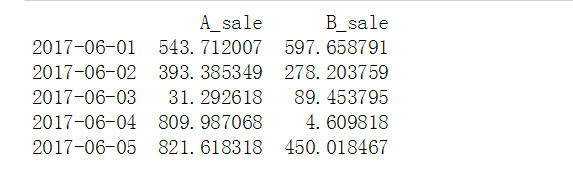
# 1、绝对数比较 → 相减 data = pd.DataFrame(np.random.rand(30,2)*1000, columns = ['A_sale','B_sale'], index = pd.period_range('20170601','20170630')) print(data.head()) # 创建数据 → 30天内A/B产品的日销售额 data.plot(kind='line', style = '--.', alpha = 0.8, figsize = (10,3), title = 'AB产品销量对比-折线图') # 折线图比较 data.plot(kind = 'bar', width = 0.8, alpha = 0.8, figsize = (10,3), title = 'AB产品销量对比-柱状图') # 多系列柱状图比较
绝对值 在一个月中,折线图的曲线
(3)柱状图堆叠图+差值折线图比较
plt.bar(x, y1, width = 1, facecolor = 'yellowgreen') plt.bar(x, y2, width = 1, facecolor = 'lightskyblue')
plt.plot(x, y3, "--go") 差值折线图
#绝对数比较,看它们比较的状况--相减 x = range(len(data)) y1 = data['A_sale'] y2 = -data['B_sale'] #做一个正负堆叠图 fig3 = plt.figure(figsize = (10, 6)) plt.subplots_adjust(hspace = 0.3) #做一下校准, 创建子图及间隔设置。 ax1 = fig3.add_subplot(2, 1, 1) #柱状图创建方式 plt.bar(x, y1, width = 1, facecolor = 'yellowgreen') plt.bar(x, y2, width = 1, facecolor = 'lightskyblue') plt.title('AB产品销量对比-堆叠图') plt.grid() plt.xticks(range(0,30,6)) ax1.set_xticklabels(data.index[::6]) # x轴日期、间隔 ax2 = fig3.add_subplot(2, 1, 2) y3 = data['A_sale'] - data['B_sale'] #折线图,做减法 plt.plot(x, y3, "--go") plt.grid() plt.title('AB产品销量对比-差值折线') plt.xticks(range(0,30,6)) plt.axhline(0, color = 'r', linestyle = '--', alpha = 0.8) # 添加y轴参考线 ax2.set_xticklabels(data.index[::5]) #加个标签。 # 创建差值折线图


可以看到它们大概一个月中销量的对比。
绝对数的比较更多的是两个样本量差不多,但更多的时候用的是相对数,相对数更多的时候是做一个结构性比较。
2、相对数比较 → 相除
有联系的指标综合计算后的对比,数值为相对数
结构分析、比例分析、空间比较分析、动态对比分析
(1)结构分析 频率对比
在分组基础上,各组总量指标与总体的总量指标对比,计算出各组数量在总量中所占比重
反映总体的内部结构
data = pd.DataFrame({'A_sale':np.random.rand(30)*1000,
'B_sale':np.random.rand(30)*200},
index = pd.period_range('20170601','20170630'))
print(data.head())
print('------')
# 创建数据 → 30天内A/B产品的日销售额
# A/B产品销售额量级不同
data['A_per'] = data['A_sale'] / data['A_sale'].sum() #A_sale的频率
data['B_per'] = data['B_sale'] / data['B_sale'].sum() #计算出每天的营收占比,B_sale的频率
data['A_per%'] = data['A_per'].apply(lambda x:"%.3f%%" % (x*100))
data['B_per%'] = data['B_per'].apply(lambda x:"%.3f%%" % (x*100)) #转换为百分数
data.head()

能看绝对值的,看相对值肯定是没错的,看相对值就已经抛开了相对值的影响,趋势对比、完成度,
fig,axes = plt.subplots(2,1,figsize = (10,6),sharex=True) data[['A_sale','B_sale']].plot(kind='line',style = '--.',alpha = 0.8,ax=axes[0]) axes[0].legend(loc = 'upper right') data[['A_per','B_per']].plot(kind='line',style = '--.',alpha = 0.8,ax=axes[1]) axes[1].legend(loc = 'upper right') # 绝对值对比较难看出结构性变化,通过看销售额占比来看售卖情况的对比 # 同时可以反应“强度” → 两个性质不同但有一定联系的总量指标对比,用来说明“强度”、“密度”、“普遍程度” # 例如:国内生产总值“元/人”,人口密度“人/平方公里”
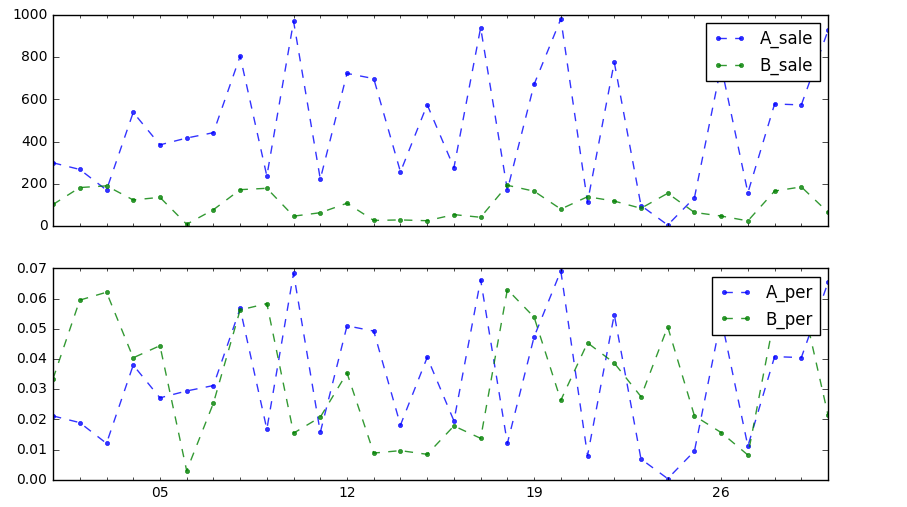
按总量做一个对比,也能看出大概趋势,按百分比就好比较了(每一天中两个产品销量的对比)。结构分析反映的其实是跟总量之间的关系,可以说明强度、硬度
(2)比例分析 相比做除法
它的核心在于通过多个变量或者说不同的变量之间的相比,比之后的新的变量,这个新变量赋予新的意义。比如说男女比例的比值可以看出其他方面。
比如人的流出占比和资本的流出占比
# 在分组的基础上,将总体不同部分的指标数值进行对比,其相对指标一般称为“比例相对数”
# 比例相对数 = 总体中某一部分数值 / 总体中另一部分数值 → “基本建设投资额中工业、农业、教育投资的比例”、“男女比例”...
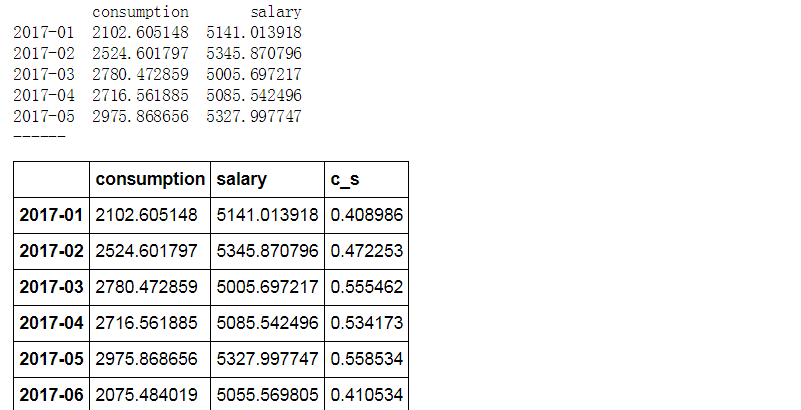
# 2、相对数比较 → 相除 # (2)比例分析 data = pd.DataFrame({'consumption':np.random.rand(12)*1000 + 2000, 'salary':np.random.rand(12)*500 + 5000}, index = pd.period_range('2017/1','2017/12',freq = 'M')) print(data.head()) print('------') # 创建数据 → 某人一年内的消费、工资薪水情况 # 消费按照2000-3000/月随机,工资按照5000-5500/月随机 data['c_s'] = data['consumption'] / data['salary'] #一年的消费占比情况; 比例相对数 --->> 消费收入比 data data['c_s'].plot.area(color = 'green', alpha = 0.5, ylim = [0.3, 0.6], figsize = (8, 3), grid = True) #创建面积图去表达 data
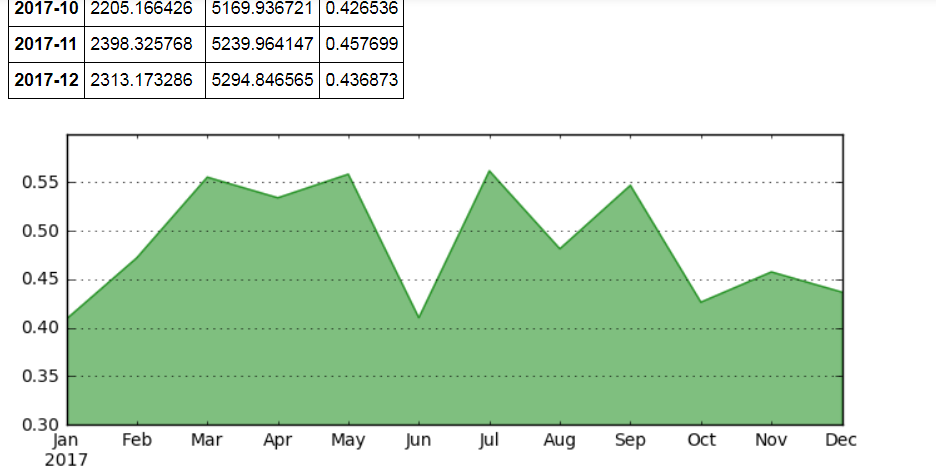
(3)空间比较分析 (横向)
比如说同样的2017年北京和深圳膜拜单车使用量,空间是比较抽象的更多的是在时间相同的情况下,不同的元素的比较。
同一时间内不同空间(这四个产品)的相互比较
同类现象在同一时间不同空间的指标数值进行对比,反应同类现象在不同空间上的差异程度和现象发展不平衡的状况
空间比较相对数 = 甲空间某一现象的数值 / 乙空间同类现象的数值
一个很现实的例子 → 绝对数来看,我国多经济总量世界第一,但从人均水平来看是另一回事
data.sum().plot(kind = 'bar', color = ['r', 'g', 'b', 'k'], alpha = 0.8, grid = True) 同一个月内
data[:10].plot(kind = 'bar',color = ['r','g','b','k'], alpha = 0.8, grid = True, figsize = (12,4),width = 0.8) 同一天内
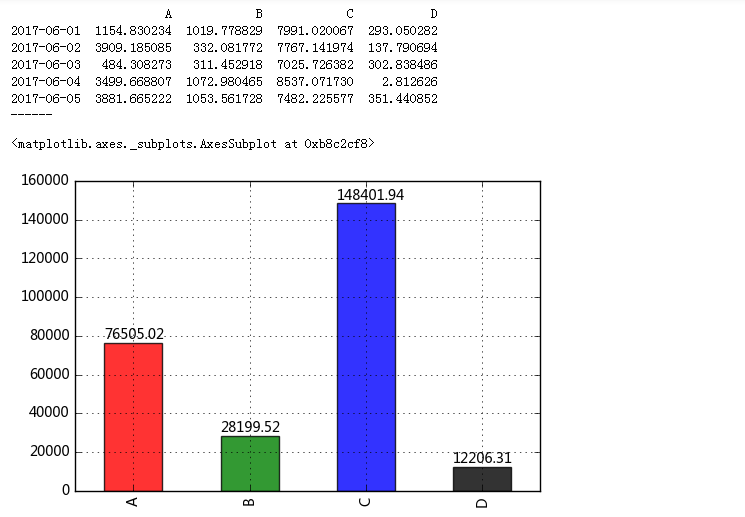
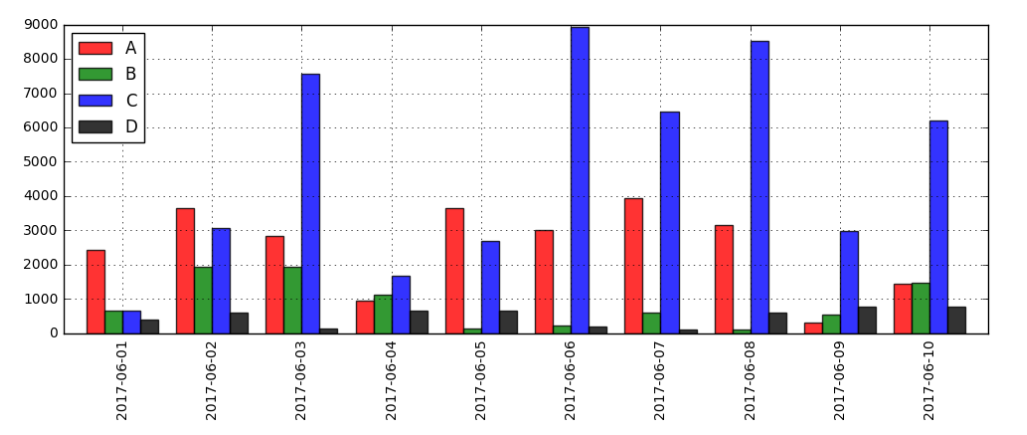
# 2、相对数比较 → 相除 # (3)空间比较分析(横向对比分析) data = pd.DataFrame({'A':np.random.rand(30)*5000, 'B':np.random.rand(30)*2000, 'C':np.random.rand(30)*10000, 'D':np.random.rand(30)*800}, index = pd.period_range('20170601','20170630')) print(data.head()) print('------') # 创建数据 → 30天内A/B/C/D四个产品的销售情况 # 不同产品的销售量级不同
#同一时间(每个月内) data.sum().plot(kind = 'bar', color = ['r', 'g', 'b', 'k'], alpha = 0.8, grid = True)#求和得到一个柱形图,4个产品的不同营销情况 for i, j in zip(range(4), data.sum()): plt.text(i - 0.25, j + 2000, '%.2f'% j, color = 'k') #通过柱状图做横向比较, ---->> 4个产品的销售额总量 #同一时间(每一天) data[:10].plot(kind = 'bar',color = ['r','g','b','k'], alpha = 0.8, grid = True, figsize = (12,4),width = 0.8) # 多系列柱状图,横向比较前十天4个产品的销售额。 # 关于同比与环比 # 同比 → 产品A在2015.3和2016.3的比较(相邻时间段的同一时间点) # 环比 → 产品A在2015.3和2015.4的比较(相邻时间段的比较) # 如何界定“相邻时间段”与“时间点”,决定了是同比还是环比
同比和环比都是在时间点上不一样,都是类似同一个内容在不同时间的比较;同比更多的是去年的今天和今年的今天的比较,环比是今年每个时间段的比较,
(4)动态对比分析(纵向)
在时间层面,同一个东西在不同时间轴上进行对比,反映的是变化、速度、趋势
同一现象在不同时间上的指标数值进行对比,反应现象的数量随着时间推移而发展变动的程度及趋势
最基本方法,计算动态相对数 → 发展速度
动态相对数(发展速度) = 某一现象的报告期数值 / 同一现象的基期数值
基期:用来比较的基础时期
报告期:所要研究的时期,又称计算期
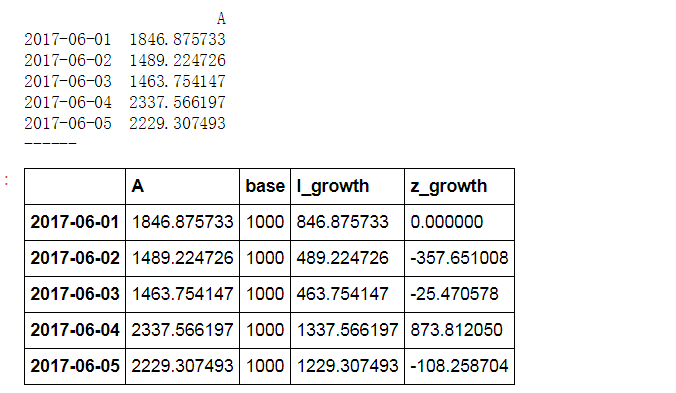
# 2、相对数比较 → 相除 (4)动态对比分析(纵向对比分析) data = pd.DataFrame({'A':np.random.rand(30)*2000+1000}, index = pd.period_range('20170601','20170630')) print(data.head()) print('------') # 创建数据 → 30天内A产品的销售情况 data['base'] = 1000 # 假设基期销售额为1000,后面每一天都为计算期
#累计增长量 = 报告期水平 - 固定基期水平
data['l_growth'] = data['A'] - data['base'] #每一天减去它就可以了 data
#逐期增长量= 报告期水平 - 报告期前一期水平
data['z_growth'] = data['A'] - data.shift(1)['A'] #每一天每个周期跟上个增长量的对比;shift移动一行 data.fillna(0, inplace = True) #替换缺失值 data[['l_growth','z_growth']].plot(figsize = (10,4),style = '--.',alpha = 0.8) plt.axhline(0,hold=None,color='r',linestyle="--",alpha=0.8) # 添加y轴参考线 plt.legend(loc = 'lower left') plt.grid() # 通过折线图查看增长量情况 data.head()
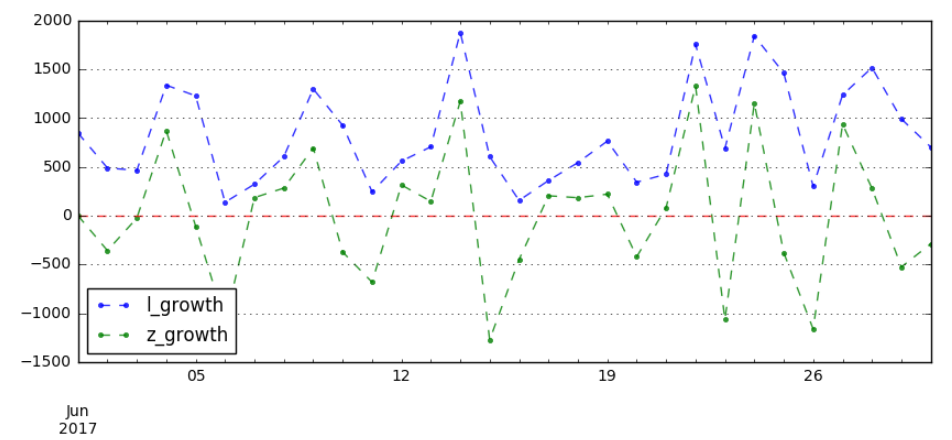
累计增长量和逐期增长量的大小差别,如果是累计增长量它本身是跟着机器相比较,效益好每天都是增长的;
逐期增长量可以看到每天的一个变化频率和变动趋势了,如果今天的增长量和昨天的增长量比下降了就会是个负数。如果把逐期增长量加在一起,如果大于0,就是往上长的。
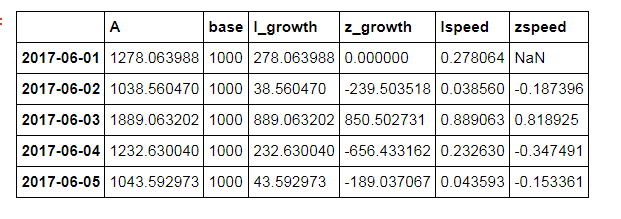
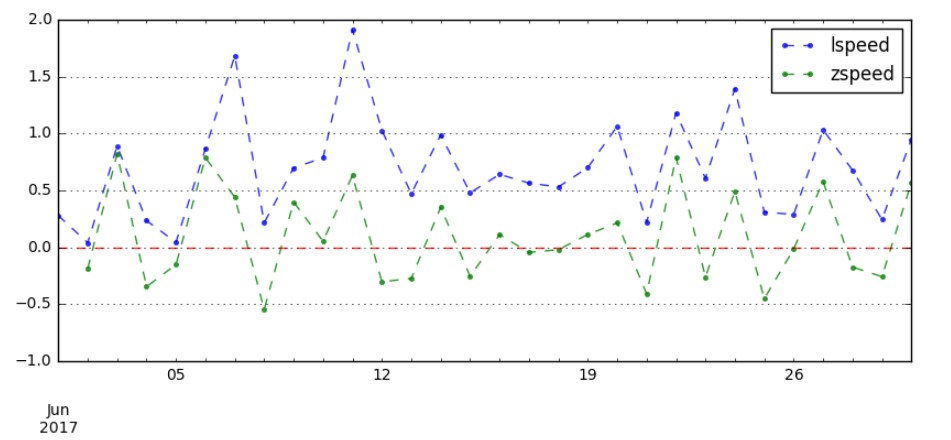
#定基增长速度 data['lspeed'] = data['l_growth'] / 1000 #环比增长速度 data['zspeed'] = data['z_growth'] / data.shift(1)['A']#报告期的水平/上期的水平 data[['lspeed','zspeed']].plot(figsize = (10,4),style = '--.',alpha = 0.8) plt.axhline(0,hold=None,color='r',linestyle="--",alpha=0.8) # 添加y轴参考线 plt.grid() data.head()



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人