
2.Django|简介与静态文件| URL控制器
1、简介
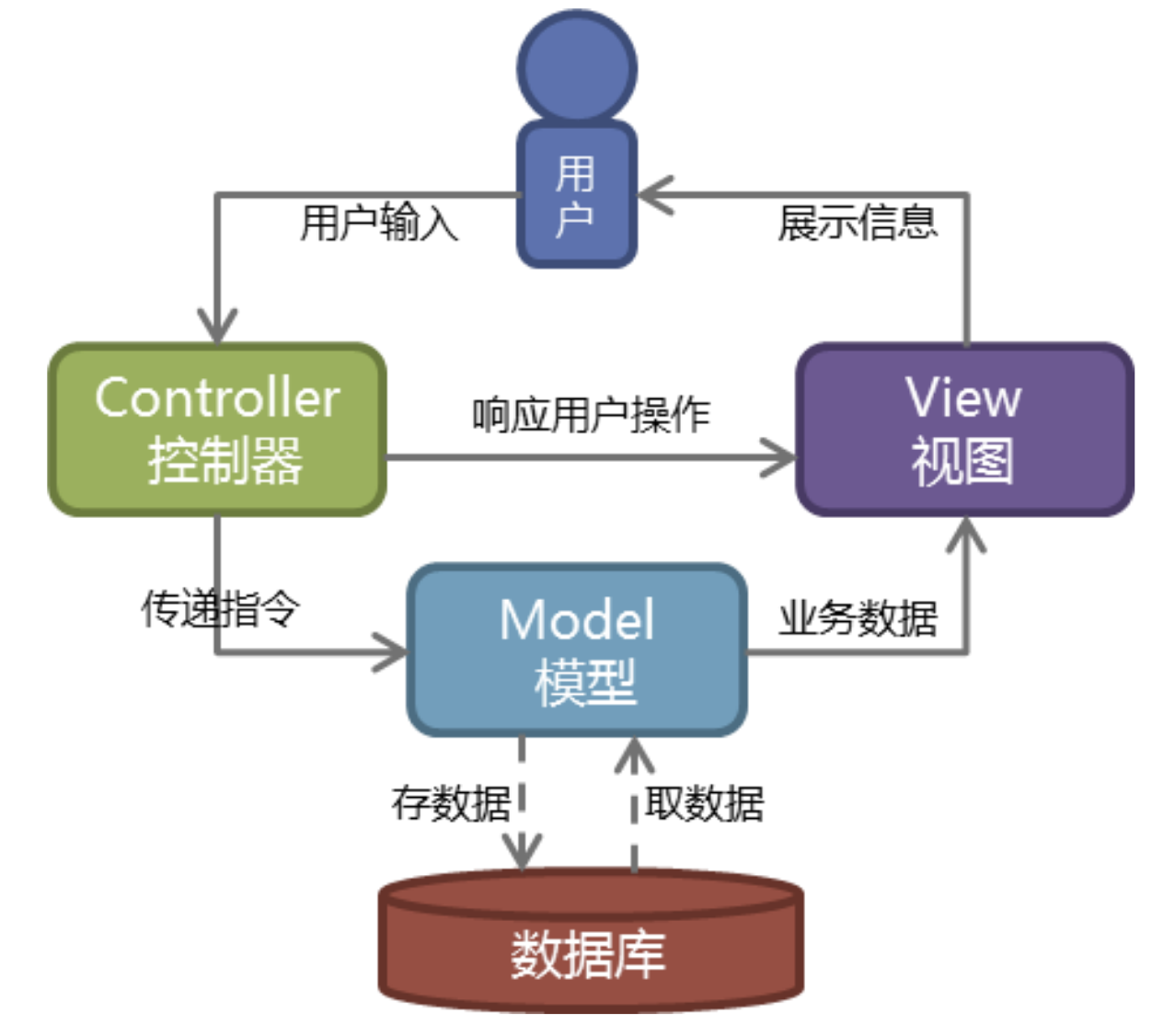
MVC
Web服务器开发领域里著名的MVC模式,所谓MVC就是把Web应用分为模型(M),控制器(C)和视图(V)三层,他们之间以一种插件式的、松耦合的方式连接在一起,模型负责业务对象与数据库的映射(ORM),视图负责与用户的交互(页面),控制器接受用户的输入调用模型和视图完成用户的请求。
MTV
Django的MTV模式本质上和MVC是一样的,也是为了各组件间保持松耦合关系,只是定义上有些许不同,Django的MTV分别是值:
M 代表模型(Model):负责业务对象和数据库的关系映射(ORM)。
T 代表模板 (Template):负责如何把页面展示给用户(html)。
V 代表视图(View):负责业务逻辑,并在适当时候调用Model和Template。
除了以上三层之外,还需要一个URL分发器,它的作用是将一个个URL的页面请求分发给不同的View处理,View再调用相应的Model和Template,MTV的响应模式如下所示
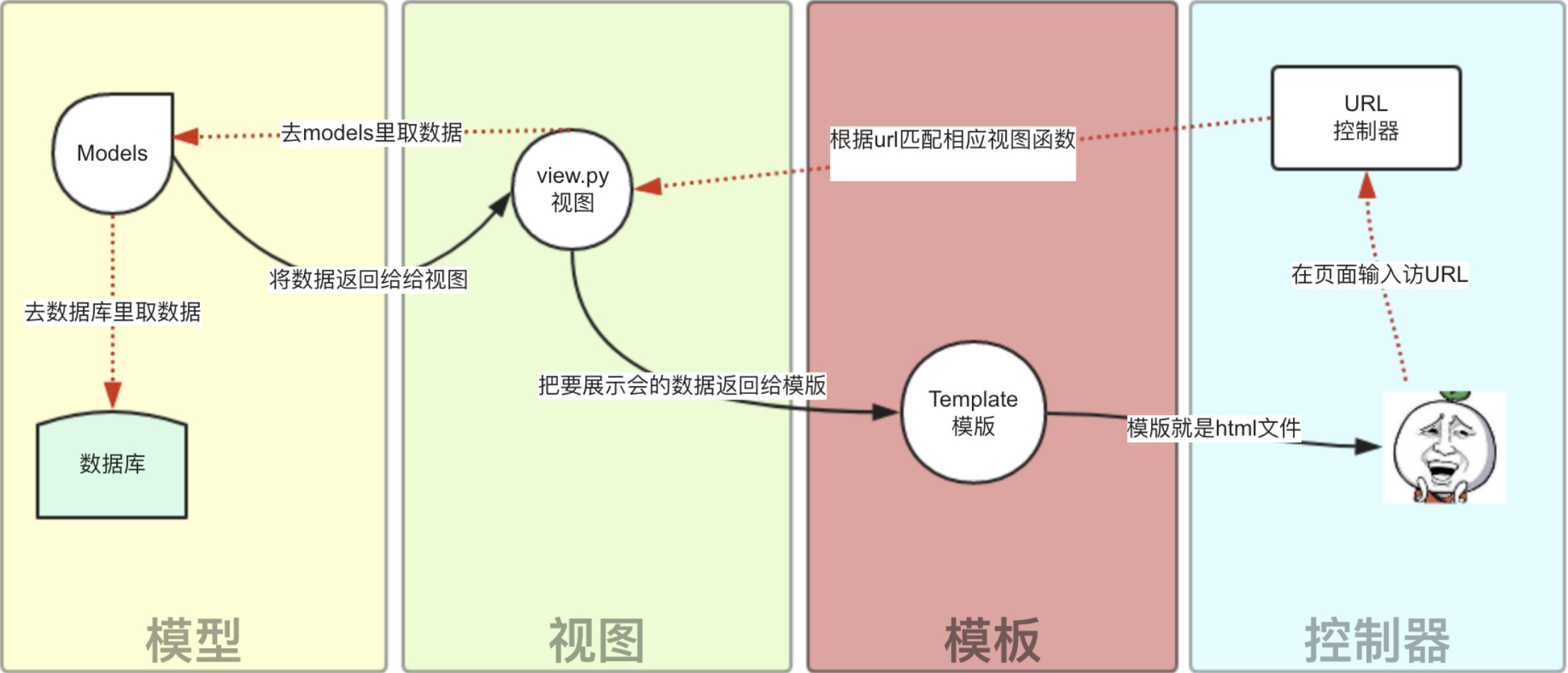
一般是用户通过浏览器向我们的服务器发起一个请求(request),这个请求回去访问视图函数,(如果不涉及到数据调用,那么这个时候视图函数返回一个模板也就是一个网页给用户),视图函数调用模型,模型去数据库查找数据,然后逐级返回,视图函数把返回的数据填充到模板中空格中,最后返回网页给用户。
下载安装创建 (2.0以上版本与1.0版本还是差别挺大的)
pip3 install django=2.0.1
查看安装到哪里了呢
创建一个Django项目(在终端里边,在pycharm里边创建)
django-admin.py startproject mysite
当前目录下会生成mysite的工程,目录结构如下:
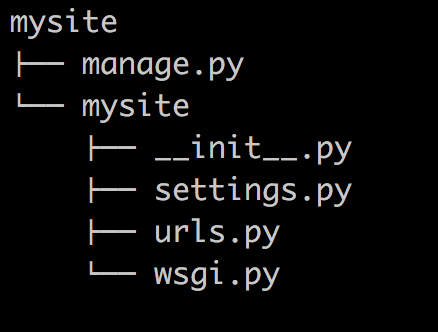
- manage.py ----- Django项目里面的工具,通过它可以调用django shell和数据库等,与Django交互。
- settings.py ---- 包含了项目的默认设置,包括数据库信息,调试标志以及其他一些工作的变量。
- urls.py ----- 负责把URL模式映射到应用程序。
在mysite目录下创建应用
python manage.py startapp blog
python manage.py startapp app01 #创建第二个应用
启动django项目
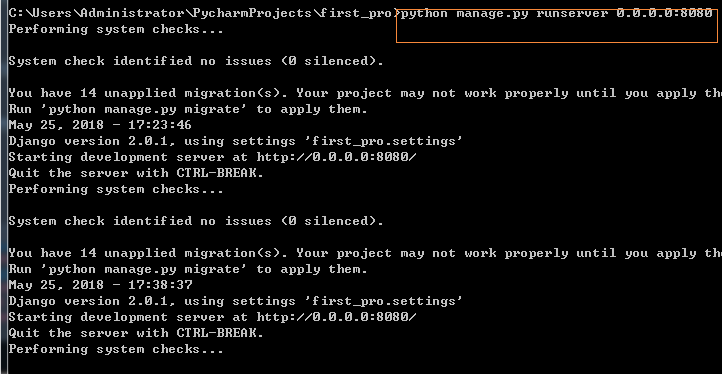
python manage.py runserver 8080 #默认本机的8080端口,也可以是其他端口
在pycharm里边创建
2.静态文件配置
Django文件 :demo
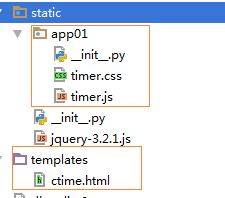

如果是报这样一个错:
Failed to load resource: the server responded with a status of 404 (Not Found)
则是没有配置静态文件路径,加上上边 STATICFILES_DIRS = [os.path.join(BASE_DIR, "static"),] 即可。
这样设置完之后就可以访问到了http://127.0.0.1:8000/static/jquery-3.2.1.js 从路径URL中配置static,然后找到文件夹下的static文件。
所有的静态文件都在static里边
css、js都写到静态文件里边
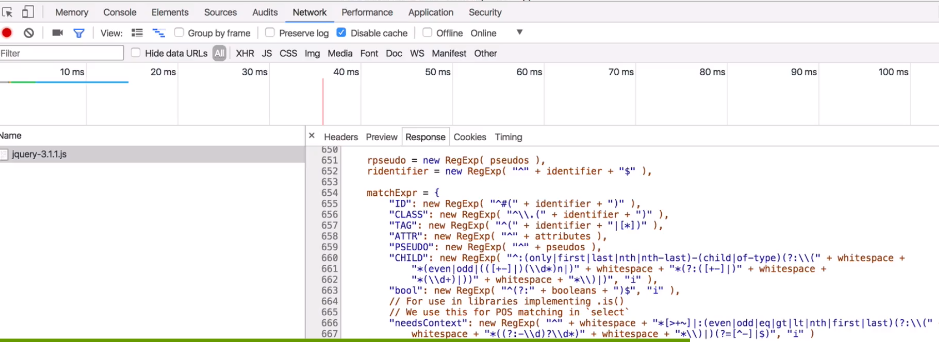
views.py
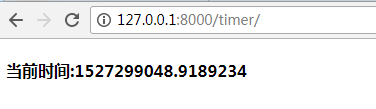
from django.shortcuts import render # Create your views here. def timer(request): import time ctime = time.time() return render(request, "ctime.html", {"ctime":ctime})
render方法就是去渲染一个方法,帮我们去找templates下面的文件,读出数据返回;同时它还把这个ctime变量嵌套到了ctime.html这个页面中了
{{"ctime": ctime}} ,{ { } } 就是一种特殊语法,把视图函数里边的变量传到html页面中
templates/ctime.html

<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> {# <style>#} {# h4{#} {# color: red;#} {# }#} {# </style>#} <script src="/static/jquery-3.2.1.js"></script> {# 客户端浏览器执行的时候它找不到这个文件,得配置一个static路径 #} <link rel="stylesheet" href="/static/app01/timer.css"> </head> <body> <h4>hi当前时间为:{{ ctime }}</h4> <script src="/static/app01/timer.js"></script> </body> {# <script>#} {# $('h4').click(function () {#} {# $(this).css("color","green")#} {# })#} {# </script>#} </html>
static/app01/ timer.css
h4{
color: red;
}
static/app01/timer.js
$('h4').click(function () { $(this).css("color","green") })
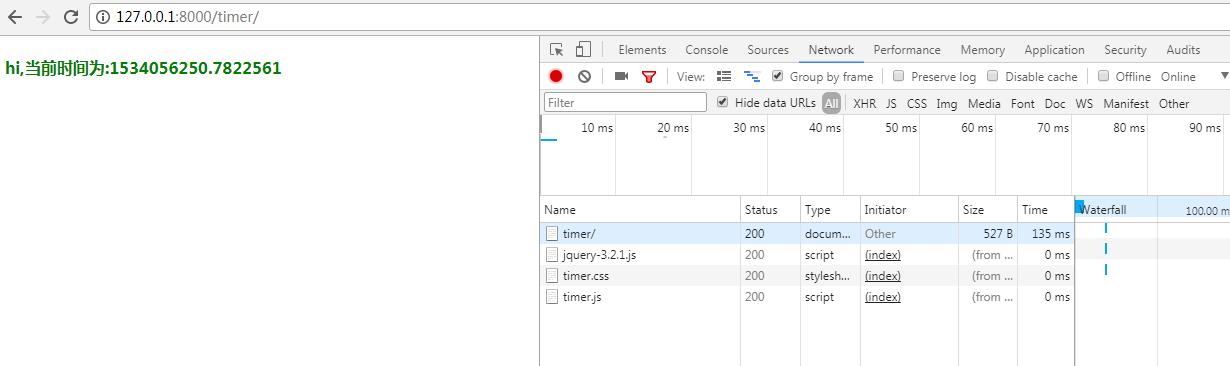
整个流程:用户输入http://127.0.0.1:8000/timer/交给URL控制器(控制行为),匹配到就执行timer视图函数(一旦匹配成功,path这个函数方法帮你去调这个匹配到的函数,调的时候就会给你传一个request参数,所有的请求信息数据都封装在了request里边),这个视图函数在app01里的views里边找到timer方法(timer方法做逻辑处理);取出来一个叫ctimer(之前我们是open这个文件然后再返回,现在通过一个render方法把这所有的事情都做了。)
3、Django-2的路由层
URL配置(URLconf)就像django所支撑网站的目录。它的本质是URL与要为该URL调用的视图函数之间的映射表,你就是以这种方式告诉django,对于客户端发来的某个RUL调用哪一段逻辑代码对应执行。
django文件 first_pro
3.1简单的路由配置
re_path是1.0版本的,path是2.0版本的,2.0既支持1.0的又支持它自己特殊的语法
import re
re.search(匹配规则,待匹配项);^是以什么开头,$是以什么结尾;
re.search(
'^articles/2003/$',articles/2003/(必须输入这个了就)
)
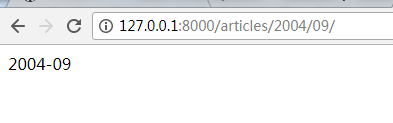
^articles/([0-9]{4})/$是分组匹配,如articles/2008(路径匹配和视图函数是多对一的关系;)
^articles/([0-9]{4})/([0-9]{2})/$ 如articles/2008/12
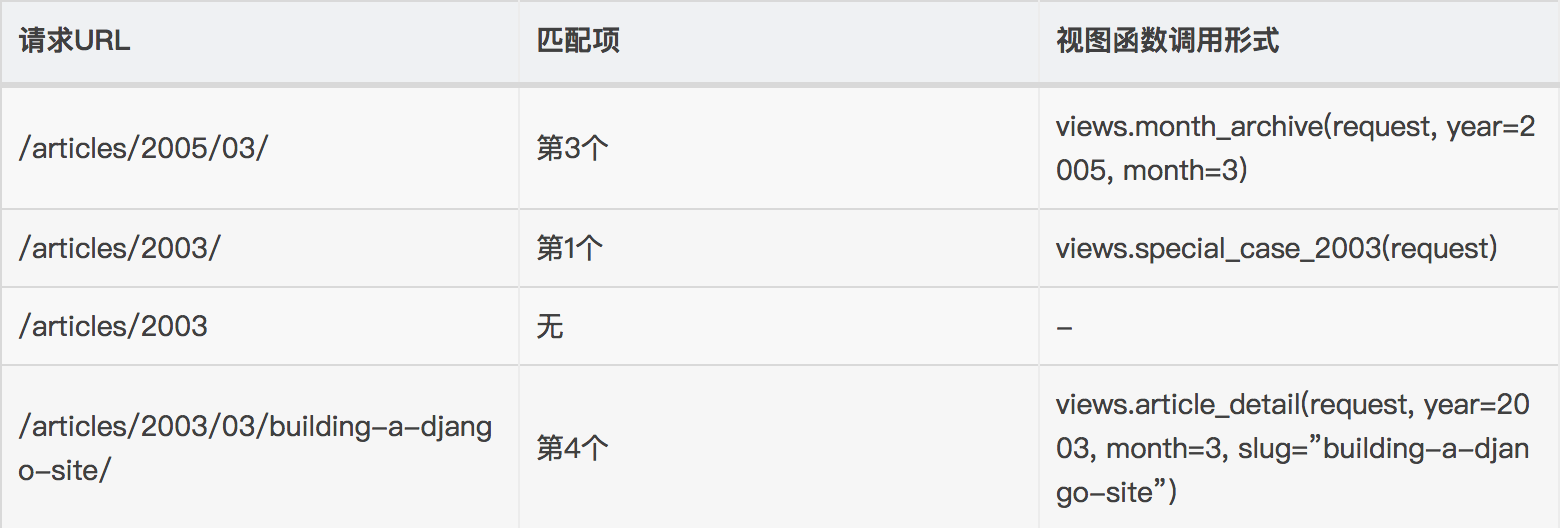
^articles/([0-9]{4})/([0-9]{2})/([0-9]+)/$
from django.contrib import admin from django.urls import path, re_path from app01 import views urlpatterns = [ path('admin/', admin.site.urls), path('timer/', views.timer), #控制行为找到这个视图函数,一旦匹配成功之后,就会传一个request的信息,浏览器中发生的请求信息都在这里边;views.timer(request) #路由配置: 路径 -----> 视图函数 re_path(r'^articles/2003/$', views.special_case_2003), #special_case_2003(request) re_path(r'^articles/([0-9]{4})/$', views.year_archive), #year_archive(request,1999) 传几个参数就要接收几个参数;跟视图函数是多对一;须严格限定住以它开头以它结尾,不要等它匹配完就不走下一步了 re_path(r'^articles/([0-9]{4})/([0-9]{2})/$', views.month_archive), #month_archiverequest,1999,12) # re_path(r'^articles/([0-9]{4})/([0-9]{2})/([0-9]+)/$', views.article_detail), ]
HttpResponse是响应对象,是要写字符串的在这里一定定义的是响应体。响应头、响应首行已经被Django的wsgiref处理了;你想在这个页面中看什么内容,就在
HttpResponse里边写什么内容就可以了。
from django.shortcuts import render,HttpResponse # Create your views here. def timer(request): #这个是逻辑行为,逻辑行为直接找到这个文件 import time ctime = time.time() return render(request, "timer.html", {"date":ctime}) #render方法,由它去找这个文件;不需要写路径,它会自己找 #render找到这个html,打开取出这里边的数据,同时把这个变量嵌套在那个位置 def special_case_2003(request): return HttpResponse("special_case_2003") def year_archive(request, year): return HttpResponse(year) def month_archive(request, year, month): return HttpResponse(year + "-" + month )
注意:
- 若要从URL 中捕获一个值,只需要在它周围放置一对圆括号。
- 不需要添加一个前导的反斜杠,因为每个URL 都有。例如,应该是
^articles而不是^/articles。 - 每个正则表达式前面的'r' 是可选的但是建议加上。它告诉Python 这个字符串是“原始的” —— 字符串中任何字符都不应该转义
3.2有名分组
(可以避免两个url中所匹配的项混淆,代码是从上往下执行的,就先匹配上边匹配到的,如果下面的utl也匹配到了就不再走了,可以使用^和$)
上面的示例使用简单的、没有命名的正则表达式组(通过圆括号)来捕获URL 中的值并以位置 参数传递给视图。在更高级的用法中,可以使用命名的正则表达式组来捕获URL 中的值并以关键字 参数传递给视图。
在Python 正则表达式中,命名正则表达式组的语法是(?P<name>pattern),其中name 是组的名称,pattern 是要匹配的模式。
下面是以上URLconf 使用命名组的重写:
from django.urls import path,re_path from app01 import views urlpatterns = [ #这里边传了几个参数,相对应的视图函数就要传几个参数。 re_path(r'^articles/2003/$', views.special_case_2003), re_path(r'^articles/(?P<year>[0-9]{4})/$', views.year_archive), #year_archive(request,year=2009) re_path(r'^articles/(?P<year>[0-9]{4})/(?P<month>[0-9]{2})/$', views.month_archive), #year_archive(request,year=1028,month=12) re_path(r'^articles/(?P<year>[0-9]{4})/(?P<month>[0-9]{2})/(?P<day>[0-9]{2})/$', views.article_detail), #(request,year=2018,month=08,day=08) ]
re_path(r'^articles/(?P<y>[0-9]{4})/(?P<m>[0-9]{2})/$', views.month_archive), #month_archive(request,y=1999,m=12);这里边传了3个参数,视图函数就要接收3个参数 相对应的视图函数 ------->>> def month_archive(request,m, y): #把它位置捣乱,就乱了;可以给每个组起个名字固定住;一定要按关键字来,是那个名字;这里形参必须是m 和 y,不能写成month或者year print(m) #12 print(type(m)) print(y) print(type(y)) #m = int(m) return HttpResponse(y + "-" + m )
这个实现与前面的示例完全相同,只有一个细微的差别:捕获的值作为关键字参数而不是位置参数传递给视图函数。
在实际应用中,这意味你的URLconf 会更加明晰且不容易产生参数顺序问题的错误 —— 你可以在你的视图函数定义中重新安排参数的顺序。当然,这些好处是以简洁为代价;
3.3路由分发
全局不应该写url,它应做分发。
把全局的urls.py复制到app01的应用里边一份,然后把全局的path那部分给删掉。全局里边(也就是first_pro里边的urls)的针对app01的re_path给删掉。
appo1/urls.py(app01里边的)
from django.contrib import admin from django.urls import path, re_path from app01 import views urlpatterns = [ #路由配置: 路径 -----> 视图函数 re_path(r'^articles/2003/$', views.special_case_2003), #special_case_2003(request) re_path(r'^articles/([0-9]{4})/$', views.year_archive), #year_archive(request,1999) 传几个参数就要接收几个参数;跟视图函数是多对一;须严格限定住以它开头以它结尾,不要等它匹配完就不走下一步了 # re_path(r'^articles/([0-9]{4})/([0-9]{2})/$', views.month_archive), #month_archive(request,1999,12) re_path(r'^articles/(?P<y>[0-9]{4})/(?P<m>[0-9]{2})/$', views.month_archive), #month_archive(request,y=1999,m=12);这样函数的形参就可以颠倒位置了 # re_path(r'^articles/([0-9]{4})/([0-9]{2})/([0-9]+)/$', views.article_detail), ]
first_pro/urls.py(全局的)
from django.contrib import admin from django.urls import path, re_path, include from app01 import views urlpatterns = [ path('admin/', admin.site.urls), path('timer/', views.timer), #控制行为找到这个视图函数,一旦匹配成功之后,就会传一个request的信息,浏览器中发生的请求信息都在这里边;views.timer(request) path('login',views.login), #f分发 每个url单独写到自己的app里边去,在全局做分发就可以了,实现了解耦; # re_path(r"app01/", include("app01.urls")),#如浏览器中输入,前面就必须加app01了http://127.0.0.1:8000/app01/articles/2003/04 re_path(r"^", include("app01.urls")), #浏览器中就可以不写app01了
re_path(r"app02/",include("app02.urls")), ]
app01 views.py
from django.shortcuts import render,HttpResponse # Create your views here. def timer(request): #这个是逻辑行为,逻辑行为直接找到这个文件 import time ctime = time.time() return render(request, "timer.html", {"date":ctime}) #render方法,由它去找这个文件;不需要写路径,它会自己找 #render找到这个html,打开取出这里边的数据,同时把这个变量嵌套在那个位置 def special_case_2003(request): return HttpResponse("special_case_2003") def year_archive(request, year): return HttpResponse(year) def month_archive(request,y, m): #把它位置捣乱,就乱了;可以给每个组起个名字固定住;一定要按关键字来,是那个名字 return HttpResponse(y + "-" + m ) def login(request): return render(request, "login.html")
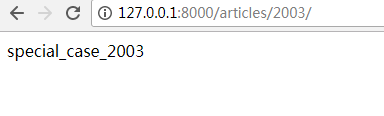
3.4路由控制之登录验证
views.py
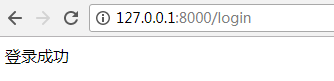
def login(request): print(request.method) if request.method == "GET": return render(request, "login.html") else: print(request.GET) print(request.POST) user = request.POST.get("user") pwd = request.POST.get("pwd") if user == "kris" and pwd == "123": return HttpResponse("登录成功") else: return HttpResponse("用户名或密码错误")
login.html
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> </head> <body> <form action="http://127.0.0.1:8000/login" method="post"> ##如果不加,就默认是当前页面的网址,/login要加,login要跟url路由里边对应好了 用户名 <input type="text" name="user"> 密码 <input type="password" name="pwd"> <input type="submit"> </form> </body> </html>

[12/Aug/2018 16:15:18] "GET /login.html/ HTTP/1.1" 200 316 GET POST <QueryDict: {}> <QueryDict: {'user': ['kris'], 'pwd': ['abc']}> [12/Aug/2018 16:15:45] "POST /login.html/ HTTP/1.1" 200 24
3.5反向解析
path('login.html/',views.login, name="log"),如果我们在起名字的时候写成了login.html,那么用户在访问的时候就要访问http://127.0.0.1:8000/login.html/,那么
--------------->>>>
<form action="http://127.0.0.1:8000/login" method="post"> {# 你这里边写的是login,那么提交post请求的时候就会报错了#} 用户名 <input type="text" name="user"> 密码 <input type="password" name="pwd"> <input type="submit"> </form>
模板语法只有2个:一个是{{}},另外一个就是{% %}
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> </head> <body> <form action="{% url 'log' %}" method="post">{#刚刚我们把它写死了;模板语法之一,render在渲染这个html页面的过程中,它会去解析这个html页面,解析到{% url 'log' %}
的时候它就反向解析;它要去全局里边找一个叫log的name,找到之后取出来渲染之后替换{% url 'log' %}这部分内容,然后再发给客户端的浏览器#} 用户名 <input type="text" name="user"> 密码 <input type="password" name="pwd"> <input type="submit"> </form> </body> </html>
from django.contrib import admin from django.urls import path, re_path, include from app01 import views urlpatterns = [ path('admin/', admin.site.urls), path('timer/', views.timer), #控制行为找到这个视图函数,一旦匹配成功之后,就会传一个request的信息,浏览器中发生的请求信息都在这里边;views.timer(request) path('login.html/',views.login, name="log"), #给它起的别名,login可能会变,但这个log别名不变 #f分发 # re_path(r"app01/", include("app01.urls")), re_path(r"^", include("app01.urls")),#浏览器中可以不写app01了 ]
流程
如果urlpatterns里边的路径path改为login.html/,其他地方都不需要改动。用户在浏览器中输入http://127.0.0.1:8000/login.html/时,得到的页面,它访问的在视图里边,视图里边再渲染login.html(return render(request,"login.html")),渲染它的过程中在 <form action="{% url 'log' %}" method="post">中取log,拿到 name="log",
path('login.html/',views.login, name="log"),改完之后把login.html拿到action中。

不在模板里边,在视图里边进行反向解析,在python里边
#Author:Kris #app01/urls.py from django.contrib import admin from django.urls import path, re_path from app01 import views urlpatterns = [ #路由配置: 路径 -----> 视图函数 re_path(r'articles/2003/$', views.special_case_2003, name="s_c_2003"), #special_case_2003(request);它是一个完整的,没有正则 re_path(r'^articles/([0-9]{4})/$', views.year_archive, name="y_a"), #year_archive(request,1999) 传几个参数就要接收几个参数;跟视图函数是多对一;须严格限定住以它开头以它结尾,不要等它匹配完就不走下一步了 # re_path(r'^articles/([0-9]{4})/([0-9]{2})/$', views.month_archive), #month_archive(request,1999,12) re_path(r'^articles/(?P<y>[0-9]{4})/(?P<m>[0-9]{2})/$', views.month_archive), #month_archive(request,y=1999,m=12);这样函数的形参就可以颠倒位置了 # re_path(r'^articles/([0-9]{4})/([0-9]{2})/([0-9]+)/$', views.article_detail), ]
from django.shortcuts import render,HttpResponse # Create your views here. def timer(request): #这个是逻辑行为,逻辑行为直接找到这个文件 import time ctime = time.time() url = reverse("s_c_2003") url = reverse("y_a", args=(1234, )) #/articles/([0-9]{4})/ print(url) #先从全局里边找,没有再去局部里边找,有个name="s_c_2003". return render(request, "timer.html", {"date":ctime}) #render方法,由它去找这个文件;不需要写路径,它会自己找 #render找到这个html,打开取出这里边的数据,同时把这个变量嵌套在那个位置 from django.urls import reverse def special_case_2003(request): # url = reverse("s_c_2003") 反向解析 # url = reverse("y_a", args=(234, )) #你解析出来的是这个app01/articles/([0-9]{4})/ 需要给它加个参数,任何4位数字都可以以替换符合正则表达式,反向解析出来的不含正则, # print(url) #先从全局里边找,没有再去局部里边找,有个name="s_c_2003";它写到哪个视图函数下面是无所谓的,它利用的是reverse这个函数 return HttpResponse("special_case_2003") def year_archive(request, year): return HttpResponse(year)
/articles/1234/ [26/May/2018 09:33:22] "GET /articles/2003/ HTTP/1.1" 200 17 [26/May/2018 09:33:28] "GET /articles/2009 HTTP/1.1" 301 0 [26/May/2018 09:33:28] "GET /articles/2009/ HTTP/1.1" 200 4 /articles/1234/ # 你得访问timer,才能打印出来它了,即反向解析出来的。用任意4位数字来替换正则表达式子的,它不会给你解析出正则的,只能是4位数字 [26/May/2018 09:44:08] "GET /timer/ HTTP/1.1" 200 164
跟当前访问的路径没有关系,只是给它反向解析了,给我一个别名就可以解析出这个url,它含正则表达式,就可以通过参数来进行匹配替换从而拿到一个固定的url
3.6名称空间
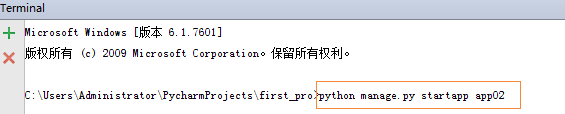
创建app02
命名空间(英语:Namespace)是表示标识符的可见范围。一个标识符可在多个命名空间中定义,它在不同命名空间中的含义是互不相干的。这样,在一个新的命名空间中可定义任何标识符,它们不会与任何已有的标识符发生冲突,因为已有的定义都处于其它命名空间中。
first_pro\urls
from django.contrib import admin from django.urls import path, re_path, include from app01 import views urlpatterns = [ path('admin/', admin.site.urls), path('timer/', views.timer), #控制行为找到这个视图函数,一旦匹配成功之后,就会传一个request的信息,浏览器中发生的请求信息都在这里边;views.timer(request) path('login.html/',views.login, name="log"), #给它起的别名,login可能会变,但这个log别名不变 #f分发 # re_path(r"app01/", include("app01.urls")), re_path(r"^app01", include(("app01.urls", "app01"))),#只写这个r"^"浏览器中可以不写app01了 re_path(r"^app02", include(("app02.urls", "app02"))), #在元组里边给它加上个名称空间app01、app02,起个房间号,名称空间。 ]
app01\views
from django.urls import reverse def index(request): return HttpResponse(reverse('app01:index')) #你要反向解析哪个index,在前面加上'app01'
app02\views
from django.urls import reverse def index(request): return HttpResponse(reverse('app02:index'))#在前面加上'app02'
app01\urls
from django.contrib import admin from django.urls import path, re_path from app01 import views urlpatterns = [ re_path("index/", views.index, name="index") ]
app02\urls
from django.contrib import admin from django.urls import path, re_path from app02 import views urlpatterns = [ re_path("index/", views.index, name="index") ]
3.7控制器之django2.0的path
考虑下这样的两个问题:
第一个问题,函数 year_archive 中year参数是字符串类型的,因此需要先转化为整数类型的变量值,当然year=int(year) 不会有诸如如TypeError或者ValueError的异常。那么有没有一种方法,在url中,使得这一转化步骤可以由Django自动完成?
第二个问题,三个路由中article_id都是同样的正则表达式,但是你需要写三遍,当之后article_id规则改变后,需要同时修改三处代码,那么有没有一种方法,只需修改一处即可?
在Django2.0中,可以使用 path 解决以上的两个问题。
re_path(r'^articles/([0-9]{4})/$', views.year_archive, name="y_a"), #year_archive(request,1999)
#其实我们传的1999是个字符串str而不是int类型#year_archive(request,'1999')
first_pro\urls
from django.contrib import admin from django.urls import path, re_path, include from app01 import views urlpatterns = [ path('admin/', admin.site.urls), path('timer/', views.timer), #控制行为找到这个视图函数,一旦匹配成功之后,就会传一个request的信息,浏览器中发生的请求信息都在这里边;views.timer(request) path('login.html/',views.login, name="log"), #给它起的别名,login可能会变,但这个log别名不变 #f分发 # re_path(r"app01/", include("app01.urls")), re_path(r"^app01", include(("app01.urls", "app01"))),#只写这个r"^"浏览器中可以不写app01了 #re_path(r"^app02", include(("app02.urls", "app02"))), #在元组里边给它加上个名称空间app01、app02 path("articles/<int:year>", views.path_year) #匹配数字,浏览器默认发的是字符串;path_year(request,2001) #path("articles/<path:year>", views.path_year) #只要非空就可以了,?不行,?=1get请求时把它作为了分隔匹配的内容了 ]
app01\views
def year_archive(request, year): return HttpResponse(year) def month_archive(request,m, y): #把它位置捣乱,就乱了;可以给每个组起个名字固定住;一定要按关键字来,是那个名字 print(m) #12 print(type(m)) print(y) print(type(y)) m = int(m) return HttpResponse(y + "-" + m ) def path_year(request, year): print(year) print(type(year)) return HttpResponse("path year")
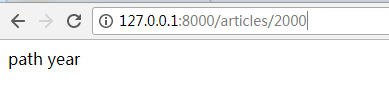
2000 <class 'int'> [26/May/2018 11:18:37] "GET /articles/2000 HTTP/1.1" 200 9
基本规则:
- 使用尖括号(
<>)从url中捕获值。 - 捕获值中可以包含一个转化器类型(converter type),比如使用
<int:name>捕获一个整数变量。若果没有转化器,将匹配任何字符串,当然也包括了/字符。 - 无需添加前导斜杠。
path转化器
文档原文是Path converters,暂且翻译为转化器。
Django默认支持以下5个转化器:
- str,匹配除了路径分隔符(
/)之外的非空字符串,这是默认的形式 - int,匹配正整数,包含0。
- slug,匹配字母、数字以及横杠、下划线组成的字符串。
- uuid,匹配格式化的uuid,如 075194d3-6885-417e-a8a8-6c931e272f00。
- path,匹配任何非空字符串,包含了路径分隔符
自定义转换器
5个内置的转换器太少了,可以自己定义。
对于一些复杂或者复用的需要,可以定义自己的转化器。转化器是一个类或接口,它的要求有三点:
regex类属性,字符串类型
to_python(self, value)方法,value是由类属性regex所匹配到的字符串,返回具体的Python变量值,以供Django传递到对应的视图函数中。to_url(self, value)方法,和to_python相反,value是一个具体的Python变量值,返回其字符串,通常用于url反向引用。
新建一个py文件 urlconvert.py
class MonConvert: regex = "[0-9]{2}" #规则,0-9的2个数字 def to_python(self, value): return int(value) #把这个value作为参数传进去 def to_url(self, value): #用于反向解析的时候 return '%04d'% value
first_pro\urls
from django.contrib import admin from django.urls import path, re_path, include, register_converter from app01.urlconvert import MonConvert register_converter(MonConvert, "mm") #注册自定义的url转换器,起个名字mm(2位的数字),到时候替换 from app01 import views urlpatterns = [ path('admin/', admin.site.urls), path('timer/', views.timer), #控制行为找到这个视图函数,一旦匹配成功之后,就会传一个request的信息,浏览器中发生的请求信息都在这里边;views.timer(request) path('login.html/',views.login, name="log"), #给它起的别名,login可能会变,但这个log别名不变 #path("articles/<path:year>", views.path_year), #只要非空就可以了,?不行,?=1get请求时把它作为了分隔匹配的内容 path("articles/<mm:month>", views.path_month), ]
app01\views
def path_year(request, year): print(year) print(type(year)) return HttpResponse("path year") def path_month(request, month): print(month, type(month)) return HttpResponse("path month。。。")
3 <class 'int'> [26/May/2018 12:04:09] "GET /articles/03 HTTP/1.1" 200 19 34 <class 'int'> [26/May/2018 12:04:27] "GET /articles/34 HTTP/1.1" 200 19
4总结:
django的第一站就是,在url中进行路径匹配,匹配成功了就会执行视图
正则、分组、有名分组、分发做解耦用的、反向解析、名称空间(避免重名)



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人