
第三章| 3.2函数
3函数
定义: 函数是指将一组语句的集合通过一个名字(函数名)封装起来,要想执行这个函数,只需调用其函数名即可
特性:
- 减少重复代码
- 使程序变的可扩展
- 使程序变得易维护
语法定义
def sayhi():#函数名
print("Hello")
print("my name is kris!")
sayhi() #调用函数
调用参数
def sayhi(name):#函数名
print("Hello",name)
print("my name is kris!")
sayhi("alex") #调用函数
def calc(x,y):
res = x**y
return res #返回函数执行结果
c = calc(a,b) #结果赋值给c变量
print(c)
① 函数参数
形参变量、实参、默认参数、位置参数(按照位置)、非固定参数 *args **kwargs


def stu_register(name,age,country,course):
print("----注册学生信息------")
print("姓名:",name)
print("age:",age)
print("国籍:",country)
print("课程:",course)
stu_register("王山炮",22,"CN","python_devops")
stu_register("张叫春",21,"CN","linux")
stu_register("刘老根",25,"CN","linux")
def stu_register(name,age,course,country = 'CN'): #country='CN'就是默认参数
print("registriation info...")
print(name,age,course,country)
stu_register("alex",22,"python")
stu_register("kris",23,"python","CN")
stu_register("shanshan",18,"python","Korean")
关键参数 (必须放在位置参数之后)
正常情况下,给函数传参数要按顺序,不想按顺序就可以用关键参数,只需指定参数名即可(指定了参数名的参数就叫关键参数),但记住一个要求就是:
关键参数必须放在位置参数(以位置顺序确定对应关系的参数)之后
def stu_register(name, age, course='PY' ,country='CN'):
print("----注册学生信息------")
print("姓名:", name)
print("age:", age)
print("国籍:", country)
print("课程:", course)
stu_register("王山炮",course='PY', age=22,country='JP' ) #调用, 关键参数(没按顺序传参)
非固定参数 *args(会把多传入的参数变成一个元组形式) **kwargs(*kwargs 会把多传入的参数变成一个dict形式)
def send_alert(msg,*users): #如果参数出现,*users,传递的参数就可以不再是固定个数,传过来的所有参数打包元组。# *users是非主流的,*args才是主流。
for u in users:
print('报警发送给',u)
send_alert('别他么狠了' , ‘alex’, 'rain' ,'xxx' ) #后边三个打包成元组传递
def send_alert(msg,*users,age):
for u in users:
print('报警发送给',u)
#如果参数中出现*users,传递的参数就可以不再是固定个数,传过来的所有参数打包元组。
#方式一
send_alert('别他么狠了' , ‘alex’, 'rain' ,'xxx' )
#方式二
send_alert('别他么狠了' , *[‘alex’, 'rain' ,'xxx'] ) #([‘alex’, 'rain' ,'xxx'] ) ------>(‘alex’, 'rain' ,'xxx')
send_alert("alex","rain","eric",age=22) # "rain","eric" 它们一块传给了*users
**kwargs 是关键字参数(未定义的),指定的那个参数名。
def func(name,*args,**kwargs):
print(name,args,kwargs) #输出 alex (22 , 'tesla' , '500w') {'num':123444332 , 'addr':'山东'}
func('alex' ,22 ,'tesla' , '500w' , addr = '山东' , num = 123444332)
def func(name,*args,**kwargs):
print(name,args,kwargs) #输出 alex (22 , 'tesla' , '500w') {'num':123444332 , 'addr':'山东'}
# jack () {'degree': 'primary school'}
func('alex' ,22 ,'tesla' , '500w' , addr = '山东' , num = 123444332)
d = { 'degree':'primary school' }
func('jack' ,**d)
② 返回值 (return代表函数的终值)
- 外部的代码要想获取函数的执行结果,就可以在函数里用return语句把结果返回;
- return语句退出函数,并返回一个表达式;
- 不带参数值的return语句返回None。
def stu_register(name,age,course):
print(name,age,course)
# if age > 22:
# return 'sdfsdf'
# else:
# return True
return None
print('哈哈') #不再执行了,上边有return 表示函数终止了
return 1
status = stu_register('kris', 28, 'bigdata')
print(status) #kris 28 bigdata \n None
③ 局部变量
定义在函数外部一级代码的变量,叫全局变量,全局能用;
局部变量就是指定义在函数里的变量,只能在局部生效;
在函数内部,可以引用全局变量;
如果全局和局部都有一个变量叫name,函数查找变量的顺序是由内而外的。
name = "Black girl" def change_name(): name = "黑色姑娘" print("在" ,name ,"里面...") #打印: 在 黑色姑娘 里面.... change_name() print(name) #打印: Black girl
- 里边可以调用外边,但是不能修改。
- 外边不能调用里边的变量。
- 局部只能引用全局,是修改不了的 .
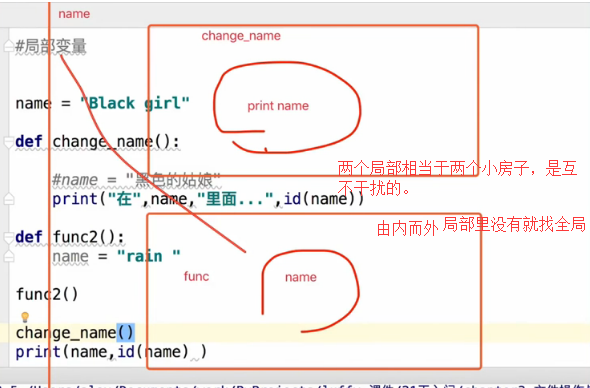
name = "Black girl"
def change_name():
#name = "黑色姑娘"
print("在" ,name ,"里面..." ,id(name) ) #打印:
def func2():
name = "rain"
func2()
change_name()
print(name,id(name)) #打印: Black girl
在函数里修改全局变量(整体改,要加global)
name = "Black girl"
def change_name():
global name #改为全局
name = "黑色的姑娘"
age = 25
print("在" ,name ,"里面...", id(name)) #在黑色姑娘里面 139763905997504
change_name()
print(name, id(name) ) #在黑色姑娘里面 139763905997504
在函数里 修改列表数据:字典、列表、集合、类,不可以修改的有字符串
names = ['alex' , 'black girl' , 'peiqi' ]
def change_name():
del names[2]
names[1] = "黑姑娘" #整体不可以修改,但里边内部可以改
print(names)
change_name()
print(names) #['alex', '黑姑娘']
④ 嵌套函数
#嵌套函数
#1
def func1():
print('alex')
def func2():
print('eric') #它没有被调用所以就不会输出eric
func1() #输出alex
#2
def func1():
print('alex')
def func2():
print('eric')
func2()
func1() #输出alex eric
# ====>1.函数内部可以再次定义函数。
2.执行需要被调用
#3
def func1():
age = 73
print(age)
def func2():
print(age) #它会去父级找
func2()
func1() #输出 73 73
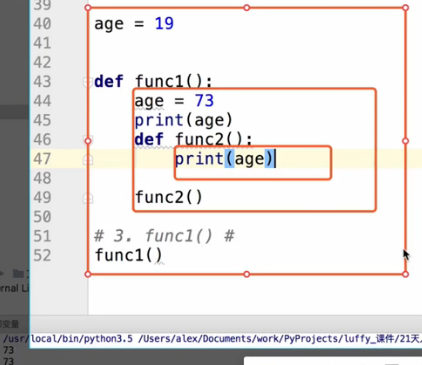
自己没有,就去父级找,没有再去爷爷级。由内向往,一层层的找。局部变量之间也是有等级关系的。
age = 19
def func1():
age = 73
def func2():
print(age) #输出 73
func2()
func1()
age = 19
def func1():
def func2():
print(age) #输出73
age = 73 #程序是从上往下读的,先读age,再去调用func2()
func2()
func1()
age = 19
def func1():
global age #把age=19拿回了
def func2():
print(age) #19
func2() #当程序走到这的时候,调用func2()然后往上走,输入age=19,再往下走age=73
age = 73 #73 它已经是全局了
func1()
print(age) #73
age = 19
def func1():
global age #把全局拿过来了
def func2():
print(age) #73
age = 73 #把全局的给改了,然后再往下走去执行func2()
func2()
func1()
print(age) #73
从上往下找,代码谁先执行,掌握global
⑤ 作用域
在python中一个函数就是一个作用域。 无论在任何地方调用这个函数,永远回到它最开始的地方从上执行,往上找。
python中函数就是一个作用域(javascript),局部变量放置在其作用域中;
c# Java中作用域{ };
代码完成后,作用域已经生成,作用域链向上查找。
age = 18
def func1():
age = 73
def func2():
print(age)
return 666 #返回值为666
val = func1()
print(val) #打印出 666
age = 18
def func1():
age = 73
def func2():
print(age) #打印
return func2 #返回的是一个函数,函数名作为一返回值
val = func1()
print(val) #<function func1.<locals>.func2 at 0x00000000027F1730>
age = 18
def func1():
age = 73
def func2():
print(age) #打印出 73
return func2 #返回的是一个函数
val = func1()
val()#返回值func2再调用它
函数名可以当做返回值。
⑥ 匿名函数
匿名函数就是不需要显式的指定函数名。 没有名字,不能调用,只是一个函数。节省代码量;看着高级。
匿名函数主要是和其它函数搭配使用的呢。lambda、 lambda返回的值 结合map,filter,reduce使用
#这段代码
def calc(x,y):
return x**y
print(calc(2,5)) #32
#换成匿名函数
calc = lambda x,y:x**y
print(calc(2,5))
def calc(x,y):
return x*y
func = lambda x,y:x**y #声明一个匿名函数
print(calc(3,8)) #24
print(func(3,8)) #6561
def calc(x,y): if x < y : return x*y else: return x/y func = lambda x,y:x*y if x < y else x/y #声明一个匿名函数 ###只能用三元运算了。 print(calc(16,8)) #2 print(func(16,8)) #2
print(func(16,32)) #512
data = list(range(10))
print(data) #[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
#for index,i in enumerate(data):
#for index,i in enumerate(data): #enumerate接收第二个参数可用于指定索引起始值
# data[index] = i * i
#print(data) #[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
def f2(n):
return n *n
print(list(map(f2, data))) #map函数 #[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
print(list(map(lambda x:x*x, data))) #[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
补充:enumerate的用法
- enumerate将 一个可迭代的(iterable)/可遍历的对象(如列表、字符串) 组成一个索引序列,可以同时获得索引和值;
如统计文件的行数: count = len(open(filepath, 'r').readlines()) #比较慢
可利用enumerate():
count = 0
for index, line in enumerate(open(filepath, 'r')):
count += 1
##匿名函数不需要return来返回值,表达式本身结果就是返回值.
lambda x,y:x+y
lambda x,y,z : x+y+z
lambda x,y: x if x> y else y
lambda x,y=2:x+y #含默认值
a = lambda x,y=2:x+y ##调用
a(2) ##不输就使用默认值 输出4
a(2,3) #输出为 5
>>>a = lambda *z:z ##*z返回的是一个元祖
>>> a('Testing1','Testing2')
('Testing1', 'Testing2')
>>>c = lambda **Arg: Arg #arg返回的是一个字典
>>> c()
{}
#lambda返回的值,结合map,filter,reduce使用
map(函数,序列) map将传入的函数依次作用到序列中的每一个元素;
reduce(f, [x1, x2, x3, x4]) = f(f(f(x1, x2), x3), x4)
>>> filter(lambda x:x%3==0,[1,2,3,4,5,6])
[3, 6]
##等价于下面的列表推导式
>>> l = [x for x in [1,2,3,4,5,6] if x%3==0]
>>> l
[3, 6]
>>> squares = map(lambda x:x**2,range(10)) #[0,1,4,9,16,25,36,49,64,81]
>>> filters = filter(lambda x:x>5 and x<50,squares)
>>> filters
[9, 16, 25, 36, 49]
##lambda和reduce联合使用
>>> L = [1,2,3,4]
>>> sum = reduce(lambda x,y:x+y,L)
>>> sum
10
##求2-50之间的素数
#素数:只能被1或被自己整除的数
>>> nums = range(2,50)
>>> for i in nums:
nums = filter(lambda x:x==i or x % i,nums)
>>> nums
[2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47]
###求两个列表元素的和
>>> a = [1,2,3,4]
>>> b = [5,6,7,8]
>>> map(lambda x,y:x+y, a,b)
[6, 8, 10, 12]
lambda和sorted联合使用
#按death名单里面,按年龄来排序
#匿名函数的值返回给key,进来排序
>>> death = [ ('James',32),
('Alies',20),
('Wendy',25)]
>>> sorted(death,key=lambda age:age[1]) #按照第二个元素,索引为1排序
[('Alies', 20), ('Wendy', 25), ('James', 32)]
⑦ 高阶函数
变量可以指向函数,函数的参数能接收变量,那么一个函数就可以接收另一个函数作为参数,这种函数就称之为高阶函数。
def calc(x):
return x*x
#f = lambda x:x*x #变量指向匿名函数
f = calc #变量不光可以赋值,可以指向函数,什么都可以赋值;
f()
def calc(x):
return x*x
n = 10
calc(n) #函数的参数能接收变量
print(calc(n)) #100
def func(x,y):
return x+y
def calc(x):
return x #x()可以执行这个函数; x=func
n = func
calc(n) #一个函数可以接收另一个函数作为参数
def func(x,y):
return x+y
def calc(x): #把func当做参数传给了x,又返回了;不返回pass也是高阶函数
return x
f = calc(func)
print(f(5,9)) # 14 上一步执行calc这个函数的时候把x返回了,也就是把func这个函数给返回了,返回给外部使用;相当于执行的是func(5,9)
def func2(x,y):
return abs,x,y #返回另外一个函数
res = func2(3,-10)
print(res)
只需满足以下任意一个条件,即是高阶函数:
- 接受一个或多个函数作为输入
- return 返回另外一个函数
def func(x,y):
return x+y
def calc(x):
return x
f = calc(func)
print(f(5,9)) //14
def func2(x,y):
return abs,x,y
res = func2(3,-10)
print(res)
⑧ 递归
递归就是在函数的执行过程中调用自己。
python有一个最大递归层。
最大递归深度限制,为什么要限制呢?
通俗来讲,是因为每个函数在调用自己的时候 还没有退出,占内存,多了肯定会导致内存崩溃。
本质上讲呢,在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数
过多,会导致栈溢出。
import sys
print(sys.getrecursionlimit()) #python默认的最大递归层
sys.setrecursionlimit(1500) #可以给它设置递归层,让它无限递归下去会把系统给弄爆
def recursion(n):
print(n)
recursion(n+1)
recursion(1)
def calc(n):
print(n) #10 5 2 1
if int(n/2) ==0: 加一个判断条件就不用再往下递归了
return n
return calc(int(n/2))
calc(10)
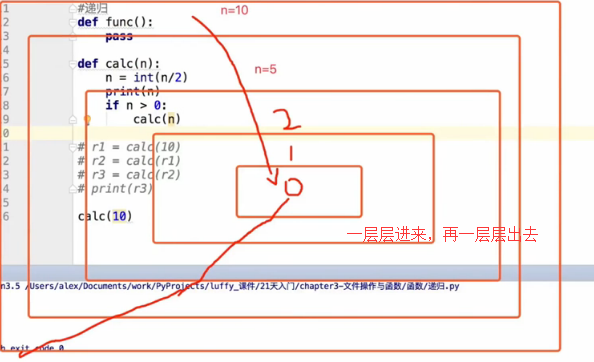
def calc(n):
v = int(n/2)
print(v) #5 2 1
if v > 0:
calc(v)
print(n)#0 1 2 5 10 它会一层层再出来,从内到外
calc(10)
递归执行过程
递归的返回值
def calc(n,count)
print(n,count) #188 1 , 94.0 2 , 47.0 3, 23.5 4 , 11.75 5
if count < 5:
calc(n/2,count+1)
calc(188,1)
两个return的作用,最里层那个往外返回那个结果; 每一层接收它下一层的,就是里边一层返回给它上边一层的那个值
def calc(n,count)
print(n,count) #打印:188 1 , 94.0 2 , 47.0 3, 23.5 4 , 11.75 5 ,res 11.75 #这样就拿到了最里层的那个结果11.75
if count < 5:
return calc(n/2,count+1)
else:
return n
res = calc(188,1)
print('res' , res)
递归特性:
- 必须有一个明确的结束条件
- 每次进入更深一层递归时,问题规模相比上次递归都应有所减少
- 递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出)
堆栈扫盲 http://www.cnblogs.com/lln7777/archive/2012/03/14/2396164.html
递归的用途
如阶乘、二分查找
def factorial(n):
if n == 1: #结束条件,最里层;倒数第二层跟这个1相乘
return 1
return n * factorial(n-1) #factorial(n-1)层层进去得到最里层结果,返回值直接用return;调用下一层时自己退出了,但它还要等着下一层的结果,所以不叫尾递归
print(factorial(5)) #120
二分查找


data = [1, 3, 6, 7, 9, 12, 14, 16, 17, 18, 20, 21, 22, 23, 30, 32, 33, 35] def binary_search(dataset,find_num): print(dataset) if len(dataset) >1: mid = int(len(dataset)/2) if dataset[mid] == find_num: #find it print("找到数字",dataset[mid]) elif dataset[mid] > find_num :# 找的数在mid左面 print("\033[31;1m找的数在mid[%s]左面\033[0m" % dataset[mid]) return binary_search(dataset[0:mid], find_num) else:# 找的数在mid右面 print("\033[32;1m找的数在mid[%s]右面\033[0m" % dataset[mid]) return binary_search(dataset[mid+1:],find_num) else: if dataset[0] == find_num: #find it print("找到数字啦",dataset[0]) else: print("没的分了,要找的数字[%s]不在列表里" % find_num) binary_search(data,66)
递归的优化(尾递归)
在c语言中有效;在python中无效,没有递归的优化,虽然你写了尾递归的结构但也是没用的。
def cal(n):
print(n)
return cal(n+1) #调用下一层的时候给它返回,这就是尾递归 我在调用下一层的同时自己退出了,下一层的结果跟我没有关系了
cal(1)
⑨ 函数内置方法
min() ;max() 最小、最大值。
all() 两种情况。如果列表里的每个值通过bool判断都是True就返回True;如果iterable是空,返回True。
bool()判断是否是True
>>> help(all)
all(iterable, /) Return True if bool(x) is True for all values x in the iterable. If the iterable is empty, return True. >>> bool(1) True >>> bool(-1) True >>> bool(False) False >>> a = [1,4,5,-1,3] >>> all(a) True >>> a.append(0) >>> a [1, 4, 5, -1, 3, 0] >>> all(a) False >>> bool([]) ##空列表,可循环的,就返还True False >>> bool([1]) True
any()
>>> help(any) any(iterable, /) Return True if bool(x) is True for any x in the iterable. If the iterable is empty, return False. >>> a [1, 4, 5, -1, 3, 0] >>> any(a) True >>> any([False,0]) False >>> any([False,0,1]) True
dir()打印程序里边存在的所有变量。
>>> dir() ['__annotations__', '__builtins__', '__doc__', '__loader__', '__name__', '__package__', '__spec__', 'a']
hex()转成16进制; oct()变成8进制;bin()转成2进制。
slice()
>>> s=slice(1,7,2)
>>> s
slice(1, 7, 2)
>>> l = range(10)
>>> l = list(range(10))
>>> l
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> s
slice(1, 7, 2)
>>> l[1:3]
[1, 2]
>>> l[s] #相当于是先把切片的规则定义好
[1, 3, 5]
divmod()先返回它的商再返回它的余数。
>>> divmod(10,3) (3, 1)
sorted()
d={}
for i in range(20):
d[i]=i-50
print(d)
#{0: -50, 1: -49, 2: -48, 3: -47, 4: -46, 5: -45, 6: -44, 7: -43, 8: -42, 9: -41, 10: -40, 11: -39, 12: -38, 13: -37, 14: -36, 15: -35, 16: -34, 17: -33, 18: -32, 19: -31}
print(d.items())
#dict_items([(0, -50), (1, -49), (2, -48), (3, -47), (4, -46), (5, -45), (6, -44), (7, -43), (8, -42), (9, -41), (10, -40), (11, -39), (12, -38), (13, -37), (14, -36), (15, -35), (16, -34), (17, -33), (18, -32), (19, -31)])
#变成列表之后,自定义一些排序的规则
print(sorted(d.items(), key=lambda x:x[1]))
#[(0, -50), (1, -49), (2, -48), (3, -47), (4, -46), (5, -45), (6, -44), (7, -43), (8, -42), (9, -41), (10, -40), (11, -39), (12, -38), (13, -37), (14, -36), (15, -35), (16, -34), (17, -33), (18, -32), (19, -31)]
print(sorted(d.items(), key=lambda x:x[1], reverse=True))
#[(19, -31), (18, -32), (17, -33), (16, -34), (15, -35), (14, -36), (13, -37), (12, -38), (11, -39), (10, -40), (9, -41), (8, -42), (7, -43), (6, -44), (5, -45), (4, -46), (3, -47), (2, -48), (1, -49), (0, -50)]
ascii()
s = 'abc路飞'
print(s)
#变成unicode的编码格式
print(ascii(s)) #'abc\u8def\u98de'
eval()把字符串转换成代码;只能处理单行代码。
f = "1+3/2"
print(f) #1+3/2
print(eval(f)) #2.5
print(eval('print("Hello world")')) #Hello world
exec()与eval()的区别就是可以执行多行;一个有返回值一个没有返回值。
code = '''
if 3 > 5:
print('3 bigger than 5')
else:
print('ddd')
'''
print(code) #打印如上字符
print(exec(code)) #ddd
res = eval("1+3+3")
res2 = exec("1+3+3")
print('res',res, res2) #res 7 None
ord()
print(ord('a')) #97 print(chr(97)) #a print(chr(98)) #b print(chr(95)) #- print(chr(65)) #A
sum()求和
a = [1,2,3,5] print(sum(a)) #11
bytearray()
bytes和字符串都不能直接修改。原内存地址修改。大字节涉及修改的时候,把它先变成bytes。大字符串变列表,就是字符串和列表的关系就相当于字节和bytes的关系。
s = 'abc路飞'
print(s.encode('utf-8')) #b'abc\xe8\xb7\xaf\xe9\xa3\x9e'
s = s.encode('utf-8')
s = bytearray(s)
print(s) #bytearray(b'abc\xe8\xb7\xaf\xe9\xa3\x9e')
print(s[0]) #97
print(s) #bytearray(b'abc\xe8\xb7\xaf\xe9\xa3\x9e')
print(id(s[0])) #10917568
s[0] = 66
print(id(s[0])) #10916576
print(s) #bytearray(b'Bbc\xe8\xb7\xaf\xe9\xa3\x9e')
########整个内存地址没有变,只是把里边的内存地址给改了。
print(id(s)) #139924650416760
s[0] = 67
print(id(s)) #139924650416760
map()
map()是 Python 内置的高阶函数,它接收一个函数 f 和一个 list,并通过把函数 f 依次作用在 list 的每个元素上映射得到一个新的 list 并返回。

def f(x):
return x*x
print (map(f, [1, 2, 3, 4, 5])) #<map object at 0x0000000001EBF048>
def format_name(s):
s1=s[0:1].upper()+s[1:].lower(); #它是将字符串‘adam’传进去的
return s1;
print (list(map(format_name, ['adam', 'LISA', 'barT']))) #['Adam', 'Lisa', 'Bart']
#使用lambda
>>> print (list(map(lambda x: x % 2, range(7))))
[0, 1, 0, 1, 0, 1, 0]
#使用列表解析
>>> print([x % 2 for x in range(7)])
[0, 1, 0, 1, 0, 1, 0]
***将元组转换成list***
>>> list(map(int, (1,2,3)))
[1, 2, 3]
***将字符串转换成list***
>>> list(map(int, '1234'))
[1, 2, 3, 4]
***提取字典的key,并将结果存放在一个list中***
>>> list(map(int, {1:2,2:3,3:4}))
[1, 2, 3]
***字符串转换成元组,并将结果以列表的形式返回***
>>> list(map(tuple, 'agdf'))
[('a',), ('g',), ('d',), ('f',)]
#将小写转成大写
def u_to_l (s):
return s.upper()
print(list(map(u_to_l,'asdfd'))) #['A', 'S', 'D', 'F', 'D']
filter()
filter()也接收一个函数和一个序列。filter()把传入的函数依次作用于每个元素,然后根据返回值是True还是False决定保留还是丢弃该元素。

def is_odd(x):
return x % 2 == 1
print(list(filter(is_odd, [1, 4, 6, 7, 9, 12, 17]))) ##[1, 7, 9, 17]
##删除 None 或者空字符串:
def is_not_empty(s):
return s and len(s.strip()) > 0
print(list(filter(is_not_empty, ['test', None, '', 'str', ' ', 'END']))) ##['test', 'str', 'END']
##过滤出1~100中平方根是整数的数
import math
def is_sqr(x):
return math.sqrt(x) % 1 == 0
print(list(filter(is_sqr, range(1, 101)))) #[1, 4, 9, 16, 25, 36, 49, 64, 81, 100
reduce()
reduce()函数接收的参数和 map()类似,一个函数 f,一个list,但行为和 map()不同,
reduce()传入的函数 f 必须接收两个参数,reduce()对list的每个元素反复调用函数f,并返回最终结果值。

def add(x, y):
return x+y
from functools import reduce ##reduce()为高阶函数需导入包
print(reduce(add, [1,2,3,4])) #10
from functools import reduce
print(reduce(lambda re,x:re+x,[2,4,6],10))
#这个例子传入了初始化参数10 ,这样re的初始化值为10.有三个元素,需要操作三轮,结果就是22了.
#####计算阶乘
print(reduce(lambda re,x:re*x,range(1,6)))
#结果为120. range(1,6)的结果是列表[1,2,3,4,5] , 上面的运算就是计算这些元素的乘积。

print()
>>> s = 'hey, my name is kris\n, from beijing'
>>> print(s, end=',')
hey, my name is kris
, from beijing,
>>> print(s, sep='')
hey, my name is kris
, from beijing
>>> print('BeiJing','TianJin',sep='->')
BeiJing->TianJin
>>> msg="又回到最初的起点"
>>> print(msg,"记忆中你青涩的脸", sep="|", end="")
又回到最初的起点|记忆中你青涩的脸
>>>
>>> print(msg,"记忆中你青涩的脸", sep="|", end="||")
又回到最初的起点|记忆中你青涩的脸||
callable() 判断一个东西是否可以调用。
>>> a=[1,4,5,-1,3,0]
>>> callable(a)
False
>>> s={12,3,4,4}
>>> s.discard()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: discard() takes exactly one argument (0 given)
>>> s.discard(3)
>>> s
{12, 4}
>>> s=frozenset(s)
>>> s.difference()
frozenset({12, 4})
>>> vars()
{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <class '_frozen_importlib.BuiltinImporter'>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, 'a': [1, 4, 5, -1, 3, 0], 's': frozenset({12, 4}), 'l': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9], 'd': {}, 'msg': '又回到最初的起点'}
>>> dir() # dir是只打印变量名;vars是打印变量名和对应的值
['__annotations__', '__builtins__', '__doc__', '__loader__', '__name__', '__package__', '__spec__', 'a', 'd', 'l', 'msg', 's']
>>> print(locals()) #打印函数的局部变量
{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <class '_frozen_importlib.BuiltinImporter'>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, 'a': [1, 4, 5, -1, 3, 0], 's': frozenset({12, 4}), 'l': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9], 'd': {}, 'msg': '又回到最初的起点'}
>>> globals() #全局变量
{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <class '_frozen_importlib.BuiltinImporter'>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, 'a': [1, 4, 5, -1, 3, 0], 's': frozenset({12, 4}), 'l': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9], 'd': {}, 'msg': '又回到最初的起点'}
>>>
zip()有的就一一对应,没有的就丢弃了。
>>> a=[1, 4, 5, -1, 3, 0]
>>> b=['a','b','c','d','e','f']
>>> list(zip(a,b))
[(1, 'a'), (4, 'b'), (5, 'c'), (-1, 'd'), (3, 'e'), (0, 'f')]
complex()变成复数;round()变成小数
>>> complex(3,5)
(3+5j)
>>> round(1.2344423)
1
>>> round(1.2344423,2)
1.23
hash()
把字符串变成数字。
>>> hash('abc')
3929214765177675487



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律