
第一章| python变量| 运算符| 二进制| 字符编码| 流程控制
程序设计基础
编程可以解决什么问题:
- 重复性劳动 -- “脏活”、“累活”;
- 复杂的简单问题 -- “围棋与斗地主”
- 将生活中的“事儿”归纳总结为某些规则,并通过计算机交互;
- 自动化--提升工作效率;
- 定制化--解决特定问题;
- 数字化--自动分类;
程序(program):流程、议程、行程;为了完成某项任务,解决某个问题所需要执行的一些列步骤;
计算机程序:为了完成某项任务,解决某个问题由计算机执行的一些列指令(步骤);
计算机:按程序自动运行的机器;
组成:硬件和软件
每18个月芯片能力增长一倍;
计算机应该按照程序顺序执行;
采用二进制作为计算机的数制基础;
人与机器的沟通
不同母语人之间的沟通
- 一人学习另一人的语言;
- 共同学习第三种语言;
人与机器的沟通
- 机器学习人类的语言(自然语言处理);
- 人学习机器的语言;
- 共同学习第三种语言(程序设计语言)
1. 编程语言介绍
编程就是写代码,让计算机帮你做事情。计算机底层是电路,只认识二进制0和1.
二进制更容易被硬件存储和计算;
机器语言&汇编语言
语言进化历史:机器、汇编、高级(比低级语言更贴近人类的思维)。
- 机器语言只接受二进制代码;
- 汇编语言是采用英文缩写的标识符,更容易识别和记忆,只是对0和1进行代替;如 MOV AX, 1 (10111000、00000001、00000000)
- 高级语言,把好多机器指令变成一句话了,如C\C++、java、PHP、python、GO等。由高级语言编写的程序文件转换为可执行文件(二进制的)有两种方式,编译和解释
它们的区别:在于转换二进制的方式不同。C\C++运行速度快,python、Java、php运行速度比较慢。
编译类:先翻译成二进制,产生两个文件,运行的时候是二进制文件。程序执行效率高,编译后程序运行时不需要重新翻译,直接使用编译的结果就可以了,但是跨平台性能差。如C\C++、Delphi等。
通过操作系统把它运行起来,操作系统下面才是CPU、运行内存等
解释型:“同声翻译”,一边翻译成目标代码即机器语言一边执行,运行效率比较低且不能生成可独立执行的可执行文件,应用程序不能脱离解释器(通过解释器对程序逐行作出解释,然后直接运行),
这种方式比较灵活,可以动态调整、修改应用程序。可以跨平台,开发效率高。如java、python ;
如:java(虽然java也需要编译, 编译成.class文件,但是并不是机器可以识别的语言, 而是字节码, 最终还是需要 jvm的解释, 才能在各个平台执行, 这同时也是java跨平台的原因。
Java首先是通过编译器编译成字节码文件(不是二进制码),然后在运行时通过解释器给解释成机器文件。所以我们说Java是一种先编译后解释的语言。
javac hello.java(编译);java hello(解释)。
python:python hello.py时,其实是激活了Python的“解释器”,告诉“解释器”:你要开始工作了。可是在“解释”之前,其实执行的第一项工作和Java一样,是编译。
Python也是一门先编译后解释的语言。
当python程序运行时,编译的结果是保存在内存中的 PyCodeObject中,当Python程序运行结束时,Python解释器则将PyCodeObject写回到pyc文件中。
2. python简介和安装
python语言的特点:
- 解释型语言;
- 设计哲学是“优雅”、“明确”、“简单”;(易学易用)
- 开发哲学是“用一种方法,最好是只用一种方法来做一件事”;
- 现代编程语言(面向对象、支持泛型设计、支持函数式编程);
- 解释性语言(翻译性)
- python不适用于 抢购、电商类计算密集型场景; 不适用于 涉及内存等底层硬件操作; 不适用网页/小程序等前端开发; 不适用于app开发;
Python解释器:
CPython官方版本;IPython在交互方式上有所增强;PyPy执行速度快,使用JIT技术,进行动态编译;Jython;IronPython。
安装:
在python官网上面https://www.python.org/downloads/windows/
测试安装是否成功
windows --> 运行 --> 输入cmd ,然后回车,弹出cmd程序,输入python,如果能进入交互环境 ,代表安装成功。
如果不成功,应该设置环境变量:右击我的电脑—属性,选择高级系统设置—环境变量—找到path
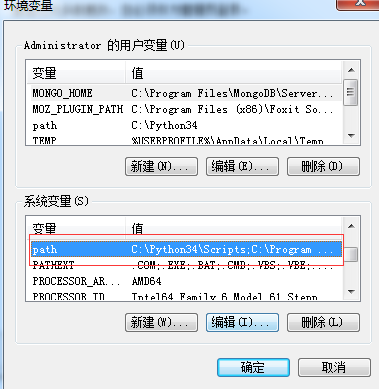
找到python安装文件,前边要加分号,复制粘贴其路径,然后,再复制Scripts的路径加在后边,最后加分号即可,确实,设置成功。
IDE环境安装
- pycharm安装 pycharm官⽹ https://www.jetbrains.com/pycharm/
- sublime安装 sublime官⽹ http://www.sublimetext.com/3
- markdown⼯具Typora安装 Typora官⽹ https://www.typora.io
命令行/IDE或脚本

命令行方式: >>> print ('Hello World') Hello World IDE或脚本方式运行 >>> python Hello.py #运行文件
区别:
命令行:无需创建文件,立即看到运行结果; 适用于语句功能测试;
脚本:反复运行,易于编辑; 适用于大型程序;
3. 变量
作用:存数据,占内存,存储程序运行的中间结果,然后以备后边的代码调用。
变量的表示方法:
- 变量名可以使用字母、数字和下划线_ 的组合;
- 不能以数字开头;
- 严格区分大小写;
- 不要使用中文;
- 常量,全部大写。
- 以下关键字不能声明为变量名
['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']。
变量的命名规范适用于脚本名称和后期的函数名及其它命令规范
变量的定义方式
定义变量时 要注意遵守变量命名规范
① 变量定义方式
- a = 10
- b = 20
② 定义方式
- a,b = 30,40
交换变量的数据
- a = 10
- b = 20
方法①
- c = a
- a = b
- b = c
方法②
- a,b = b,a
4. 格式化输出
input()里边默认是字符串
#格式化输出
name = input("Name:")
age = input("Age:")
job = input("Job:")
info = '''
---------------info of %s-----------
Name:%s
Age:%s
Job:%s
-----------------end----------------
''' %(name, name, age, job)
print(info)
## 格式化字符:数字格式化的那些坑
>>> m = 3.1416926
>>> print("pi is %f" %m)
pi is 3.141693
>>> print("pi is %.2f" %m)
pi is 3.14
# 我只想输出2位小数:%.2f,此处是四舍五入
>>>
>>> m = 10.6
>>> print("pi is %i" %m)
pi is 10
>>> print("pi is %.0f" %m)
pi is 11
# 区别:%i 不四舍五入,直接切掉小数部分
>>>
>>> m = 100
>>> print("have fun %+i" %m)
have fun +100
>>> print("have fun %.2f" % -0.01)
have fun -0.01
# 显示正号,负号根据数字直接显示
>>>
>>>
>>> m = 100
>>> print("have fun % i" %m)
have fun 100
>>> print("have fun % +i" %m)
have fun +100
>>> print("have fun % .2f" %-0.01)
have fun -0.01
# 加空格,空格和正好只能显示一个
>>>
>>> m = 123.123123123
>>> print("have fun %.2e" %m)
have fun 1.23e+02
>>> print("have fun %.4E" %m)
have fun 1.2312E+02
# 科学计数法 %e %E
>>>
>>> m1 = 123.123123123
>>> m2 = 1.2
>>> print("have fun %g" %m1)
have fun 123.123
>>> print("have fun %g" %m2)
have fun 1.2
# 小数位数少的时候自动识别用浮点数,数据复杂的时候自动识别用科学计数法
浮点数:有限小数或无限循环。
prec表示精度。
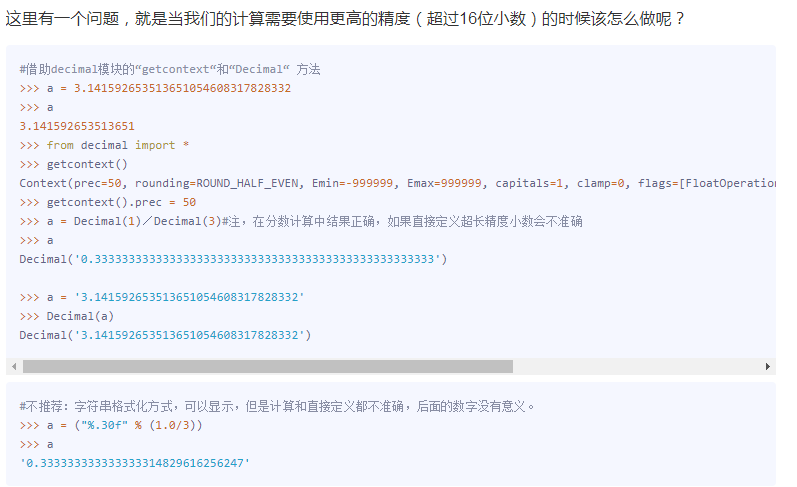
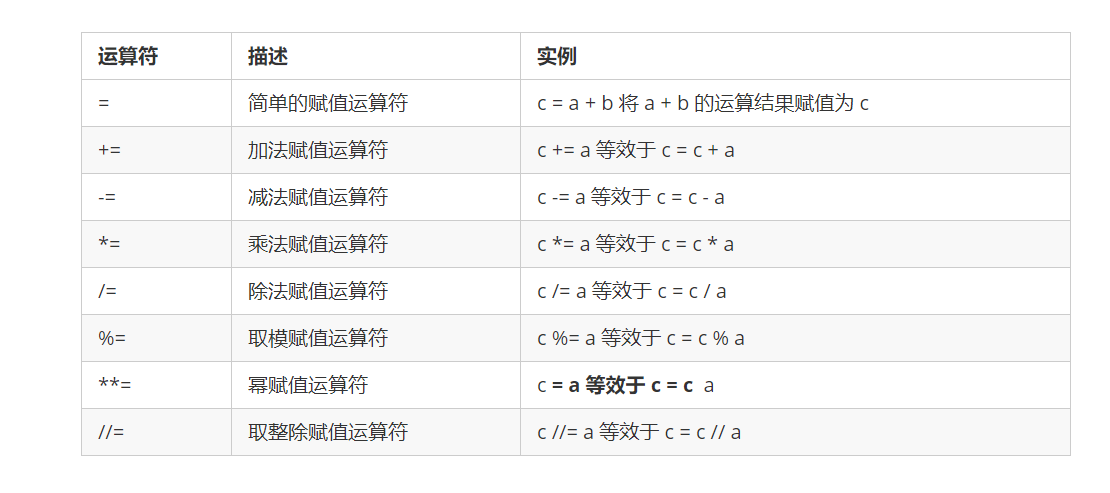
5. 运算符
-
算术运算符
-
比较(关系)运算符
-
赋值运算符
-
逻辑运算符
-
位运算符
-
成员运算符
-
身份运算符
-
运算符优先级
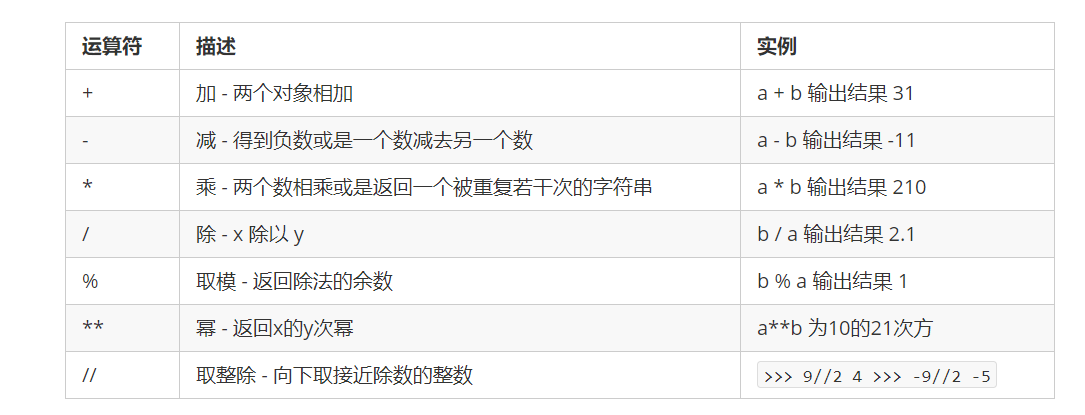
① 算术运算
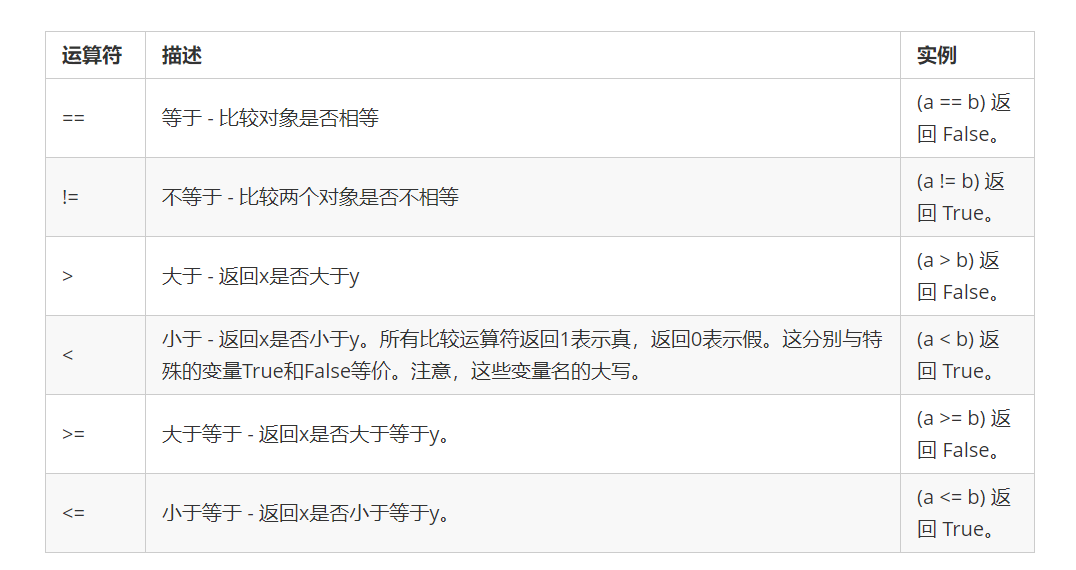
② 比较运算
③ 赋值运算
④ 逻辑运算符

⑤ 位运算符
Python中的按位运算法则如下:
下表中变量 a 为 60,b 为 13二进制格式如下:
a = 0011 1100
b = 0000 1101
-----------------
a&b = 0000 1100
a|b = 0011 1101
a^b = 0011 0001
~a = 1100 0011

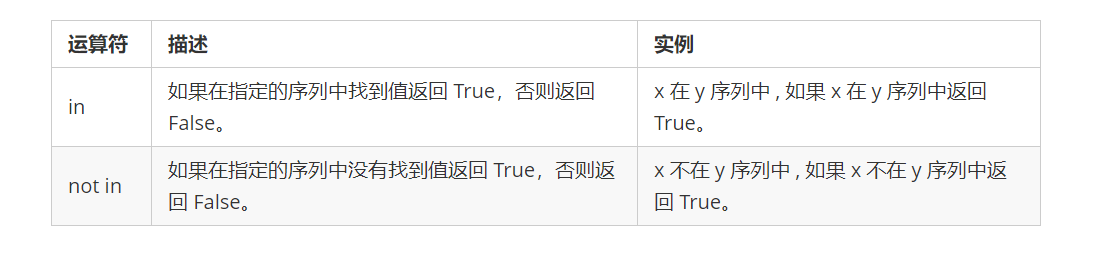
⑥ 成员运算符
测试实例中包含了一系列的成员,包括字符串,列表或元组。
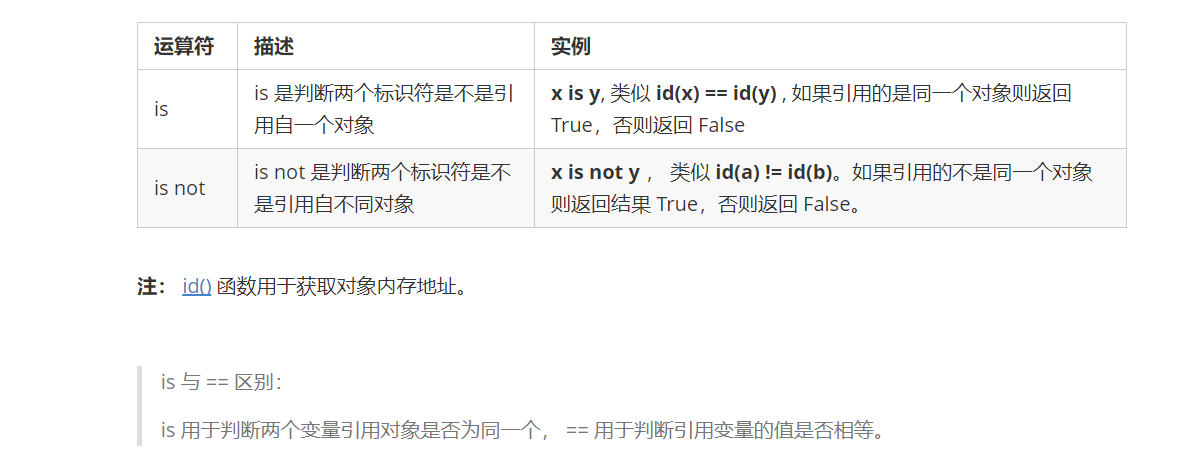
⑦ 身份运算符
身份运算符用于比较两个对象的存储单元
运算符优先级
从最高到最低优先级的所有运算符:

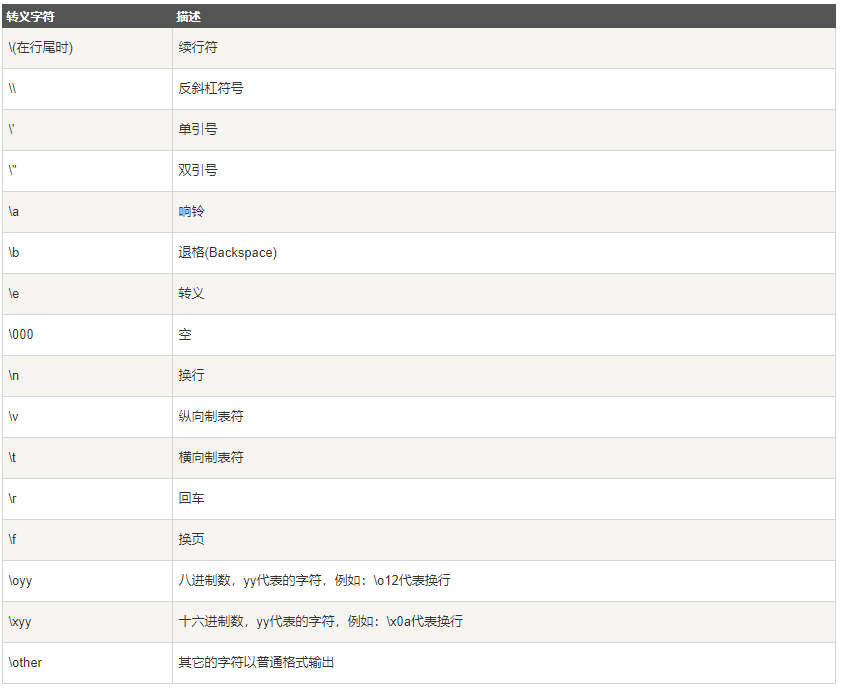
转义字符
6. 二进制| 进制拾遗
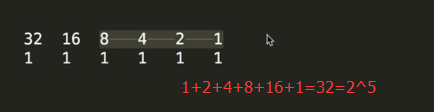
二进制(binary)在数学和数字电路中指以2为基数的记数系统,以2为基数代表系统是二进位制的。这一系统中,通常用两个不同的符号0(代表零)和1(代表一)来表示 [1] 。数字电子电路中,逻辑门的实
现直接应用了二进制,因此现代的计算机和依赖计算机的设备里都用到二进制。每个数字称为一个比特(Bit,Binary digit的缩写)
八进制、 十六进制
>>> oct(7)
'0o7'
>>> oct(8)
'0o10'
>>> oct(15)
'0o17'
>>> oct(16)
'0o20'
>>>
>>> oct(64)
'0o100'
>>> oct(63)
'0o77'
>>>
>>>
>>> hex(16)
'0x10'
>>> hex(31)
'0x1f'
>>> bin(144) ##144的二进制
'0b10010000'
>>>
>>> chr(97)
'a'
>>> bin(97)
'0b1100001'
>>> hex(97)
'0x61'
十进制转换为二进制
一个十进制整数转换为二进制数采用 "除2取余,逆序排列"法。
具体做法是:用2整除十进制整数,可以得到一个商和余数;再用2去除商,又会得到一个商和余数,如此进行,直到商为小于1时为止,然后把先得到的余数作为二进制数的低位有效位,后得到的余数作为二进制数的高位有效位,依次排列起来
例如 125 转为 二进制
125 / 2 = 62 余 1
62 / 2 = 31 余 0
31 / 2 = 15 余 1
15 / 2 = 7 余 1
7 / 2 = 3 余 1
3 / 2 = 1 余 1
1 / 2 = 0 余 1
余数从低位到高位依此排列: 1 1 1 1 1 0 1
二进制转换为十进制
方法:“按权展开求和”。
该方法的具体步骤是先将二迸制的数写成加权系数展开式,而后根据十进制的加法规则进行求和
例如:
# 1 1 1 1 1 0 1
1*2^6 + 1*2^5 + 1*2^4 + 1*2^3 + 1*2^2 + 1*2^1 + 1*2^0 = 125
十六进制与二进制的转换
https://jingyan.baidu.com/album/47a29f24292608c0142399cb.html?picindex=1
7. ASCII码
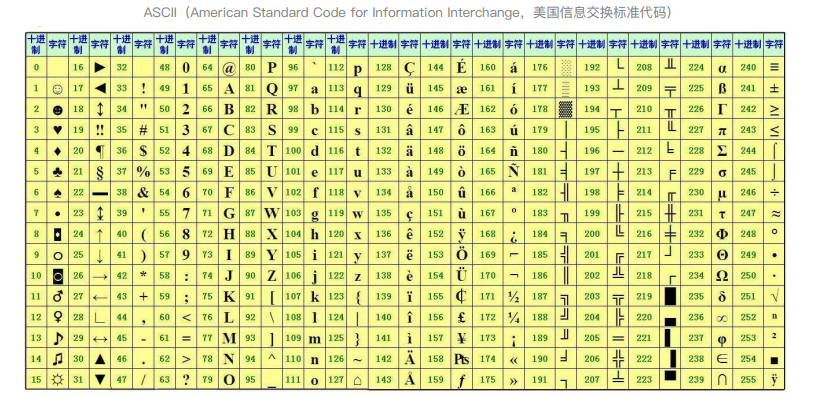
每一位0或者1所占的空间单位为bit(比特),这是计算机中最小的表示单位;
每8个bit组成一个字符,这是计算机中最小的存储单位。

8. 字符编码
GB2312----gbk---gb18030---Unicode---GTF-8
py2里默认ASCII码,如果想写中文,把默认编码改了 #! -*- coding: utf-8 -*- 或者 #! encoding:UTF-8 ;py3默认UTF-8
alex博客:http://www.cnblogs.com/alex3714/articles/7550940.html
- ASCII 占1个字节,只支持英文
- GB2312 占2个字节,支持6700+汉字
- GBK GB2312的升级版,支持21000+汉字
- Unicode 2-4字节 已经收录136690个字符,并还在一直不断扩张中...
为了解决存储和网络传输的问题,出现了Unicode Transformation Format,学术名UTF,即:对unicode中的进行转换,以便于在存储和网络传输时可以节省空间!
- UTF-8: 使用1、2、3、4个字节表示所有字符;优先使用1个字符、无法满足则使增加一个字节,最多4个字节。英文占1个字节、欧洲语系占2个、东亚占3个,其它及特殊字符占4个。 字符怎么传到硬盘上
无论以什么编码在内存里显示字符,存到硬盘上都是2进制。
字符编码的转换
Unicode的两个作用:包含所有国家的语言和跟所有国家的语言有一个对应关系。

unicode与gbk的映射表 http://www.unicode.org/charts/
python3代码执行流程
- 解释器找到代码文件,把代码字符串按文件头定义的编码加载到内存,转成unicode
- 把代码字符串按照语法规则进行解释,
- 所有的变量字符都会以unicode编码声明
编码转换
Py3 自动把文件编码转为unicode必定是调用了什么方法,这个方法就是,decode(解码) 和encode(编码)
UTF-8 --> decode 解码 --> Unicode
Unicode --> encode 编码 --> GBK / UTF-8 .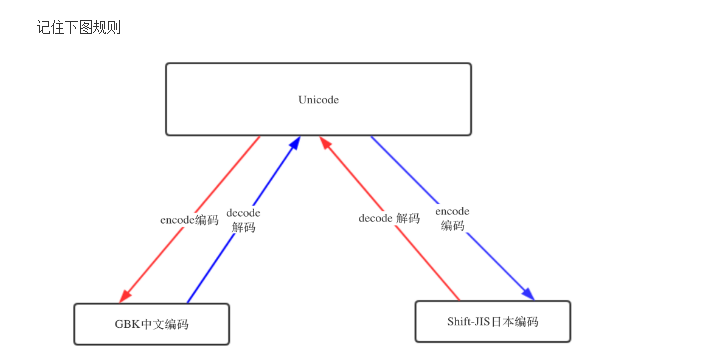
python的bytes类型
bytes类型,即字节类型, 它把8个二进制一组称为一个byte,用16进制来表示。python2的字符串其实更应该称为字节串。 通过存储方式就能看出来, 但python2里还有一个类型是bytes呀,难道又叫bytes又叫字符串? 嗯 ,是的,在python2里,bytes == str , 其实就是一回事。
python3比python2做了非常多的改进,其中一个就是终于把字符串变成了unicode,文件默认编码变成了utf-8,这意味着,只要用python3,无论你的程序是以哪种编码开发的,都可以在全球各国电脑上正常显示,真是太棒啦!
PY3 除了把字符串的编码改成了unicode, 还把str 和bytes 做了明确区分, str 就是unicode格式的字符, bytes就是单纯二进制啦。
为什么在py3里,把unicode编码后,字符串就变成了bytes格式? 你直接给我直接打印成gbk的字符展示不好么?我想其实py3的设计真是煞费苦心,就是想通过这样的方式明确的告诉你,想在py3里看字符,必须得是unicode编码,其它编码一律按bytes格式展示。
流程控制
Python条件语句是通过一条或多条语句的执行结果(True或者False)来决定执行的代码块。
Python代码的缩进规则:具有相同缩进的代码被视为代码块;
单分支
IF条件:
满足条件后要执行的代码。
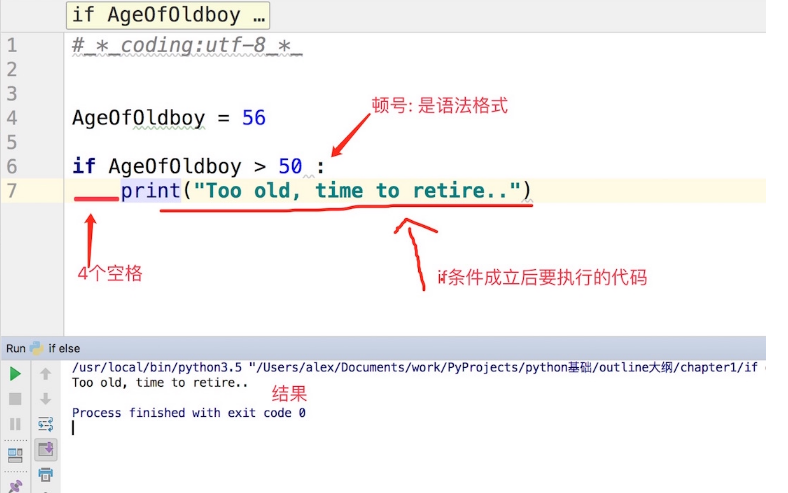
双分支
if 条件: 满足条件执行代码 else: if条件不满足就走这段
# 两种条件判断:if-else flag = False name = 'luren' if name == 'python': # 判断变量否为'python' flag = True # 条件成立时设置标志为真 print( 'welcome boss') # 并输出欢迎信息 else: print(name) # 条件不成立时输出变量名称
多分支
回到流程控制上来,if...else ...可以有多个分支条件
if 条件:
满足条件执行代码
elif 条件:
上面的条件不满足就走这个
elif 条件:
上面的条件不满足就走这个
elif 条件:
上面的条件不满足就走这个
else:
上面所有的条件不满足就走这段
score = int(input("输入分数-->>:"))
if score > 100:
print("最高分数才100哦")
elif score > 90:
print("A")
elif score > 80:
print("B")
elif score > 60:
print("C")
elif score > 40:
print("D")
else:
print("E")
While循环
while 条件:
执行代码...count = 0
while count <= 100 : #只要count<=100就不断执行下面的代码
print("loop ", count )
count +=1 #每执行一次,就把count+1,要不然就变成死循环啦,因为count一直是0
如果我想实现打印1到100的偶数呢?
加上 if count % 2 == 0: #是偶数
死循环
while 是只要后边条件成立(也就是条件结果为真)就一直执行,怎么让条件一直成立呢?
count = 0
while True: #True本身就是真呀
print("你是风儿我是沙,缠缠绵绵到天涯...",count)
count +=1
循环终止语句
- break用于完全结束一个循环,跳出循环体执行循环后面的语句
- continue和break有点类似,区别在于continue只是终止本次循环,接着还执行后面的循环,break则完全终止循环
- pass是空语句,是为了保持程序结构的完整性((不中断也不跳过))
while...else 语句
while 后面的else 作用是指,当while 循环正常执行完,中间没有被break 中止的话,就会执行else后面的语句
猜年龄游戏:age = 24
count = 0
while count < 3:
guess_age = int(input("your guess_age:"))
if guess_age == age:
print("恭喜抱得美人归")
break
else:
count += 1
age = 24
count = 0
while count < 3:
guess_age = int(input("your guess_age:"))
if guess_age == age:
print("恭喜抱得美人归")
break
elif guess_age > age:
print("猜小一点")
else:
print("try bigger")
count += 1
if count == 3:
choice = input("你个笨蛋,还想玩吗?(y|Y)")
if choice == "y"or choice == "Y":
count = 0
else:
break
练习
- 简述编译型与解释型语言的区别,且分别列出你知道的哪些语言属于编译型,哪些属于解释型 答:编译类:先翻译成二进制,产生两个文件,运行的时候是二进制文件。程序执行效率高,编译后程序运行时不需要重新翻译,直接使用编译的结果就可以了,但是跨平台性能差。如C\C++、Delphi等。
解释型:“同声翻译”,一边翻译成目标代码即机器语言一边执行,运行效率比较低且不能生成可独立执行的可执行文件,应用程序不能脱离解释器,这种方式比较灵活,可以动态调整、修改应用程序。可以跨平台,开发效率高。如:java、python等
- 执行 Python 脚本的两种方式是什么 答:一进入解释器的交互式模式:调试方便,无法永久保存代码;二脚本文件的方式(使用nodpad++演示):永久保存代码,但是不方便调试
- Pyhton 单行注释和多行注释分别用什么? 答:单行注释用#,多行注释用 ‘’’ '''
- 布尔值分别有什么? 答:布尔值有True 和False
- 声明变量注意事项有那些? 答:一数字、字母和下划线的组合;二是数字不能开头;三是以下关键字不能声明为变量名['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']。
- 如何查看变量在内存中的地址? 答:
id(变量名)#查看内存地址。 - 写代码
- 实现用户输入用户名和密码,当用户名为 seven 且 密码为 123 时,显示登陆成功,否则登陆失败!
_username = "seven" _passworld = "123" username = input("username:") passworld = input("passworld:") if username == _username and passworld == _passworld: print("登录成功") - 实现用户输入用户名和密码,当用户名为 seven 且 密码为 123 时,显示登陆成功,否则登陆失败,失败时允许重复输入三次

_username = "seven" _passworld = "123" count = 0 while count < 3: username = input("username:") passworld = input("passworld:") if username == _username and passworld == _passworld: print("登录成功") break else: print("登录失败,请重新输入") count += 1 - 实现用户输入用户名和密码,当用户名为 seven 或 alex 且 密码为 123 时,显示登陆成功,否则登陆失败,失败时允许重复输入三次
#_username = ["seven" , "alex"] #运用列表
_username = "seven" or "alex"
_passworld = "123"
count = 0
while count < 3:
username = input("username:")
passworld = input("passworld:")
if username == "seven" or "alex" and passworld == _passworld:
#if username in _username and passworld == _passworld: #判断
print("登录成功")
break
else:
print("登录失败,请重新输入")
count += 1
- 实现用户输入用户名和密码,当用户名为 seven 且 密码为 123 时,显示登陆成功,否则登陆失败!
-
写代码
a. 使用while循环实现输出2-3+4-5+6...+100 的和
i = 2 total_1 = 0 total_2 = 0 while i <=100: if i%2 == 0: total_1 += i else: total_2 += -i i += 1 total = total_1 + total_2 print(total)b. 使用 while 循环实现输出 1,2,3,4,5, 7,8,9, 11,12
count = 1 while count <= 12: if count == 10 or count==6: pass else: print("loop",count) count +=1c. 使用while 循环输出100-50,从大到小,如100,99,98...,到50时再从0循环输出到50,然后结束
i = 101 while i >= 51: i -=1 print(i) i = 0 while i <= 50: print(i) i +=1d. 使用 while 循环实现输出 1-100 内的所有奇数
i = 1 while i <= 100: if i %2==1: print(i) i+=1e. 使用 while 循环实现输出 1-100 内的所有偶数
i = 0 while i <= 100: if i %2==0: print(i) i+=1 -
现有如下两个变量,请简述 n1 和 n2 是什么关系?
n1 = 123456 n2 = n1 关系是给数据123456起了另外一个别名n2,相当于n1和n2都指向该数据的内存地址 给数据 123456 起了另外一个别名n2,相当于n1和n2都指向该数据的内存地址 -
制作趣味模板程序(编程题)
需求:等待用户输入名字、地点、爱好,根据用户的名字和爱好进行任意显示
如:敬爱可爱的xxx,最喜欢在xxx地方干xxxusername = input("name:") place = input("place:") love = input("love:") info = ''' 敬爱的%s最喜欢在 %s干 %s '''% (username,place,love) print(info) -
输入一年份,判断该年份是否是闰年并输出结果。(编程题)
注:凡符合下面两个条件之一的年份是闰年。 (1) 能被4整除但不能被100整除。 (2) 能被400整除。year = int(input("please input a year:")) if (year %2==0 and year %100!=0) or (year %400==0): print(year,"是闰年") else: print(year,"不是闰年") -
假设一年期定期利率为3.25%,计算一下需要过多少年,一万元的一年定期存款连本带息能翻番?(编程题)
money = 10000 year = 0 while money <= 20000: year +=1 money = money * (1+0.0325) print(year,money) print(year,"年以后,一万元的一年定期存款连本带息能翻番")



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人